第三章 数据库结构设计
Posted shaoyayu
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了第三章 数据库结构设计相关的知识,希望对你有一定的参考价值。
第三章 、数据库结构设计
1、掌握数据库概念设计
2、掌握数据库逻辑设计
3、掌握数据库物理设计
(选择题、设计与应用题)
第一节、数据库的概念设计
一个良好的数据库,在很大程度上决定了系统的成功与否。
一般分为:数据库概念设计、数据库逻辑设计、数据库物理设计
概念设计是数据库设计的核心环节。通常对用户需求进行综合、归纳与抽象,形成一个独立具体DBMS的概念模型。
1、数据库概念设计目标
- 定义和描述应用领域设计数据范围
- 获取信息模型
- 描述数据属性特征
- 描述数据之间的关系
- 定义和描述数据的约束
- 说明数据的安全性要求
- 支持用户的各种数据处理需求
- 保证信息模型能转化成数据库的逻辑结构(即数据库模式)
2、概念设计的依据及过程
- 依据
数据库概念设计以需求分析的结果为依据,即需求说明书、DFD图以及在需求阶段收集的应用领域中的各类报表等。
- 结果
概念设计的结果是概念模型(ER)与概念设计说明书。
- 过程
- 明确建模目标(模型覆盖范围)
- 定义实体集(自底向上标识和定义实体集)
- 定义联系(实体之间的联系)
- 建立信息模型(构建ER模型)
- 确定实体属性(属性描述一个实体的特征或性质)
- 对信息模型进行集成与优化(检查和消除命名不一致、结构不一致等)
概念设计是DB设计的核心环节,概念数据模型是对现实世界的抽象模拟
3、概念模型设计
- 概念设计目前采用最广泛的是ER建模方法。将现实世界抽象为具有属性的实体及联系
1976年,Peter.Chen提出E-R模型(Entity Relationship Model),即实体联系模型,用E-R图来描述数据库的概念模型。
观点:世界是由一组称作实体的基本对象之间的联系构成的。
3.1、与E-R模型有关的概念
- 实体(Entity)或实例(Instance)
客观存在并可相互区分的事物叫做实体。
- 实体集(Entity Set)
同型实体的集和称为实体集。如全体学生、
- 属性(Attribute)
实体所具有的某一特性。一个实体可以由若干个属性来刻画,每个属性的取值范围称为“域”
例如:学生可以由学号、姓名、年龄、系部等属性组成。
- 码(Key) 【键】
实体集中唯一标识每一个实体的属性或属性组合。
用来区别同一个实体集中不同实体的属性称为“主码”,【主键】
一个实体集中任意两个实体存在主码上取值不能相同,例如:学生的学号,公民的身份证号码
- 联系(Relationship)
描述实体之间的相互关系,如学生与老师之间的授课关系
联系也可以有属性,如学生与课程之间有选课联系,每个选课联系都有一个成绩作为其属性
通类联系的集和称为“联系集”
- 实体之间的联系有三种
实体之间的联系数量,即一个实体通过一个联系集能与另一个实体集相关联的实体数目。
一对一联系【1:1】
一对多联系【1:n】
多对多联系【n:n】
- E-R模型的表示:
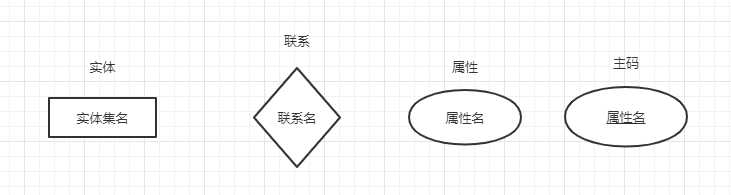
【主码下面的属性名有下划线】
4、IDEF1X建模方法
- IDEF1x与第二章介绍的IDEF0是一系列的建模工具,
- IDEF0是功能建模方法
- IDEF1X是数据建模方法
5、概念设计
1、建立目标
2、定义实体集
3、定义联系
4、定义联系
5、建立信息模型
6、确定实体属性
7、对信息模型进行集成与优化
第二节、 数据库的逻辑设计
1、逻辑设计的任务:
将概念模型【E-R图】转化为DBMS支持的数据模型(如关系模型),并对其进行优化
2、路径设计的依据和阶段目标
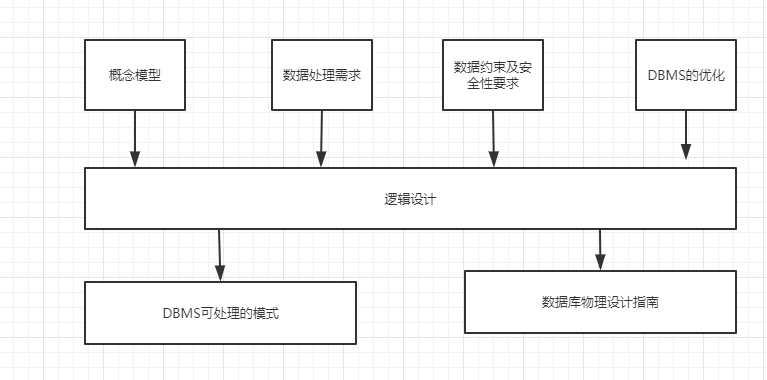
注:把DBMS的优化改成DBMS的信息
3、相关概念
- 关系模型
- 数据依赖
- 候选码、主码、外码
- 数据规范化
- 范式
3.1、关系模型
有三种主要的数据模型:层次模型、网状模型、关系模型。其中的关系模型简单灵活,并坚实的理论基础,已成为当前最流行的数据模型。
关系模型就是用二维表格结构来表示实体及实体之间联系的模型。
关系的描述称为关系模型(Relation Scheme)。关系模式由五部分组成,即它是一个五元组:R(U,D,DOM,F)
R:关系名,
U:组成该关系的属性名集和,
D:属性U中属性来自的域
DOM:属性到域的映射
F:属性组成U上的一组数据依赖
由于D、DOM对模式设计关系不大,这里把关系模式简化为一个三元组:
R<U,F>,当且仅当U上的一个关系R满足F时候,R称为关系模式R<U,F>的一个关系。
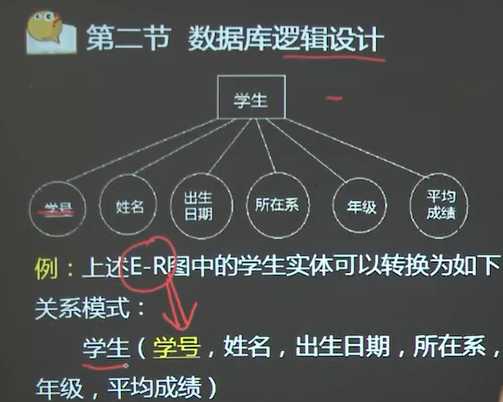
1、关系数据库设计的核心:关系模式的设计
2、关系模式的设计目标:按照一定的原则从数量众多而又相互关联的数据中,构建出一组既能较好地反映现实世界,而又有良好的操作性能的关系模式。
新奥尔良法,数据库设计步骤:
需求分析-->>概念结构设计[E-R图]-->>逻辑结构设计[关系模式设计]--->>物理结构设计
3.2、有关的概念
- 数据依赖
定义:设R(U)是一个属性集U上的关系模式,X和Y是U的子集,若对于R(U)的任意一个可能关系r,r中不能存在两个元组在x上的属性值相等,而在Y上的属性值不等,则称“X函数确定Y”或“Y函数依赖于X”,记作x->Y
关系内部属性之间的一种约束关系,是现实世界属性间相互联系的抽象,数据的内在性质,语义的体现。
完整性约束的表现形式:
限定属性的取值范围,如年龄<60,
定义属性间的相互关联(主要体现于值相等与否),这就是依赖
- 数据依赖的类型
函数依赖(functional dependency,FD)
普遍存在生活中,这种依赖关系类似于数学中的函数y=f(x),自变量x确定后,相应的函数值y也就唯一地确定了。
如关系:公民(身份证号,姓名,地址,工作单位)
身份证号--确定,则其地址就唯一确定,因此地址依赖身份证号
而姓名--确定,不一定能确定地址。
多值依赖(Multivalued Dependency,MD)
函数就是唯一确定的关系,多值依赖不能唯一确定
3.3、函数依赖的几种特例
1、平凡函数依赖与非平凡函数依赖
如果x->y,且y不是x的子集,则x-y称为非平凡函数依赖。
若y是x的子集,则称x->y为平凡函数依赖
由于y是x的子集时,一定有x->y,平凡函数依赖必然处理,没有意义,所以一般平凡函数依赖总是指非平凡函数依赖。
例题

2、完全函数依赖和部分函数依赖

3、传递函数依赖

/有些符号真滴难画,我就不写了/
例题

3.4、候选码、主码、外码
如果每个属性组的值能唯一确定整个元组的值,则称该属性为候选码或候选关键字。
例如:
(学号,姓名,性别,年龄)中,学号是关键字,(学号,姓名)姓名不是关键字,性别不是关键字。
候选码如果有多个,可以选其中一个做主码(Primary key)。
属性或属性组x不是关系模式R的码(既不是主码,又不是候选码),但x是另一个关系模式的码,则称x是R的外部码,也称外码(Foreign key)
3.5、数据规范化
关系数据库的设计主要是关系模式设计。关系模式设计的好坏直接影响到数据库设计的成败。讲关系模式规范化,是设计好的关系模式的唯一途径。
关系模式的规范化主要是由关系范式来完成。
关系模式的规范化:把一个低一级的关系模式分解为高一级关系模式的过程。
关系数据库的规范化理论是数据库逻辑设计的工具
目的是:尽量消除插入、删除异常、修改复杂、数据冗余的问题
- 范式
范式:关系模式满足的约束条件称为范式,根据满足规范化的程度不同,范式由低到高分别为:
1NF,2NF,3NF,4NF,5NF,
1NF:如果关系模式R,其所有属性都是不可分的基本数据项,则称R属于第一范式,R属于1NF。
例题

2NF:如果关系模式R属于1NF,且每个非主属性完全函数依赖主码,则称R属于第二范式
例题
判断R(学号,姓名,年龄,课程名称,成绩,学分)是否属于第二范式
主码:(学号,课程名称)
非主属性:姓名,年龄,成绩,学分,
存在如下决定关系:
(学号,课程名称)->(姓名,年龄,成绩,学分)
但是(课程名称)->(学分)
(学号)->(姓名,年龄)
3NF:如果关系模式R属于2NF,并且R中的某个非主属性不传递依赖于R的主码,则称关系R属于第三范式3NF
例题
判断R(学号,姓名,年龄,所在学院,学院地点,学号电话)是否属于第三范式?
主码:(学号)
非主码:姓名,年龄,所在学院,学院地点,学院电话。
存在非关键字段“学院地点”、“学院电话”对关键字段“学号”的传递函数依赖,
3NF要求实体的属性不能存在传递依赖,R不属于3NF.
关系模式规范化的基本步骤
消除决定属性集非码的非平凡函数依赖
1NF:消除非主属性对码的部分依赖
2NF:消除非主属性对码的传递依赖
3NF:消除主属性对码的部分和传递函数
BCNF
4NF:消除非平凡函数依赖的多值依赖
例题:






4、数据库逻辑设计的方法
4.1、设计逻辑结构的三部曲:
- 将概念结构转化为一般的关系模型
- 将转化的关系模型向特定DBMS支持下的数据模型转换
- 对数据模型进行优化
如果是关系型数据库管理系统,就应将概念模型转换为关系模型,即E-R图中的实体和联系转换为关系模型。
4.2、数据库逻辑建模的产生
概念模型按一定规则可以转换成数据模型。这种转换原则如下
- 1、一个实体转换成一个关系模式
- 2、一个1:1联系可以转换为一个独立的关系模式。也可以与任意一段对于关系模式合并。
- 3、一个1:n联系可以转换为一个独立的关系模式。也可以与N端对于的关系模式合并。
- 4、一个m:n联系转换为一个关系模型
- 5、三个或者三个以上实体的一个多元联系转换为一个关系模式
- 6、同一个实体集的实体间的联系,也可以按1:1、1:n和m:n三种情况分别处理。
第三节、数据库物理设计
1、物理设计概述
物理数据库设计是设计数据库的存储结构和物理实现方法。
目的:将数据的逻辑描述转换为实现技术规范,设计数据存储方案,以便提供足够好的性能并确保数据库数据的完整性、安全性、可靠性。
2、数据的物理结构
物理设备上的存储结构与存取方法称为数据库的物理设计,
数据库中的数据以文件形式存储在外设存储的介质上。
一个文件在物理上可看作是存放记录的一系列磁盘块组成,成为物理文件。
数据库的物理结构需要解决的如下问题:
文件组织、文件结构、文件存取、索引技术。
3、索引
索引(index)是数据库中独立的存储结构,其作用是提供一种无须扫描每个页面(存储表格数据的物理块)而快速访问数据页的方案,索引技术(indexing)是一种快速数据访问的技术。
索引技术的关键:建立记录域取值(如图书术语)到记录的物理地址(如页码)间的映射关系,即索引。
索引能提高性能,但是有代价的。(内存,时间,维护)
设计和创建索引时,应确保对性能的提高程度大于在存储空间和处理资源方面的代价。

3.1、索引的分类
- 有序索引:
索引文件机制,利用索引文件(索引记录做成)实现记录域(查找码,排序域)取值到记录物理地址间的映射关系。
数据文件(主文件)和索引文件(索引记录或索引项的集和)是有序索引技术中的两个主体,数据文件常采用顺序文件结构。
几种重要的有序索引:
1、聚集索引(索引项与数据记录排序一致,索引顺序文件)和非聚集索引,但可建立多个非聚集索引。
2、稠密索引(数据文件中每个查找码都对于索引记录)和稀疏索引(部分查找码的值对应索引记录)。
3、主索引(主码属性集上建立索引)与辅索引(非主属性上建立索引)。
4、唯一索引(索引列不包含重复值)
5、单层索引(线性索引,每个索引项顺序排列直接指向文件中的数据记录)和多层索引(大数据量文件中的采用多层树形[B,B+数]索引快速定位)
- 散列索引:
哈希索引机制,利用散列函数实现记录域取值到记录物理地址间的直接映射关系。
4、目标
目标是得到存储空间占用少,数据访问效率高和维护代价低的数据库物理模式。数据库底层物理存储于存取,与DBS所依赖的硬件环境、操作系统和DBMS密切相关。目前绝大部分DBS都是关系型数据库系统。
4.1、环节
数据库物理设计主要的五个环节
4.1.1、数据库逻辑模式描述:
根据数据库逻辑结构信息设计目标DBMS可支持的关系表(这里称为基本表)的模式信息,这个过程称为数据库逻辑模式描述。
关系模式及其他视图转换成基本表和视图,利用完整性机制(如触发器)设计面向业务规则。
SQL Server采用T-SQL语言。
为基本表选择合适的文件结构(堆文件、顺序文件、聚集文件、索引文件和散列文件)。
4.1.2、文件组织与存取设计
基本原则,根据应用情况将易变部分和稳定部分、存取频率较高部分和存取频率较低部分分开存放,以提高系统性能。
分析连接数据库事务访问特性:使用事务-基本表交叉引用矩阵;估计各事务执行频率;汇总每张表基本表各事务操作频率信息;根据结果设计文件结构。
可以考虑将表和索引分别放在不同的磁盘上,在查询的时,由两个磁盘驱动器分别在工作,因而可以保证物理读写速度比较快。
----我个人在这部分保持质疑,有时时间我参阅材料求证一下。
影响数据文件存储的因素:
- 存取时间
- 存储空间利用率
- 维护代价
这三个方面常常是相互矛盾的
解决办法:
- 适当冗余
- 增加聚簇功能
必须进行权衡,选择一个折中的方案
- 什么是存取路径
在关系数据库中,选择存取路劲主要指确定如何建立索引。
对同个关系要建立多条存取路径才能满足多个用户的多种应用要求
物理设计的第一个任务就是确定选择那些的存取方法。
DBMS常用的存取方法:
- 索引方法,目前主要是B+数索引方法(大数据),
- 聚簇方法( 在主键上建立索引)
- HASH方法(散列方式)
建立索引的原则:
- 一个(组)属性经常在操作条件中出现
- 一个(组)属性经常在连接操作的连接条件上
- 一个(组)属性经常作为聚集函数的参数
建立聚集索引(聚簇索引)原则
- 检索数据时,常以每个(组)属性作为排序,分组条件。
- 检索数据时,常以每个(组)属性作为检索限定条件,并返回大量数据
- 表中某个(组)的值重要性较大。
4.1.3、数据分布设计
- 不同类型数据的物理分布
将应用数据(基本表)、索引、日志、数据库备份数据等合理安排在不同的介质中。
- 应用数据的划分与分布
- 根据数据的使用特征划分(频繁使用分区和非频繁使用)
- 根据时间、地点(时间地点相同的属于同一部分)
- 分布式数据库系统(DDBS)中的数据划分(水平划分或垂直划分)
- 派生属性数据分布(增加派生列或不定义派生属性)
- 关系模式的去规范化(降低规范化提高查询效率)
- 水平划分
将基本表分为多张具有相同属性、结构完全相同的子表,子表包含的元组是基本表中的元组的子集
例如:对商品按照上平的生产年份进行划分就属于水平划分
- 垂直划分
将基本表划分为多张子表,每张子表包含的属性是基本表的子集。
例如:商品表(商品编号,品名,单价,库存量,销售单价,备注)
可以垂直划分为两张表
商品表(商品编号,品名,销售单价)
商品表(商品编号,单价,库存量,备注)
4.1.4、确定系统配置
- DBMS产品一般都提供了一些存储分配参数
同时使用数据库的用户数
同时打开数据库对象数
使用的缓冲区长度、个数
时间片大小
数据库的大小
填装因子
锁的数目......
4.1.5、物理模式评估
对数据库物理设计结果从存取时间、存储空间、维护代价等方面进行评估,重点是时间和空间的利用率。
如果评价结果满足原设计要求则可以进入物理实施阶段,否则,就需要重新设计或修改物理结构,有时甚至要返回逻辑阶段修改模型。
例题:
1、
SQL Service 中索引类型包括的两种类型分别是聚集索引和(散列索引)
2、

3、

D、存储及处理特征是物理阶段
4、

5、

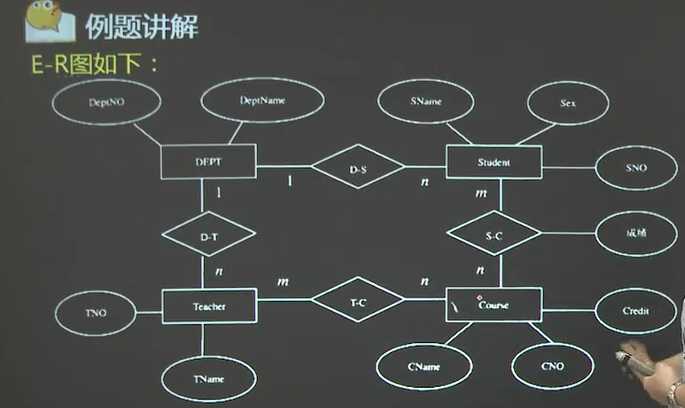
6、设计与应用题









以上是关于第三章 数据库结构设计的主要内容,如果未能解决你的问题,请参考以下文章