Word2Vec 计算词语之间的余弦相似度
Posted qi-yuan-008
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Word2Vec 计算词语之间的余弦相似度相关的知识,希望对你有一定的参考价值。
python中常用的分析文档、计算词语相似度的包 —— Word2Vec函数;该函数在gensim.models.Word2Vec包内。
分析文本和计算相似度有几个步骤:
导入需要用到的库:
# 导入第三包 import jieba import pandas as pd import gensim from collections import Counter import csv import time from tqdm import tqdm from progressbar import ProgressBar, Percentage, Bar, Timer, ETA, FileTransferSpeed import os
定义文件位置,包括数据集位置和自定义的词库位置:
first_dir = r‘D:Python_workspacespyder_space est数据集‘ #里面存放着一个或者多个相同结构的excel表格数据 file_list=os.listdir(first_dir) print(file_list) path_dir= r‘D:Python_workspacespyder_space‘ #存放着关键词文件、停用词文件
1. 前期分词准备(如果已分词并保存可以跳过):jieba分词,也可参考:https://www.cnblogs.com/qi-yuan-008/p/11689530.html
- 导入关键词库,是为了保证某些词不被切开,用于得到自己需要的词:
# 读入自定义词 with open(path_dir+r‘自定义关键词.txt‘, encoding=‘UTF-8‘) as words: #分词中想保留的关键词,要不然有可能会被切分开 my_words = [i.strip() for i in words.readlines()]
- 将关键词加入分词器:
# 将自定义词加入到jieba分词器中 for word in my_words: jieba.add_word(word)
- 导入停用词(用于去掉无意义或者不需要的词):
# 读入停止词 with open(path_dir+r‘自定义停用词.txt‘, encoding=‘UTF-8‘) as words: stop_words = [i.strip() for i in words.readlines()]
- 定义分词函数:
# 基于切词函数,构造自定义函数 def cut_word(sentence): words = [i for i in jieba.cut(sentence) if i not in stop_words and len(i)>1] # 切完的词用空格隔开 result = ‘ ‘.join(words) return result, words
2. 读入数据和分词: pd.read_excel,文件夹下多个文档或者单个文档
print(‘----------------- it is going to cut words ----------------‘) cut_result_list = [] cut_result_list_2 = [] out_words = ‘‘ num_rows = 0 for jj in file_list: #file_list是文件夹的文件列表,如果该文件夹下有一个或者多个相同结构的数据文档,可以用;如果只想单独分析一个大文档,可以去掉for循环,直接读入数据pd.read_excel即可 print(‘-------------- the file name is: ‘+jj) tmp_file = first_dir+‘‘+jj df = pd.read_excel(tmp_file) # 展示数据前5行 print(df.head()) sentences = df[‘content‘] for i in tqdm(range(len(sentences))): # tqdm 是进度条函数 num_rows += 1 word = sentences[i] word_str = str(word) #为了防止出现数字 word_str = word_str.strip() #去掉空格 word_str = word_str.upper() #英文统一成大写 # cut_words cut_result, words_list = cut_word(word_str) cut_result_list.extend(words_list) #保存所有的分词,用于词频统计 cut_result_list_2.append(words_list) #保存成可迭代变量,用于word2vec函数 out_words = out_words + cut_result + ‘ ‘ #连接所有的分词结果,用于写入文本 with open(first_dir+r‘jieba_分词.txt‘, "w",encoding=‘utf-8‘) as f: #将分词结果保存成外部数据集,进行导入操作 f.write(out_words) print(‘------------ all the rows is ‘+str(num_rows)+‘----------------‘)
3. 进行词频统计,获取前10的热词:
# 词频统计 c = Counter() for x in cut_result_list: if len(x) > 1: if x == ‘ ‘ or x == ‘ ‘ or x == ‘‘: continue else: c[x] += 1 print(‘常用词频度统计结果: ‘) out_words_2 = ‘‘ hotwords_list = [] for (kk, vv) in c.most_common(10): #保存前n为的热词 hotwords_list.append(kk) out_words_2 = out_words_2 + kk + ‘ ‘ + str(vv) + ‘ ‘ with open(first_dir+r‘热词词频.txt‘, "w",encoding=‘utf-8‘) as f: f.write(out_words_2)
4. 使用word2vec进行训练,得到词语的向量模型:min_count_num 参数是用于去掉词频小于该值的词语
print(‘----------------- it is going to do Word2Vec ----------------‘) min_count_num = 10 while min_count_num > vv: min_count_num = min_count_num//2
- 如果是采用以上保存的分词文件:jieba_分词.txt,则需要使用:gensim.models.word2vec.Text8Corpus()
sentences_vec=gensim.models.word2vec.Text8Corpus(first_dir+r‘jieba_分词.txt‘) #导入外部数据 model=gensim.models.Word2Vec(sentences, min_count=min_count_num, size=100, window=4, workers=4) #需要将分好的词导入数据使用,sentences必须是可迭代的数据
- 当然也可以直接用以上分词变量参数:cut_result_list_2 —— 是一个可迭代变量 list,直接使用:gensim.models.Word2Vec()
model=gensim.models.Word2Vec(cut_result_list_2, min_count=min_count_num, size=100, window=4, workers=4) #直接使用已分好的词,不进行导入数据操作
5. 保存模型和载入模型:一般在单个*.py计算时可以不用,因为可以直接计算就行,但是你保存的模型可以下次使用;model.save和gensim.models.Word2Vec.load
model.save(first_dir+r‘ est.model‘) #保存数据的vec模型 model = gensim.models.Word2Vec.load(first_dir+r‘ est.model‘) #导入模型,其中包含每个词及其对应的向量
6. 得到热词所对应的前5个相似度最高的词:
print(‘----------------- it is going to saving data ----------------‘) most_similar_list = [] total = len(hotwords_list) widgets = [‘Progress: ‘,Percentage(), ‘ ‘, Bar(‘=>‘),‘ ‘, Timer(), ‘ ‘, ETA(), ‘ ‘, FileTransferSpeed()] pbar = ProgressBar(widgets=widgets, maxval=10*total).start() #另一种形式的进度条 for i in range(total): tt = hotwords_list[i] tmp_list = [tt] print(‘=== 词库中距离“{}”的前5个最近的词是: ===‘.format(tt)) for ii in model.most_similar(tt, topn=5): #计算余弦距离最,得到最接近每个热词的前5个词 print(ii) #前面的是词汇,后面的是相似度值,即余弦距离值 tmp_list.append(ii[0]) most_similar_list.append(tmp_list) #第1列是该热词,后5列是与该词语的相似度值从高到低所对应的词语 pbar.update(10 * i + 1) pbar.finish()
7. 前两个词语的结果如下(余弦距离有负值,表示余弦相似度):
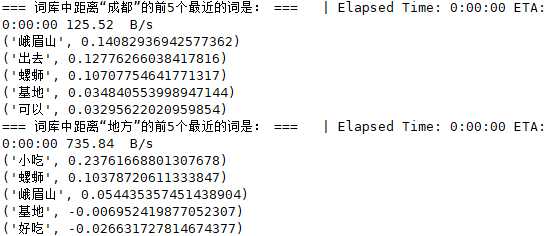
8. 对于此时的模型参数,有一些方法可以使用:
# 计算与一个词最相似的前多少个词:
model.most_similar("哈哈哈",topn=10) #计算与该 词最近似的词,topn指定排名前n的词
# 计算两个词的相似度:
model.similarity("word1","word2")
# 获取某个词对应的词向量,前提是词库里面有这个词,否则会报错
model [‘成都‘]
# 返回建立的model模型里面所包含的词语:
print(model.wv.index2word)

# 找出不属于同一类的词:
print(model.doesnt_match("好吃 小吃 不错 成都".split())) #结果是 ‘成都‘,当然这些词都必须在model词库里面
# 追加训练:
model.train(more_sentences_list) #追加训练
附加:常用参数解释:model=gensim.models.Word2Vec(cut_result_list_2, min_count=min_count_num, size=10, window=4, workers=4)
# min_count,是去除小于min_count的单词 # size,神经网络层数,也表示用多少维度的向量来表示一个词语 # sg, 算法选择 # window, 句子中当前词与目标词之间的最大距离 # workers,线程数
参考:
https://www.cnblogs.com/n2meetu/p/8124267.html
https://www.cnblogs.com/pinard/p/7278324.html
https://blog.csdn.net/qq_19707521/article/details/79169826
https://blog.csdn.net/leo_95/article/details/93008210
以上是关于Word2Vec 计算词语之间的余弦相似度的主要内容,如果未能解决你的问题,请参考以下文章