如何度量两个词之间的语义相似度
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何度量两个词之间的语义相似度相关的知识,希望对你有一定的参考价值。
如何度量句子的语义相似度,很容易想到的是向量空间模型(VSM)和编辑距离的方法,比如A:“我爸是李刚”,B:“我儿子是李刚”,利用VSM方法A(我,爸,是,李刚)B(我,儿子,是,李刚),计算两个向量的夹角余弦值,不赘述;编辑距离就更好说了将“爸”,“儿子”分别替换掉,D(A,B)= replace_cost;这是两种相当呆的方法,属于baseline中的baseline,换两个例子看一下就知道A:“楼房如何建造?”,B:“高尔夫球怎么打?”,C:“房子怎么盖?”,如果用VSM算很明显由于B,C中有共同的词“怎么”,所以BC相似度高于AC;编辑距离同理;
解决这种问题方法也不难,只要通过同义词词典对所有句子进行扩展,“如何”、“怎么”,“楼房”、“房子”都是同义词或者近义词,扩展后再算vsm或者edit distance对这一问题即可正解。这种方法一定程度上解决了召回率低的问题,但是扩展后引入噪声在所难免,尤其若原句中含有多义词时。例如:“打酱油”、“打毛衣”。在汉字中有些单字词表达了相当多的意义,在董振东先生的知网(hownet)中对这种类型汉字有很好的语义关系解释,通过hownet中词语到义元的树状结构可以对对词语粒度的形似度进行度量。
问题到这里似乎得到了不错的解答,但实际中远远不够。VSM的方法把句子中的词语看做相互独立的特征,忽略了句子序列关系、位置关系对句子语义的影响;Edit Distance考虑了句子中词语顺序关系,但是这种关系是机械的置换、移动、删除、添加,实际中每个词语表达了不同的信息量,同样的词语在不同词语组合中包含的信息量或者说表达的语义信息大不相同。What about 句法分析,计算句法树的相似度?这个比前两种方法更靠谱些,因为句法树很好的描述了词语在句子中的地位。实际效果要待实验证实。
对了,还有一种方法translation model,IBM在机器翻译领域的一大创举,需要有大量的语料库进行训练才能得到理想的翻译结果。当然包括中间词语对齐结果,如果能够利用web资源建立一个高质量的语料库对两两相似句对通过EM迭代词语对齐,由词语对齐生成句子相似度,这个。。想想还是不错的方法! 参考技术A 作为自然语言理解的一项基础工作,词语语义相似度度量一直是研究的重点。语义相似度度量本身是一个中间任务,它是大多数自然语言处理任务中一个必不可少的中间层次,在自然语言处理中有着广泛的应用,如词义消歧、信息检索以及机器翻译等。 本文的核心内容是汉语词语语义相似度算法研究以及如何将其应用于跨语言信息检索(Cross-Language Information Retrieval, CLIR)领域。首先对语义相似度度量算法进行综述,然后重点描述基于HowNet的语义相似度度量算法,提出根据知识词典描述语言(Knowledge Dictionary Mark-up Language, KDML)的结构特性将词语语义相似度分为三部分进行计算,每部分采用最大匹配的算法,同时加入义原深度信息以区别对待不同信息含量的义原。较以往同类算法,其计算结果具有区分度,更加符合人的主观感觉。 本文尝试将所建立的汉语语义相似度度量模式应用于跨语言信息检索系统。跨语言信息检索结合传统文本信息检索技术和机器翻译技术,在多方面涉及到语义问题,是语义相似度良好的切入点。两者的结合主要体现在两方面:(1)将语义相似度度量应用于查询翻译,利用语义相似度对查询关键词进行消歧翻译,提高翻译质量;(2)将语义相似度应用于查询扩展,使扩展内容与原查询具有更高相关性,以提高检索的召回率和准确率。 本文提出相对客观的评价标准,如为单独衡量词义消歧的性能,而使用第三届词义消歧系统评价会议(The 3rd Evaluating Word Sense Disambiguation Systems, SENSEVAL-3)语料进行测试;为衡量应用语义相似度于跨语言检索后的性能,又使用第九届文本检索会议(The 9th Text Retrieval Conference, TREC-9) CLIR评价任务的查询集、语料库和结果集进行评估。这使得我们的实验结果相对公正客观,具有一定可比性。本文对原有英汉跨语言信息检索系统进行一定程度的改进,使得各种相关算法都可方便地在系统中进行集成,成为一个研究跨语言信息检索的实验平台,其系统的设计思想充分体现模块化和扩展性。 综上,本文通过综合分析主流的语义相似度算法,而提出一种新的基于HowNet的汉语语义相似度算法,并给出其在英汉跨语言信息检索中的尝试性应用,希望能给相关领域的研究者有所借鉴。本回答被提问者和网友采纳
Java之词义相似度计算(语义识别词语情感趋势词林相似度拼音相似度概念相似度字面相似度)
Java之词义相似度计算(语义识别、词语情感趋势、词林相似度、拼音相似度、概念相似度、字面相似度)
工具类下载地址:
https://download.csdn.net/download/qq_44757034/85765530

1、词语相似度计算
public class BaseDemo
public static void main(String[] args)
System.out.println("首次编译运行...");
double result = Similarity.cilinSimilarity("电动车","自行车");
System.out.println(result);

2、 短语相似度值
public class PhraseSimilarityDemo
public static void main(String[] args)
String phrase1 = "继续努力";
String phrase2 = "持续发展";
double result = Similarity.phraseSimilarity(phrase1, phrase2);
System.out.println(phrase1 + " vs " + phrase2 + " 短语相似度值:" + result);

3、 词形词序句子相似度值、优化的编辑距离句子相似度值、标准编辑距离句子相似度值、gregeor编辑距离句子相似度值
/**
* @author itbluebox
*/
public class SentenceSimilarityDemo
public static void main(String[] args)
String sentence1 = "老师办理教师资格证";
String sentence2 = "监理工程师资格证书";//"电脑病毒是有害的吗";
double morphoSimilarityResult = Similarity.morphoSimilarity(sentence1, sentence2);
double editDistanceResult = Similarity.editDistanceSimilarity(sentence1, sentence2);
double standEditDistanceResult = Similarity.standardEditDistanceSimilarity(sentence1,sentence2);
double gregeorEditDistanceResult = Similarity.gregorEditDistanceSimilarity(sentence1,sentence2);
System.out.println(sentence1 + " vs " + sentence2 + " 词形词序句子相似度值:" + morphoSimilarityResult);
System.out.println(sentence1 + " vs " + sentence2 + " 优化的编辑距离句子相似度值:" + editDistanceResult);
System.out.println(sentence1 + " vs " + sentence2 + " 标准编辑距离句子相似度值:" + standEditDistanceResult);
System.out.println(sentence1 + " vs " + sentence2 + " gregeor编辑距离句子相似度值:" + gregeorEditDistanceResult);

4、词语情感趋势值
/**
* @author itbluebox
*/
public class TendencyDemo
public static void main(String[] args)
String word = "混蛋";
HownetWordTendency hownetWordTendency = new HownetWordTendency();
double result = hownetWordTendency.getTendency(word);
System.out.println(word + " 词语情感趋势值:" + result);

5、词林相似度值、拼音相似度值、概念相似度值、字面相似度值
/**
* @author itbluebox
*/
public class WordSimilarityDemo
public static void main(String[] args)
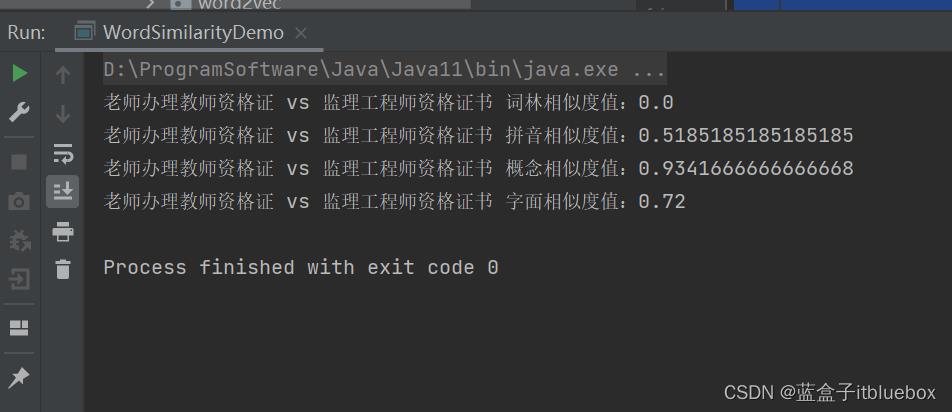
String word1 = "老师办理教师资格证";
String word2 = "监理工程师资格证书";
double cilinSimilarityResult = Similarity.cilinSimilarity(word1, word2);
double pinyinSimilarityResult = Similarity.pinyinSimilarity(word1, word2);
double conceptSimilarityResult = Similarity.conceptSimilarity(word1, word2);
double charBasedSimilarityResult = Similarity.charBasedSimilarity(word1, word2);
System.out.println(word1 + " vs " + word2 + " 词林相似度值:" + cilinSimilarityResult);
System.out.println(word1 + " vs " + word2 + " 拼音相似度值:" + pinyinSimilarityResult);
System.out.println(word1 + " vs " + word2 + " 概念相似度值:" + conceptSimilarityResult);
System.out.println(word1 + " vs " + word2 + " 字面相似度值:" + charBasedSimilarityResult);
以上是关于如何度量两个词之间的语义相似度的主要内容,如果未能解决你的问题,请参考以下文章
Java之词义相似度计算(语义识别词语情感趋势词林相似度拼音相似度概念相似度字面相似度)