学习日记(2.22-2.21 K-MEANS)
Posted eldq
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了学习日记(2.22-2.21 K-MEANS)相关的知识,希望对你有一定的参考价值。
K-means算法
K-means算法简介
k均值聚类算法(k-means clustering algorithm)是一种迭代求解的聚类分析算法,其步骤是,预将数据分为K组,则随机选取K个对象作为初始的聚类中心,然后计算每个对象与各个种子聚类中心之间的距离,把每个对象分配给距离它最近的聚类中心。聚类中心以及分配给它们的对象就代表一个聚类。每分配一个样本,聚类的聚类中心会根据聚类中现有的对象被重新计算。这个过程将不断重复直到满足某个终止条件。终止条件可以是没有(或最小数目)对象被重新分配给不同的聚类,没有(或最小数目)聚类中心再发生变化,误差平方和局部最小。
定义:
聚类是一个将数据集中在某些方面相似的数据成员进行分类组织的过程,聚类就是一种发现这种内在结构的技术,聚类技术经常被称为无监督学习。
k均值聚类是最著名的划分聚类算法,由于简洁和效率使得他成为所有聚类算法中最广泛使用的。给定一个数据点集合和需要的聚类数目k,k由用户指定,k均值算法根据某个距离函数反复把数据分入k个聚类中。(以上均来自于 百度百科)
算法分析:
以我个人的理解,K-means算法就是在一个大的样本里随机指定几个数据为聚类中心,然后在各个聚类中心的视角上,依次找到里该聚类中心最近的几个样本点,之后我们按照第一次分类找的点求出该聚类的几何中心,把几何中心作为聚类中心。经过了依次迭代我们发现聚类中心其实发生了改变,那几个样本归为一类也发生了改变,我们把这样的循环一直进行下去,直到聚类中心不发生偏移为止。在分类结束后,我们可以人工的给各个类别贴上标签,这个属于无监督学习是没有标签的。

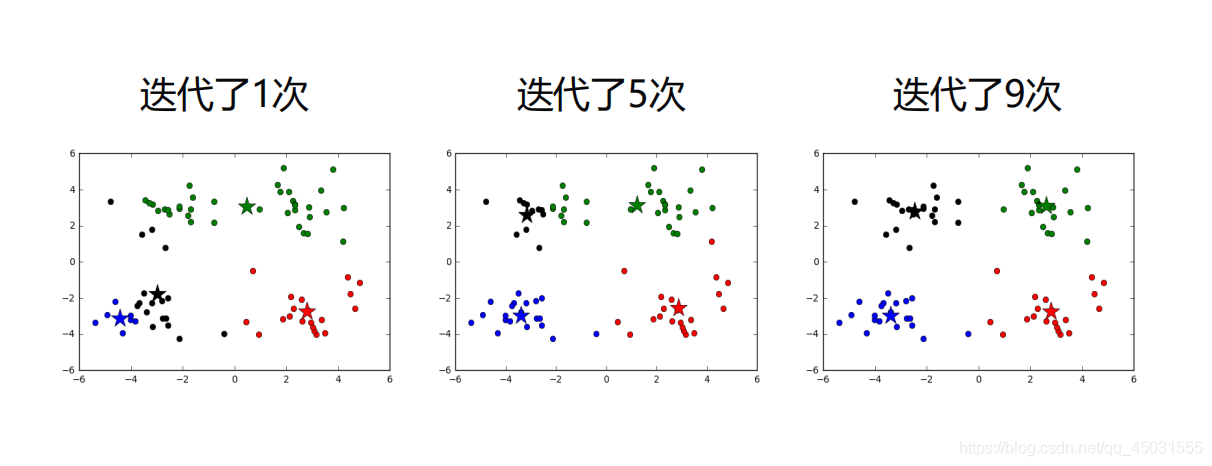
K-means算法用sklearn库实现:
from sklearn.cluster import KMeans
import numpy as np
import matplotlib.pyplot as plt
#载入数据
data=np.genfromtxt("E:python-mlkmeans.txt",delimiter=" ")
#设置K值
k=4
#训练模型
model=KMeans(n_clusters=k)
model.fit(data)
#分类中心点
centers=model.cluster_centers_
print('分类中心是:
',centers)
result=model.predict(data)
#一共有四个类别 0 , 1, 2 ,3 打印出来的就是按照顺序分类的结果
print(result)
#画出各个数据点,用不同的颜色标识分类s
mark=['or','ob','og','oy']
#这里是一个 enumberate 语法, i是下标,d是data中的每一个一维数组用来表示坐标
for i,d in enumerate(data):
#每一个坐标点的顺序下标在result里面是分类数字,然后把分类数字在mark里面换成颜色
plt.plot(d[0],d[1],mark[result[i]])
#画出中心
mark=['*r','*b','*g','*y']
for i,center in enumerate(centers):
#中心点就是4个,4个对应的分类颜色如上mark,这句话就是在一次打印出中心点,颜色安装mark规则,形状是 *,大小是20
plt.plot(center[0],center[1], mark[i], markersize=20)
plt.show()运行截图

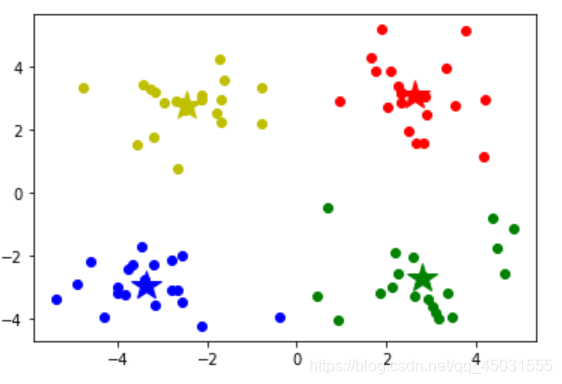
补充一下:
点击可以查看更多关于plt.plot的语法知识,我也是看了他的博客
Mini Batch K-Means算法
Mini Batch K-Means算法是K-Means算法的变种,采用小批
量的数据子集减小计算时间。这里所谓的小批量是指每次训练
算法时所随机抽取的数据子集,采用这些随机产生的子集进行
训练算法,大大减小了计算时间,结果一般只略差于标准算法。
该算法的迭代步骤有两步:
1:从数据集中随机抽取一些数据形成小批量,把他们分配给
最近的质心
2:更新质心
与K均值算法相比,数据的更新是在每一个小的样本集上。
Mini Batch K-Means比K-Means有更快的 收敛速度,但同时
也降低了聚类的效果,但是在实际项目中却表现得不明显。
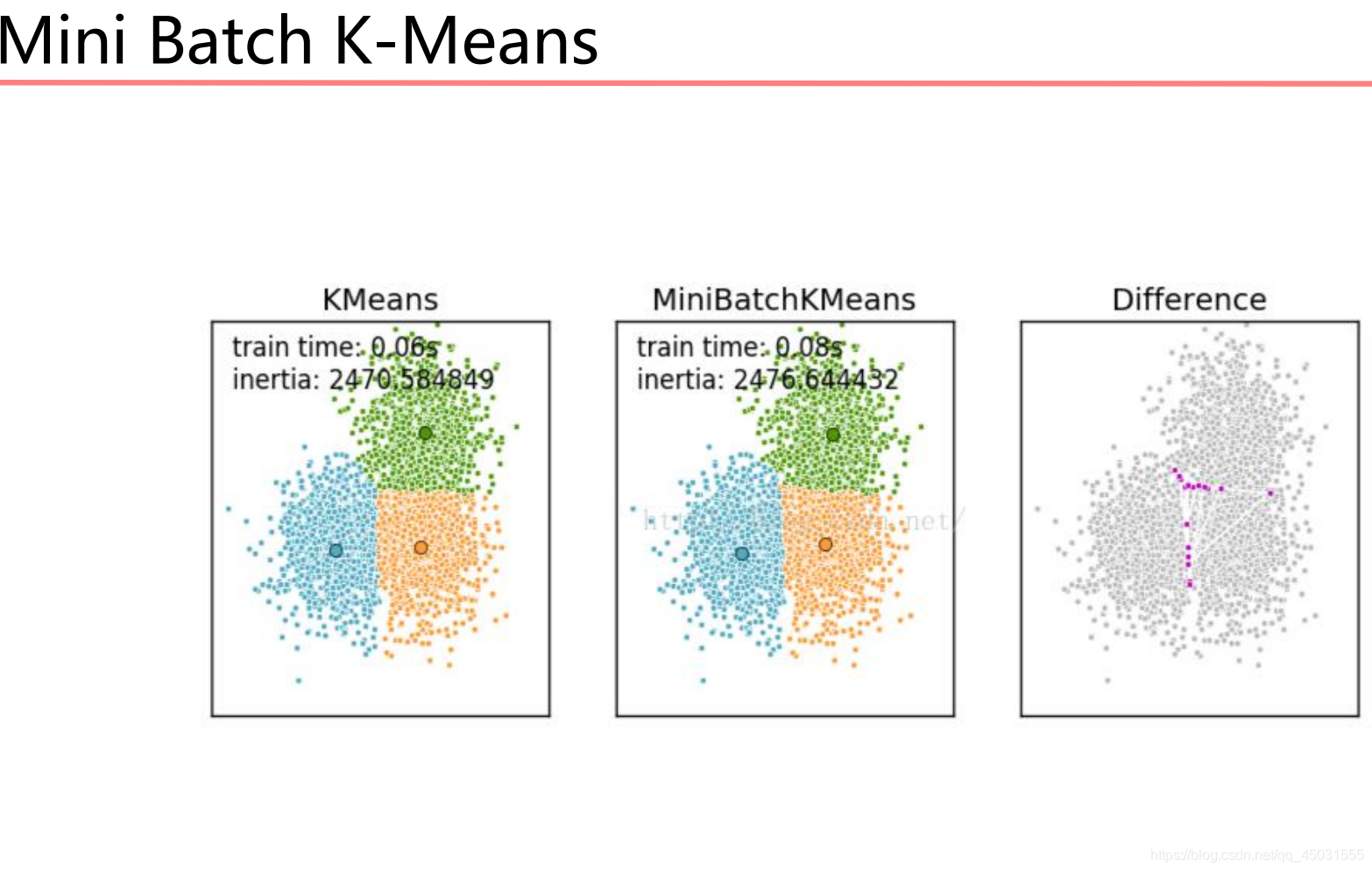
在分类边缘会出现一点小的瑕疵。
代码部分
和前面的 KMeans差不多,就是把前面的KMeans改成MiniBatchKMeans
from sklearn.cluster import MiniBatchKMeans
import numpy as np
import matplotlib.pyplot as plt
# 载入数据
data = np.genfromtxt("E:python-mlkmeans.txt", delimiter=" ")
# 设置k值
k = 4
# 训练模型
model = MiniBatchKMeans(n_clusters=k)
model.fit(data)
# 分类中心点坐标
centers = model.cluster_centers_
print('分类中心点坐标:')
print(centers)
# 预测结果
result = model.predict(data)
print('预测结果:')
print(result)
# 画出各个数据点,用不同颜色表示分类
mark = ['or', 'ob', 'og', 'oy']
for i,d in enumerate(data):
plt.plot(d[0], d[1], mark[result[i]])
# 画出各个分类的中心点
mark = ['*r', '*b', '*g', '*y']
for i,center in enumerate(centers):
plt.plot(center[0],center[1], mark[i], markersize=20)
plt.show()
KMeans算法存在的4个问题
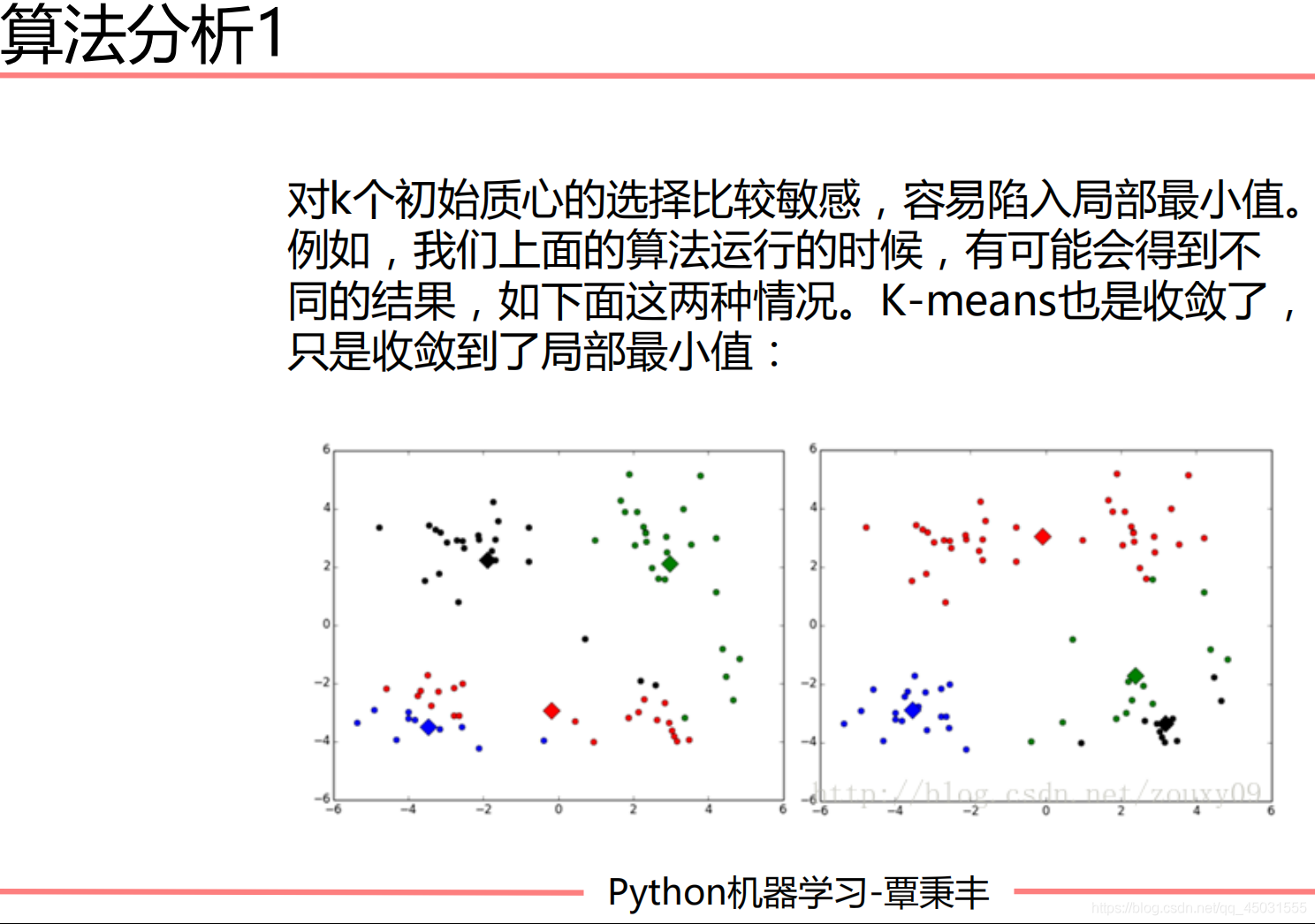
解决方法:

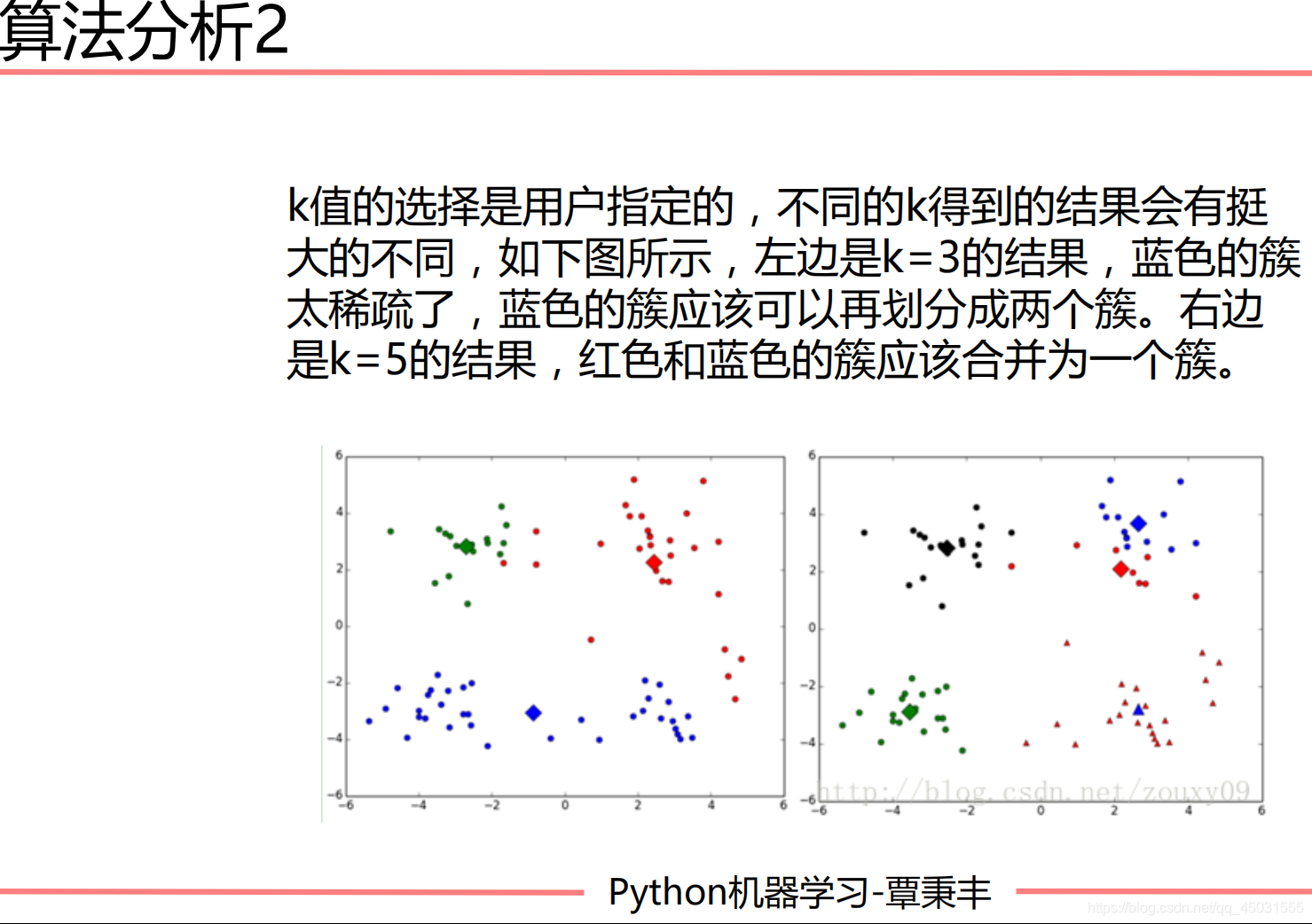
解决方法:
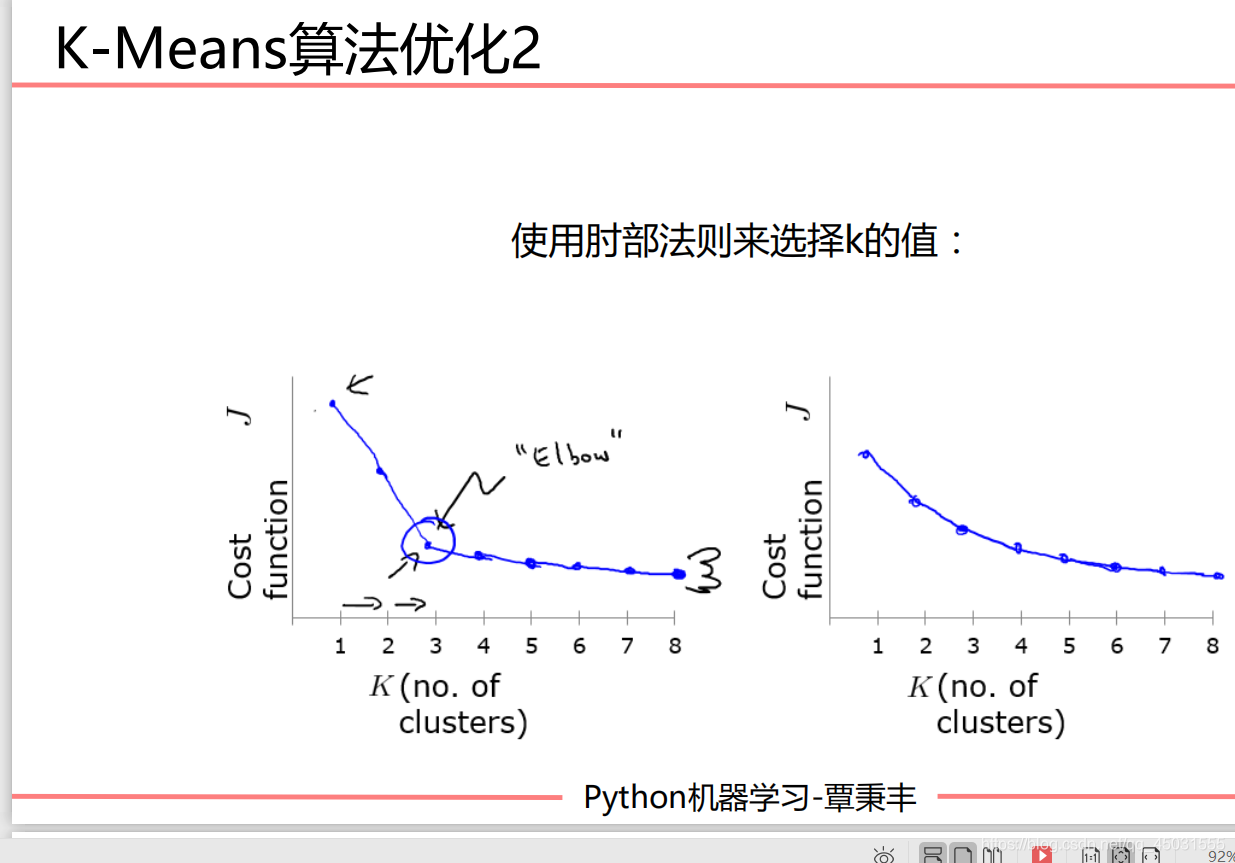
一般来说,画出Cost函数和K值选取的图像,这个图片就很像人的手臂,我们在手肘的部位选取K值一般是比较合适的。
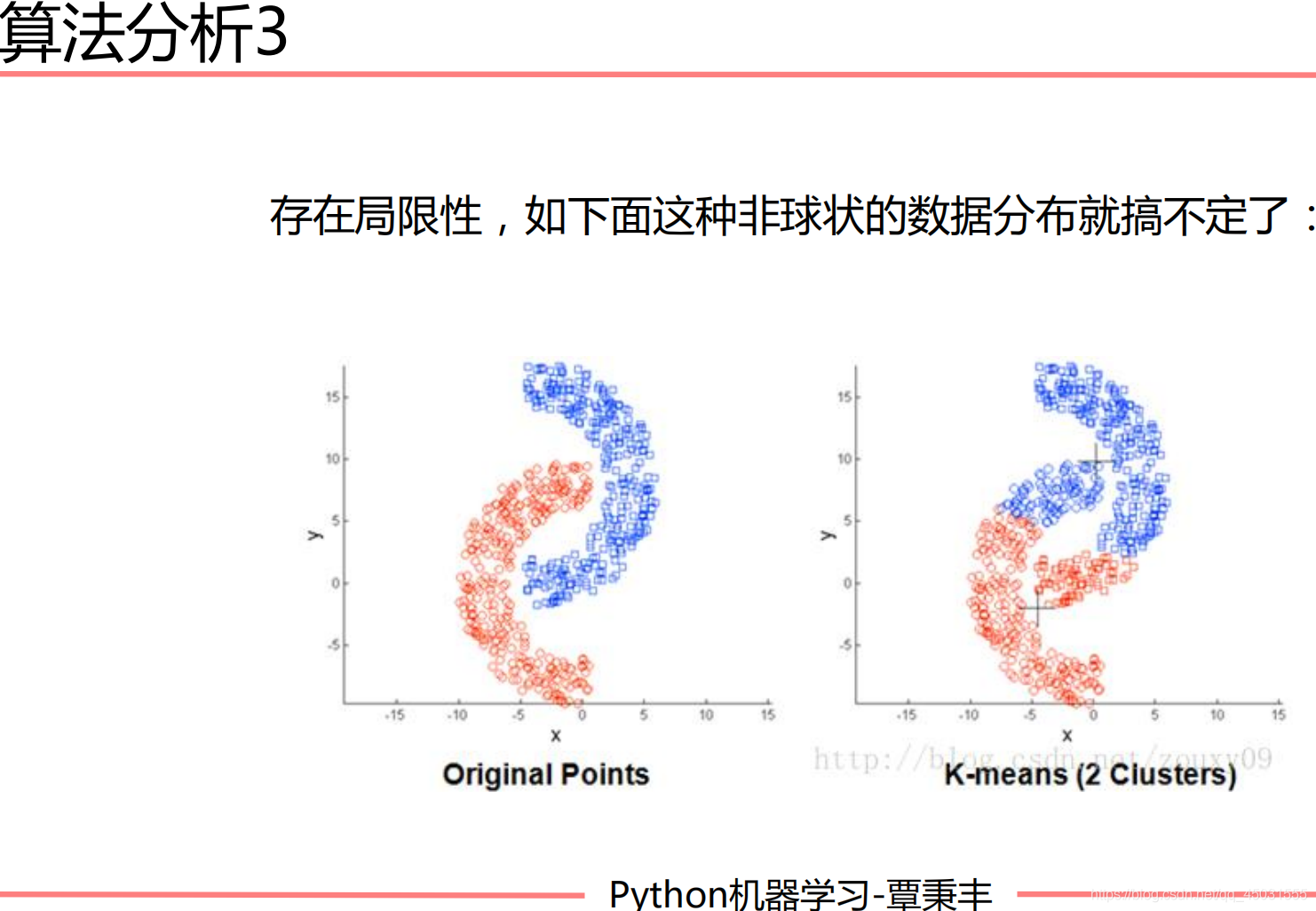
解决方案:数据可视化
可视化网址访问外网不成功。。。。有点卡你们要看的话就多等一会
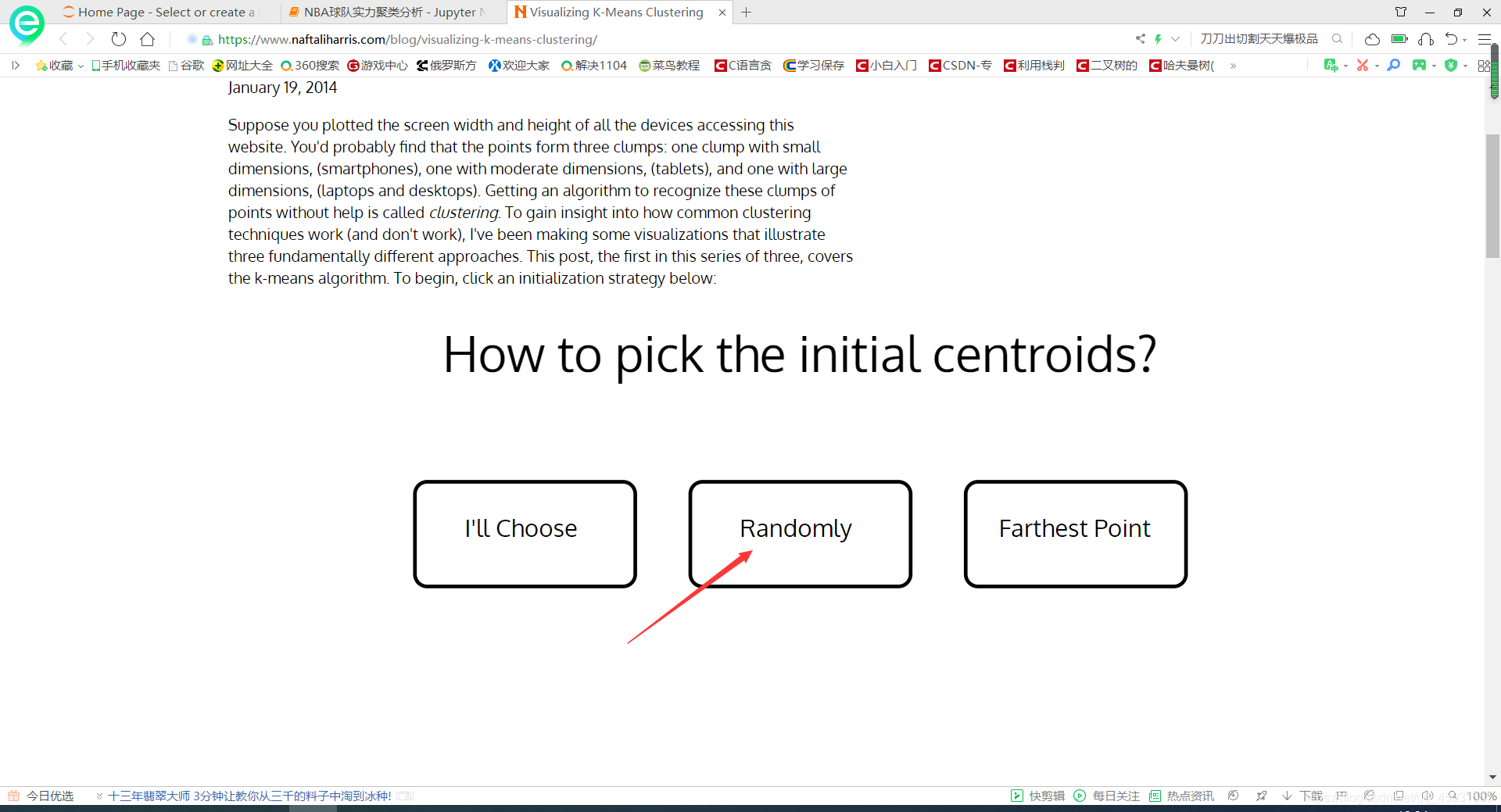
挑选你希望的数据类型
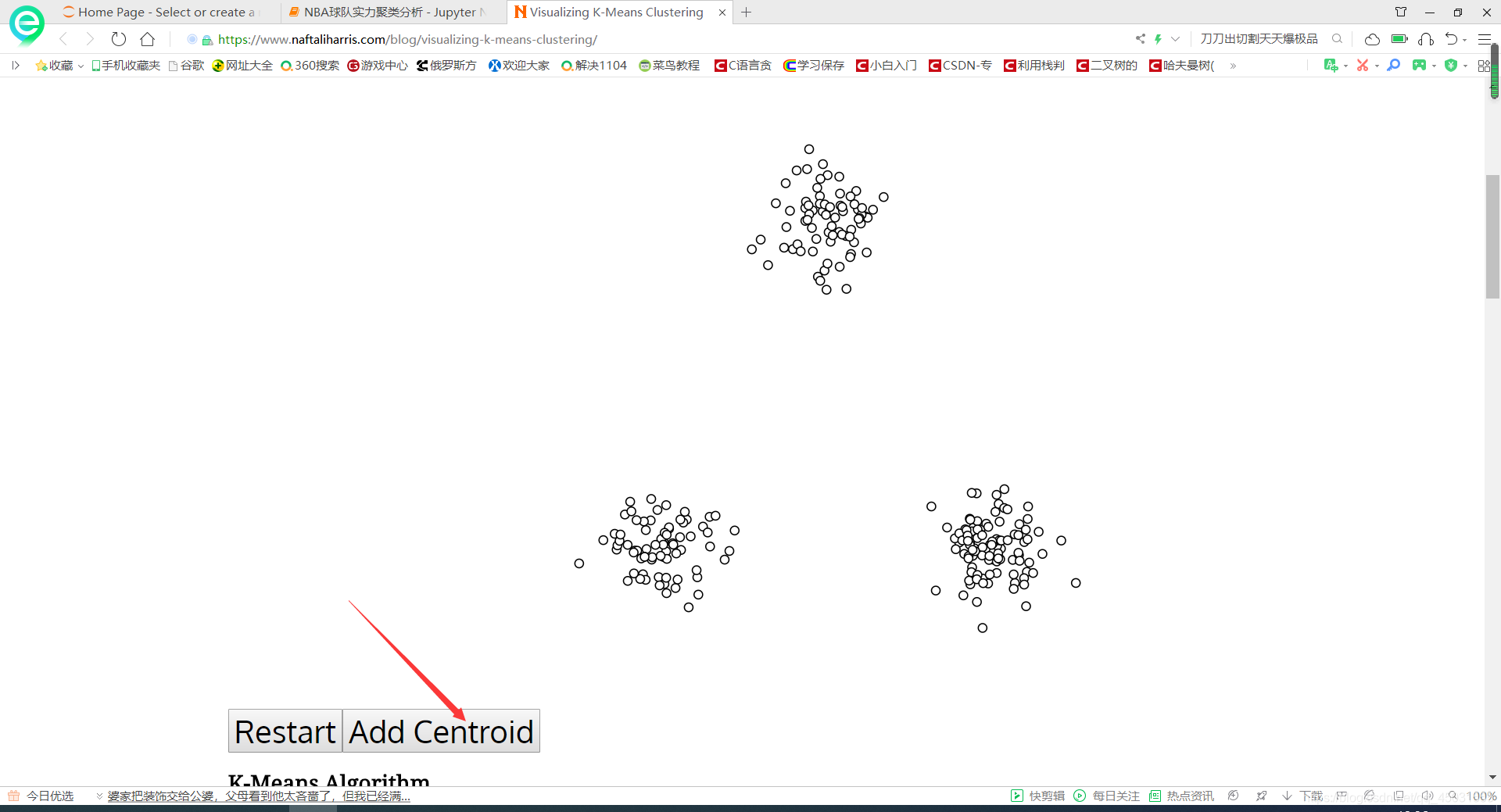
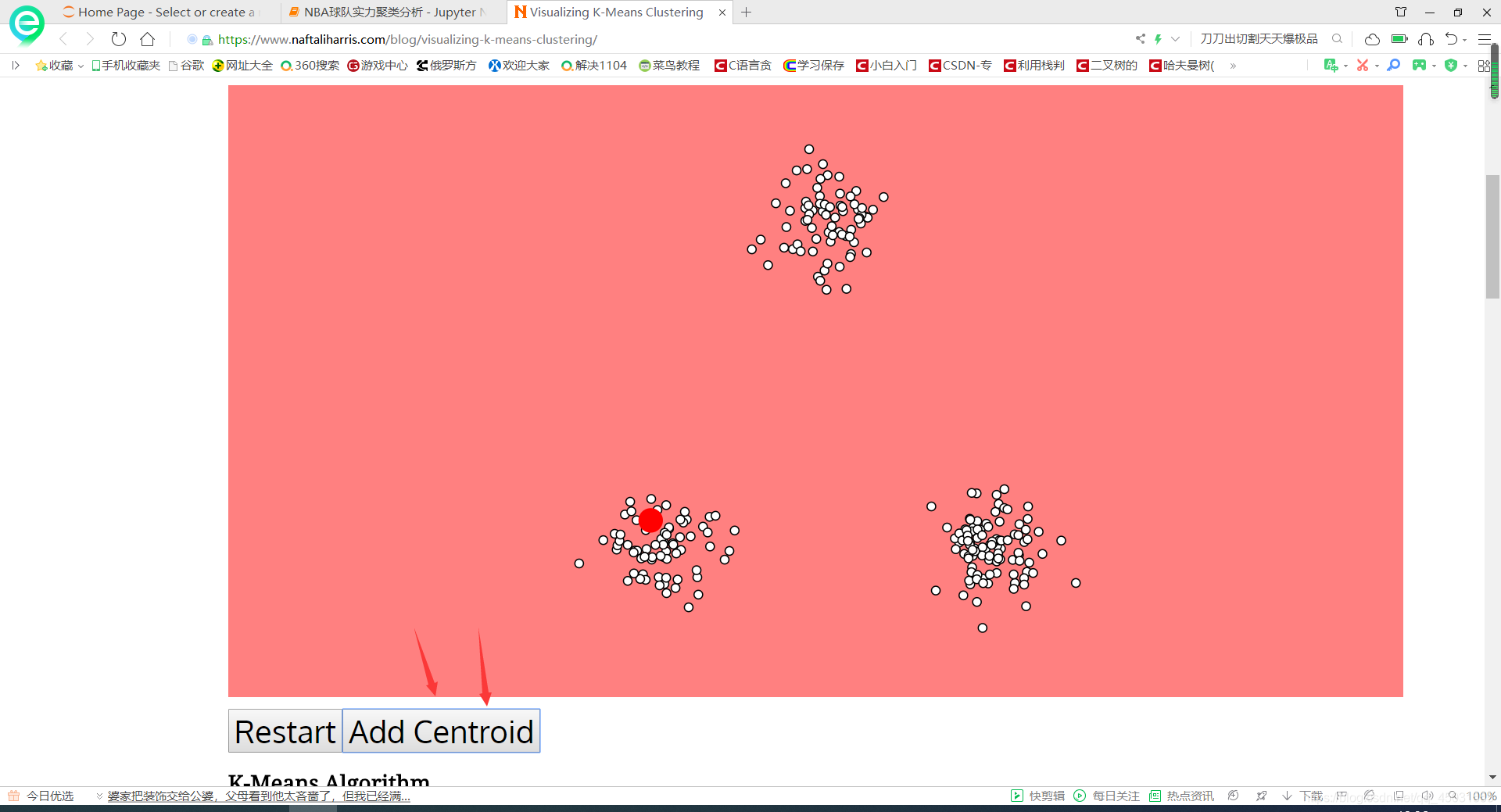
迭代就是一直点GO和UPDATE
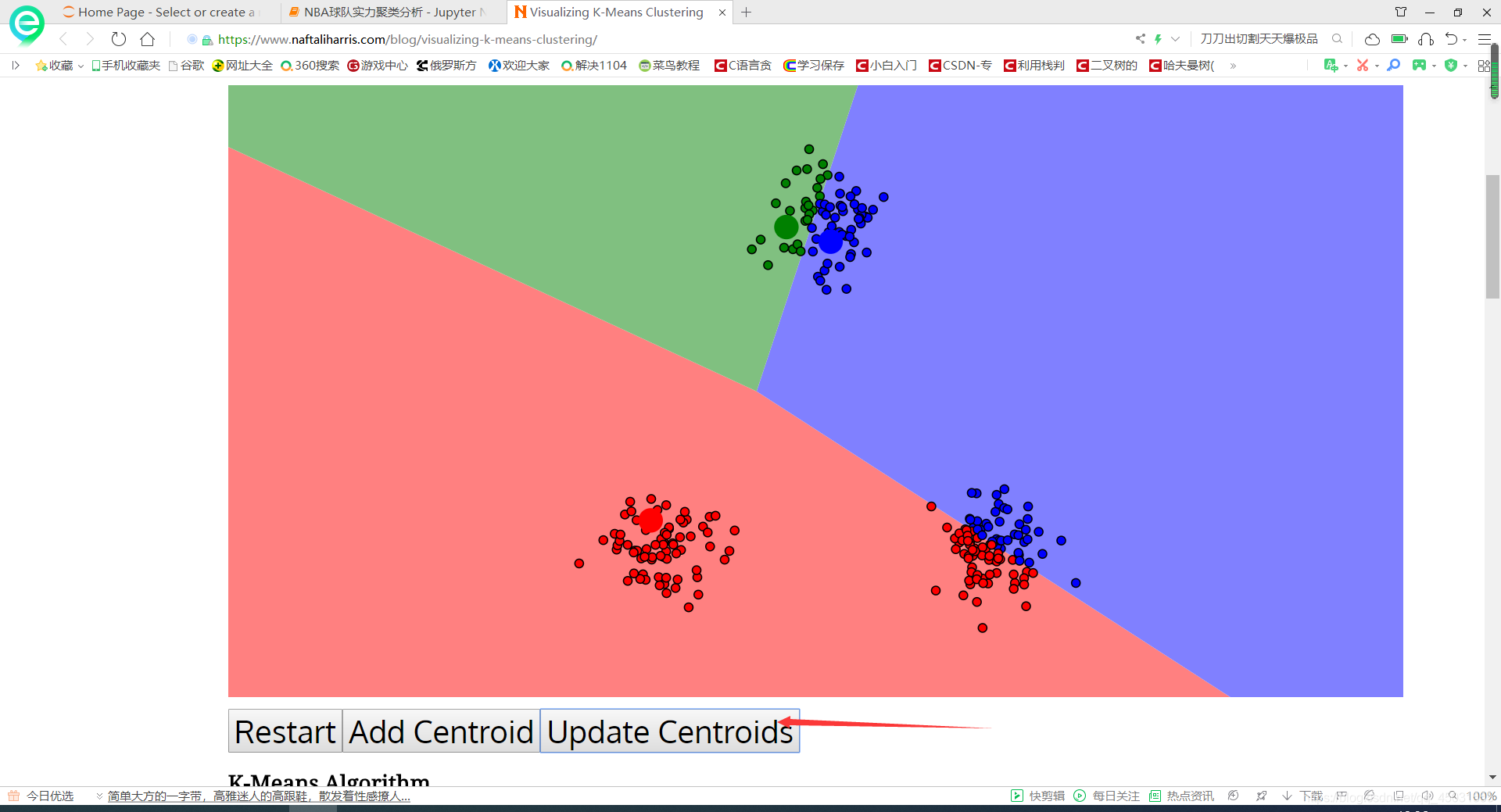
点到你感觉分类中心没有改变为止。
有一类这样的对称的图形实现不了分类:
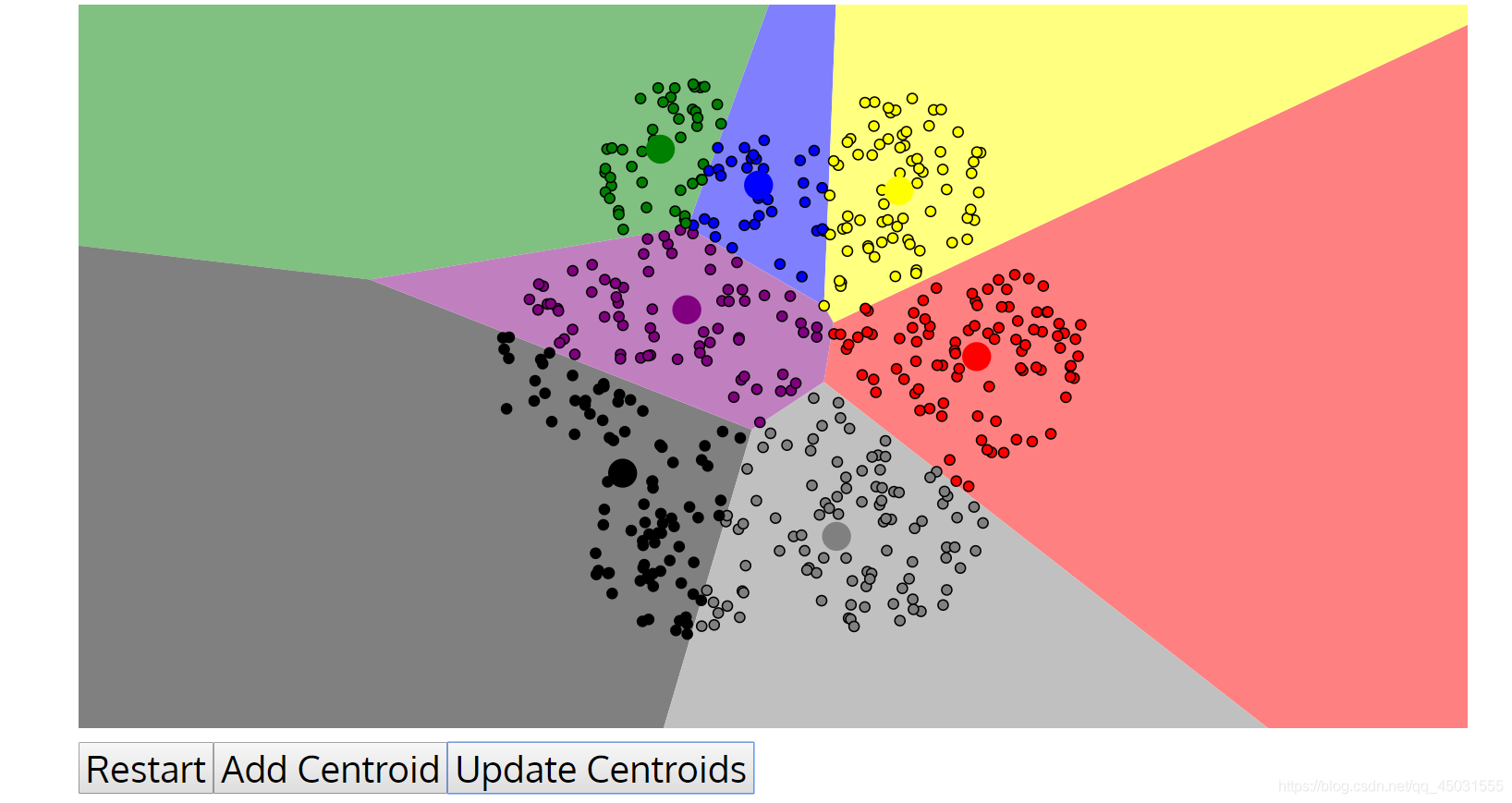
这样的对称的数据不适合用KMEANS,我们在使用之前其实也应该用数据可视化的方法来看一下数据是否适合我们的K-Means算法,不然会白忙活一场

K-Means实战:NBA球队实例分析
数据集展示:
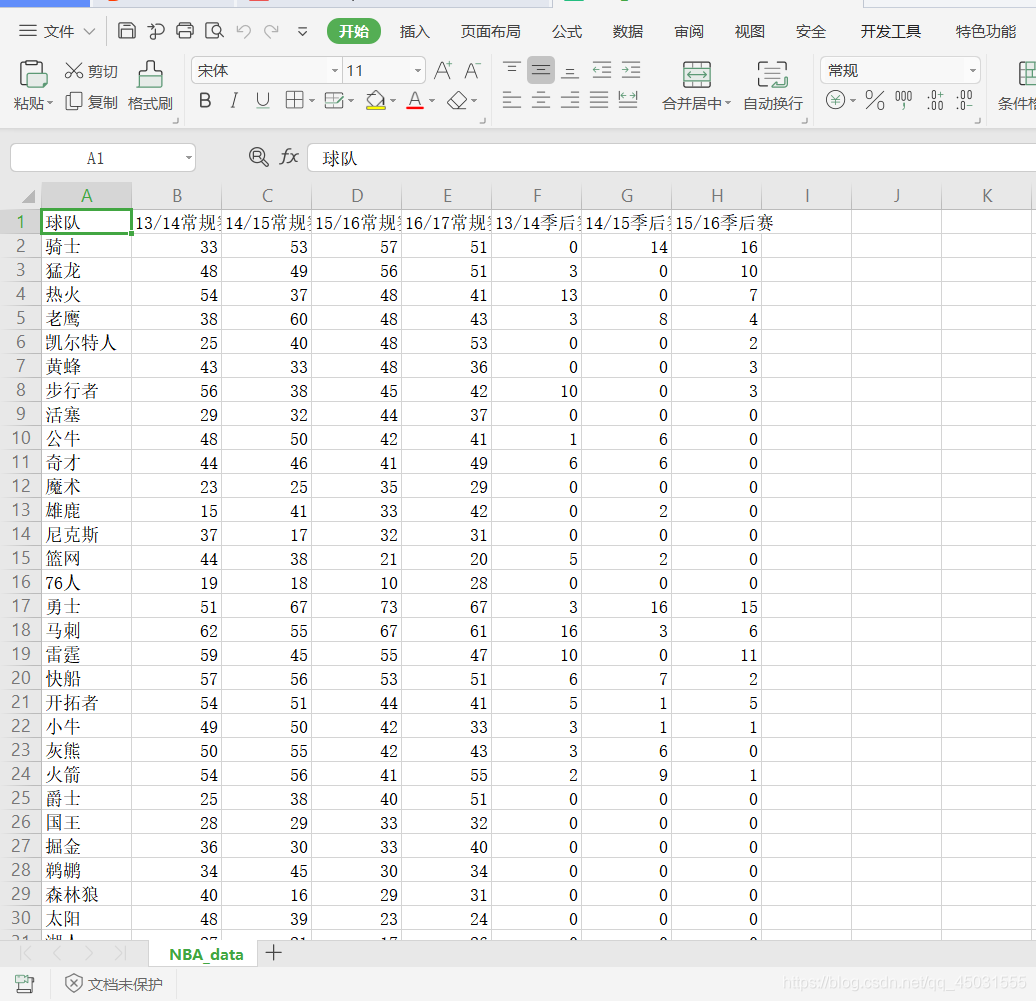
代码部分:
读取数据打印数据集,其中我遇到一个问题:读取文件的时候报错 SyntaxError: (unicode error) ‘unicodeescape‘ codec can‘t decode bytes in position 12-13: malformed N character escape
解决方案把这个文件手动上传到Jupter 上面,不用添加路径只需要文件名就直接读取了,不会报错。
from sklearn.cluster import KMeans
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
data = pd.read_csv('Nba_data.csv')
data.head()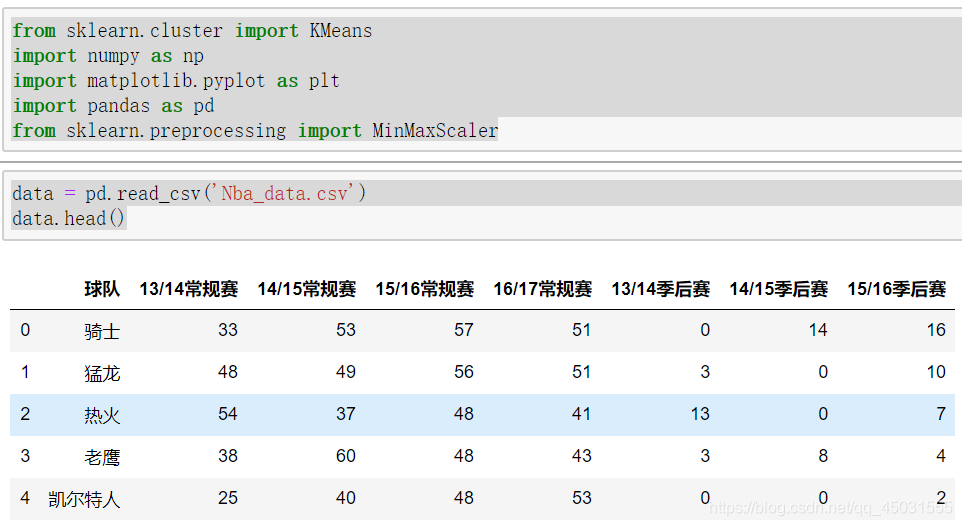
数据标准化:我前面的博客提到过,主要是方便计算,又可以保存数据特征
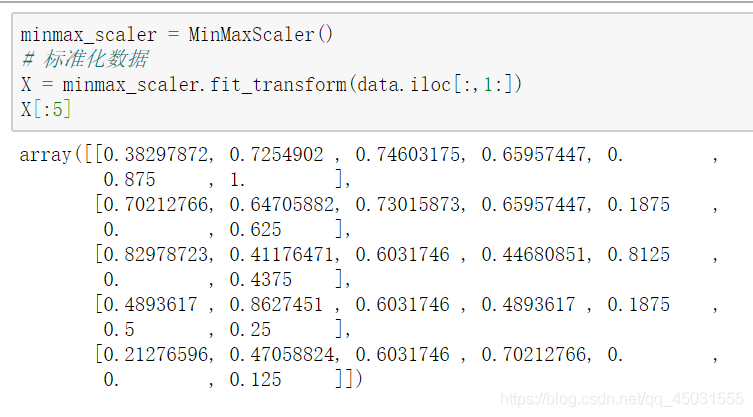
肘部法则:我们就判断 4为肘部好了
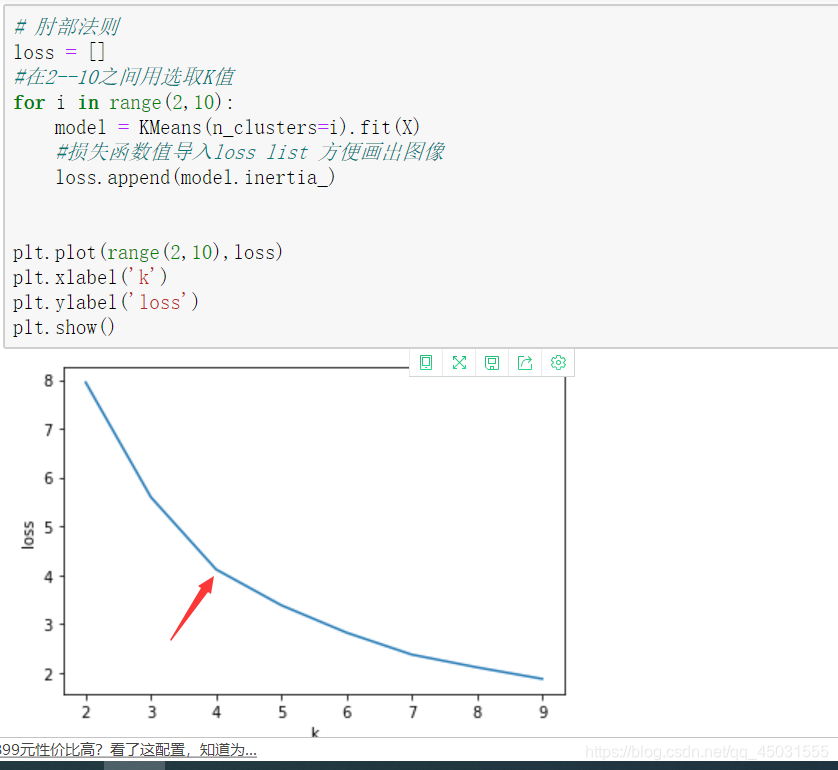
用K值来训练模型:
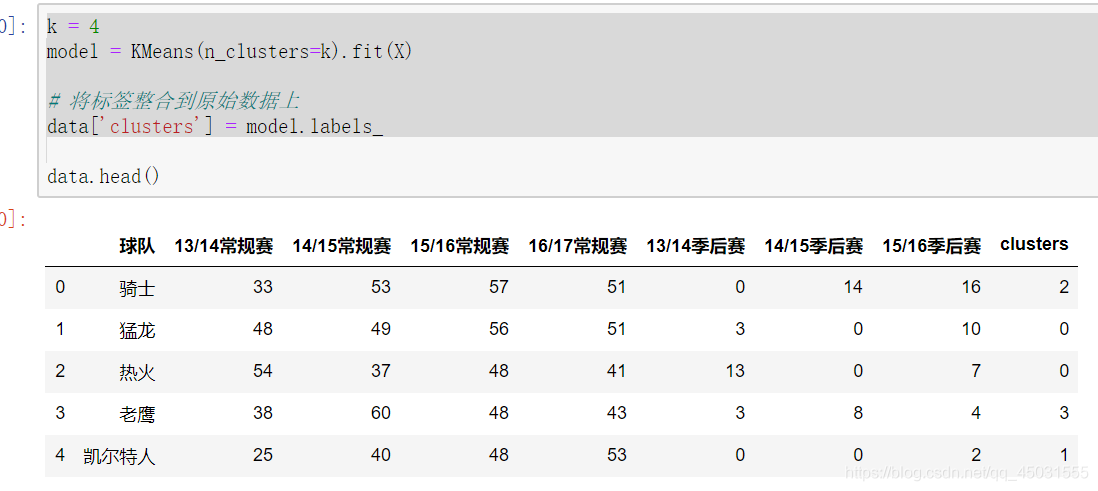
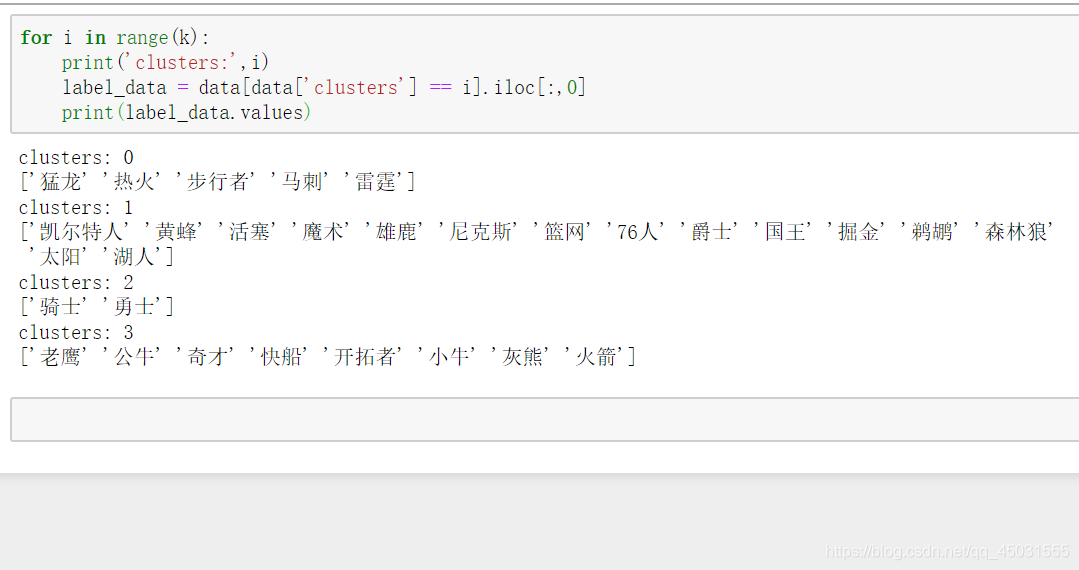
打印出聚类效果:
完整代码
from sklearn.cluster import KMeans
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
data = pd.read_csv('Nba_data.csv')
minmax_scaler = MinMaxScaler()
# 标准化数据
X = minmax_scaler.fit_transform(data.iloc[:,1:])
# 肘部法则
loss = []
#在2--10之间用选取K值
for i in range(2,10):
model = KMeans(n_clusters=i).fit(X)
#损失函数值导入loss list 方便画出图像
loss.append(model.inertia_)
plt.plot(range(2,10),loss)
plt.xlabel('k')
plt.ylabel('loss')
plt.show()
k = 4
model = KMeans(n_clusters=k).fit(X)
# 将标签整合到原始数据上
data['clusters'] = model.labels_
for i in range(k):
print('clusters:',i)
label_data = data[data['clusters'] == i].iloc[:,0]
print(label_data.values)以上就是我这三天对于K-means的学习笔记。
以上是关于学习日记(2.22-2.21 K-MEANS)的主要内容,如果未能解决你的问题,请参考以下文章
机器学习算法精讲20篇-k-means聚类算法应用案例(附示例代码)