机器学习的基本概念
Posted yifanrensheng
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习的基本概念相关的知识,希望对你有一定的参考价值。
目录
- 机器学习定义
- 基本概念
- 机器学习之常见应用框架
- 机器学习、数据分析、数据挖掘区别与联系
- 机器学习分类【重要】
- 机器学习开发流程【重要】
- 机器学习之商业场景
? ?
一、机器学习定义
Machine Learning(ML) is a scientific discipline that deals with the construction and study of algorithms that can learn from data.
机器学习是一门从数据中研究算法的科学学科。机器学习直白来讲,是根据已有的数据,进行算法选择,并基于算法和数据构建模型,最终对未来进行预测
A program can be said to learn from experience E with respect to some class of tasks T and performance measure P , If its performance at tasks in T, as measured by P, improves with experience E.
对于某给定的任务T,在合理的性能度量方案P的前提下,某计算机程序可以自主学习任务T的经验E;随着提供合适、优质、大量的经验E,该程序对于任务T的性能逐步提高。
机器学习是人工智能的一个分支。我们使用计算机设计一个系统,使它能够根据提供的训练数据按照一定的方式来学习;随着训练次数的增加,该系统可以在性能上不断学习和改进;通过参数优化的学习模型,能够用于预测相关问题的输出。

二、基本概念
- 拟合:构建的算法符合给定数据的特征
- 鲁棒性:也就是健壮性、稳健性、强健性,是系统的健壮性;当存在异常数据的时候,算法也会拟合数据
- 过拟合:算法太符合样本数据的特征,对于实际生产中的数据特征无法拟合
- 欠拟合:算法不太符合样本的数据特征
三、机器学习之常见应用框架
sciket-learn(Python) http://scikit-learn.org/stable/
Mahout(Hadoop生态圈基于MapReduce) http://mahout.apache.org/
Spark Mllib http://spark.apache.org/
应用场景选择:
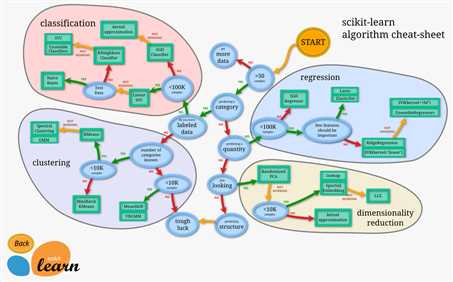
https://scikit-learn.org/stable/tutorial/machine_learning_map/index.html
四、机器学习、数据分析、数据挖掘区别与联系
- 数据分析:数据分析是指用适当的统计分析方法对收集的大量数据进行分析,并提取有用的信息,以及形成结论,从而对数据进行详细的研究和概括过程。在实际工作中,数据分析可帮助人们做出判断;数据分析一般而言可以分为统计分析、探索性数据分析和验证性数据分析三大类。
- 数据挖掘:一般指从大量的数据中通过算法搜索隐藏于其中的信息的过程。通常通过统计、检索、机器学习、模式匹配等诸多方法来实现这个过程。
- 机器学习:是数据分析和数据挖掘的一种比较常用、比较好的手段。
五、机器学习分类
5.1 有无标签划分
有监督学习
用已知某种或某些特性的样本作为训练集,以建立一个数学模型,再用已建立的模型来预测未知样本,此种方法被称为有监督学习,是最常用的一种机器学习方法。是从标签化训练数据集中推断出模型的机器学习任务。
- 判别式模型(Discriminative Model):直接对条件概率p(y|x)进行建模,常见判别模型有:线性回归、决策树、支持向量机SVM、k近邻、神经网络等;
- 生成式模型(Generative Model):对联合分布概率p(x,y)进行建模,常见生成式模型有:隐马尔可夫模型HMM、朴素贝叶斯模型、高斯混合模型GMM、LDA等;
生成式模型更普适;判别式模型更直接,目标性更强
生成式模型关注数据是如何产生的,寻找的是数据分布模型;判别式模型关注的数据的差异性,寻找的是分类面
由生成式模型可以产生判别式模型,但是由判别式模式没法形成生成式模型
无监督学习
与监督学习相比,无监督学习的训练集中没有人为的标注的结果,在非监督的学习过程中,数据并不被特别标识,学习模型是为了推断出数据的一些内在结构。
- 无监督学习试图学习或者提取数据背后的数据特征,或者从数据中抽取出重要的特征信息,常见的算法有聚类、降维、文本处理(特征抽取)等。
- 无监督学习一般是作为有监督学习的前期数据处理,功能是从原始数据中抽取出必要的标签信息。
半监督学习
考虑如何利用少量的标注样本和大量的未标注样本进行训练和分类的问题,是有监督学习和无监督学习的结合
5.2 功能性分类
分类
通过分类模型,将样本数据集中的样本映射到某个给定的类别中(一般四有监督)
聚类
通过聚类模型,将样本数据集中的样本分为几个类别,属于同一类别的样本相似性比较大(属于无监督)
回归
反映了样本数据集中样本的属性值的特性,通过函数表达样本映射的关系来发现属性值之间的依赖关系
关联规则
获取隐藏在数据项之间的关联或相互关系,即可以根据一个数据项的出现推导出其他数据项的出现频率。(也属于无监督)
算法名称 | 算法描述 |
C4.5 | 分类决策树算法,决策树的核心算法,ID3算法的改进算法。 |
CART | 分类与回归树(Classification and Regression Trees) |
kNN | K近邻分类算法;如果一个样本在特征空间中的k个最相似的样本中大多数属于某一个 类别,那么该样本也属于该类别 |
NaiveBayes | 贝叶斯分类模型;该模型比较适合属性相关性比较小的时候,如果属性相关性比较大的 时候,决策树模型比贝叶斯分类模型效果好(原因:贝叶斯模型假设属性之间是互不影 响的) |
SVM | 支持向量机,一种有监督学习的统计学习方法,广泛应用于统计分类和回归分析中。 |
EM | 最大期望算法,常用于机器学习和计算机视觉中的数据集聚领域 |
Apriori | 关联规则挖掘算法 |
K-Means | 聚类算法,功能是将n个对象根据属性特征分为k个分割(k<n); 属于无监督学习 |
PageRank | Google搜索重要算法之一 |
AdaBoost | 迭代算法;利用多个分类器进行数据分类 |
六、机器学习开发流程
6.1 数据收集
数据来源:用户访问行为数据、业务数据、外部第三方数据
数据存储:
1、需要存储的数据:原始数据、预处理后数据、模型结果
2、存储设施:mysql、HDFS、HBase、Solr、Elasticsearch、Kafka、Redis等
数据收集方式:Flume & Kafka(大数据方向的时候要掌握)
在实际工作中,我们可以使用业务数据进行机器学习开发,但是在学习过程中,没有业务数据,此时可以使用公开的数据集进行开发,常用数据集如下:
http://archive.ics.uci.edu/ml/datasets.html
https://aws.amazon.com/cn/public-datasets/
https://www.kaggle.com/competitions
http://www.kdnuggets.com/datasets/index.html
http://www.sogou.com/labs/resource/list_pingce.php
https://tianchi.aliyun.com/datalab/index.htm 国内的:天池的数据
http://www.pkbigdata.com/common/cmptIndex.html
6.2 数据预处理
-实际生产环境中机器学习比较耗时的一部分
-大部分的机器学习模型所处理的都是特征,特征通常是输入变量所对应的可用于模型的数值表示
-大部分情况下 ,收集得到的数据需要经过预处理后才能够为算法所使用,预处理的操作
-主要包括以下几个部分:
- 数据过滤
- 处理数据缺失
- 处理可能的异常、错误或者异常值
- 合并多个数据源数据
- 数据汇总
-对数据进行初步的预处理,需要将其转换为一种适合机器学习模型的表示形式,对许多模型类型来说,这种表示就是包含数值数据的向量或者矩阵
- 将类别数据编码成为对应的数值表示(一般使用one-hot编码方法)
- 从文本数据中提取有用的数据(一般使用词袋法或者TF-IDF)
- 处理图像或者音频数据(像素、声波、音频、振幅等<傅里叶变换>,小波变换主要处理图像)
- 数值数据转换为类别数据以减少变量的值,比如年龄分段
- 对数值数据进行转换,比如对数转换
- 对特征进行正则化、标准化,以保证同一模型的不同输入变量的值域相同
- 对现有变量进行组合或转换以生成新特征,比如平均数 (做虚拟变量)不断尝试
对于2)做一个分析:
词袋法:将文本当作一个无序的数据集合,文本特征可以采用文本中的词条T进行体现,那么文本中出现的所有词条及其出现的次数就可以体现文档的特征
TF-IDF: 词条的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降;也就是说词条在文本中出现的次数越多,表示该词条对该文本的重要性越高,词条在所有文本中出现的次数越少,说明这个词条对文本的重要性越高。TF(词频)指某个词条在文本中出现的次数,一般会将其进行归一化处理(该词条数量/该文档中所有词条数量);IDF(逆向文件频率)指一个词条重要性的度量,一般计算方式为总文件数目除以包含该词语之文件的数目,再将得到的商取对数得到。TF-IDF实际上是:TF * IDF
6.3 特征提取
6.4 模型构建
模型选择:对特定任务最优建模方法的选择或者对特定模型最佳参数的选择。
6.5 模型测试评估
在训练数据集上运行模型(算法)并在测试数据集中测试效果,迭代进行数据模型的修改,这种方式被称为交叉验证(将数据分为训练集和测试集,使用训练集构建模型,并使用测试集评估模型提供修改建议)
模型的选择会尽可能多的选择算法进行执行,并比较执行结果
模型的测试一般以下几个方面来进行比较,分别是准确率/召回率/精准率/F值
- 准确率(Accuracy)=提取出的正确样本数/总样本数
- 召回率(Recall)=正确的正例样本数/样本中的正例样本数——覆盖率
- 精准率(Precision)=正确的正例样本数/预测为正例的样本数
- F值=Precision*Recall*2 / (Precision+Recall) (即F值为正确率和召回率的调和平均值)
6.6 投入使用(模型部署与整合)
- 当模型构建好后,将训练好的模型存储到数据库中,方便其它使用模型的应用加载(构建好的模型一般为一个矩阵)
- 模型需要周期性:一个月、一周
6.7 迭代优化
- 当模型一旦投入到实际生产环境中,模型的效果监控是非常重要的,往往需要关注业务效果和用户体验,所以有时候会进行A/B测试(3:7测试:就是原来系统和加了算法的测试,测试两者的区别)
- 模型需要对用户的反馈进行响应操作,即进行模型修改,但是要注意异常反馈信息对模型的影响,故需要进行必要的数据预处理操作
6.8 模型过程
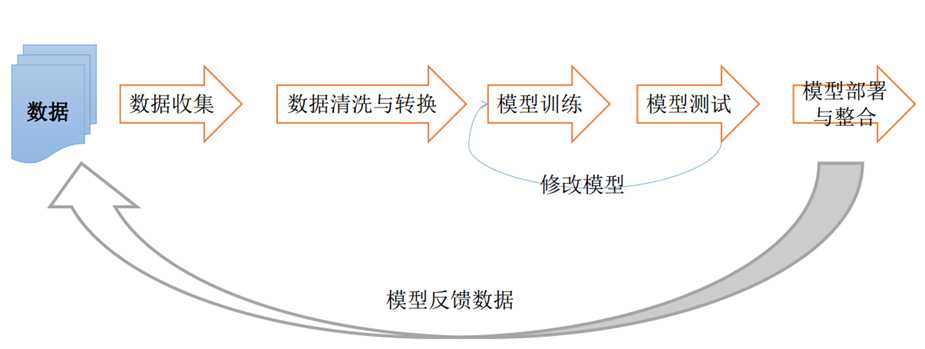
七、机器学习之商业场景
个性化推荐:个性化指的是根据各种因素来改变用户体验和呈现给用户内容,这些因素可能包含用户的行为数据和外部因素;推荐常指系统向用户呈现一个用户可能感兴趣的物品列表。
精准营销:从用户群众中找出特定的要求的营销对象。
客户细分:试图将用户群体分为不同的组,根据给定的用户特征进行客户分组。
预测建模及分析:根据已有的数据进行建模,并使用得到的模型预测未来。

? ?
? ?
以上是关于机器学习的基本概念的主要内容,如果未能解决你的问题,请参考以下文章