猴子都能懂的数据库避坑指南
Posted xiao2shiqi
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了猴子都能懂的数据库避坑指南相关的知识,希望对你有一定的参考价值。
前言
工作的这些年发现一个比较奇怪的现象就是身边无论是工作十多年的老兵,还是初级刚入行的程序员,在高谈阔论技术和趋势的时候都是人工智能,大数据,区块链,各种框架,语言,算法,AI,BI,CI,DI…… 等等,倒是发现很少有人关注数据库,不知道是因为数据库感觉太低端还是太低调,总是不容易被人提起
技术就是这样,不太关注的地方就不会重视,越是不被重视的地方,掉进坑里的概率就会越大,所以就在这里给大家简单聊聊在使用数据库过程中有哪些防掉坑指南,也可以对刚入行的小朋友有一个提醒的作用,万丈高楼平地起,一定要先打好基础再去考虑上层的建筑,不要舍本逐末
本章主要分以下四个小节(预计读完 5 分钟左右):
- 数据库为什么重要
- 数据库有哪些使用技巧
- 数据库有哪些容易掉进去的坑?
- 深入学习数据库的建议
数据库为什么重要
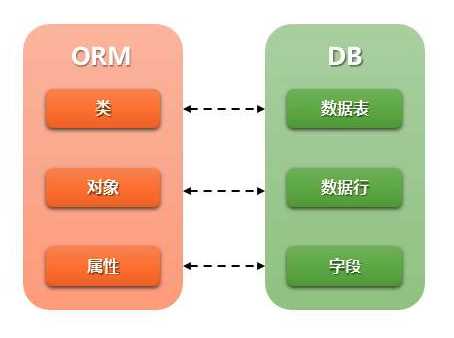
很多人在开发过程中不太关注数据库,对于表结构的设计也没什么讲究大多属于“能用就行”,但是根据作者将近十年的开发经验来看的话,只要你是从事 Web 相关领域开发你就无法避免不和数据库打交道,在Web开发中大多功能操作本质上都是对数据库进行操作,不管你用是 Pythod,Java,Ruby 等语言进行 Web 开发,你其实都是在面向数据库进行编程,很多 Web 框架作者为了避免程序员接触数据库的相关知识甚至还封装了一层 ORM (Object Relational Mapping 对象关系映射),把数据库当做一个黑盒子,然后通过操作对象的形式来操作数据库
虽然某种意义上是简化的开发,对此我是持有保留意见的,因为对于程序员来说很有必要了解你的 SQL 语言在数据库是怎么执行的,你不仅需要使用 explain 执行计划来查看你的 SQL 是否高效(扫描行数,命中索引,回表,排序等),对比不同 SQL 的写法外,你还需要知道如何使用 show index 来查看你的索引是否高效(通过 Cardinality 由数据库评估),这些技巧很大程度依赖你对 SQL 的了解,SQL 对于程序员来说也是一门非常重要的技能,没错 SQL 就是操作数据库的语言,据我了解大多数的公司在面试的时候都会考察程序员的 SQL 功底,扎实的 SQL 功底不仅可以让你写出高性能的查询语言外,对于数据分析,报表统计也是有非常大的帮助
大多数商业公司的核心资产其实就是数据库里面的数据,是非常宝贵的财富,程序和系统挂了,最多就是一段时间不可用,大多是情况重启就可以恢复,但是是数据库不小心被误删了,如果是运维能力差的中小企业可能会面临倒闭的地步,从商业角度上来说数据库大多数软件公司的核心
很多程序员从菜鸟成长到高手,接触的项目从学校的"某某管理系统"到刚加入公司内部系统,然后再到大型分布式系统,在大型系统中,大多数人程序员通常遇到的第一个问题通常不是线程不够用,不是CPU负载过高,不是内存不够快,通常都是数据库扛不住压力了,为什么呢?数据库本身就基于磁盘的文件系统,每次读取数据都是通过 I/O 去访问磁盘,了解计算机原理的同学应该都知道,在冯诺依曼计算机体系结构里磁盘 I/O 号称是最慢的 I/O (毫秒级),通常在你的系统只有几千上万的数据量时,全表扫描通常不会有很大的延迟感,但是当你的存量数据达到百万千万时,那么一次普通的查询就会把你的数据库服务器撑爆,做过应用的人都知道,数据库挂了,不管是什么分布式,微服务的牛逼架构都基本没啥用了,唠唠叨叨说到这里,相信大家应该已经知道数据库的重要性的,后面我们再从数据库设计的角度来看下问题
数据库设计对系统的影响
这里我们简单做一个对比,良好的数据库设计可以为你带来什么 ?
- 减少数据冗余,避免数据维护异常
- 节省存储空间,高效的访问速度
糟糕的设计 ?
- 大量数据冗余插入,更新,删除异常
- 浪费存储空间,低效的访问速度

糟糕的设计(图)
比如说对于一个简单的年龄字段,严谨来说应该使用 tinyint(1字节)或者 smallint(2字节),但是你偏偏要用 int (4字节) 这就属于糟糕的字段选择,看到这里很多刚入门的同学就可能就会反驳了,这么在意空间利用是不是有点矫枉过正?包括存储已经很便宜了,还这么斤斤计较般的选择,反正最终实现的功能都是相同的,别人也看不出什么差别呀。对于这种观点其实我想反驳一下,这是典型的新手思维,你只在看到在单个字段上的空间节省,但是没有考虑过数据也是在持续增长,糟糕的设计越到后期增长成本会越高(这里就类似于 Java 的经典面试题,集合类 ArrayList 和 LinkedList 在少量数据对比时看不出时间上的差距,但是随着计算数据量的上升,消耗数据的差距也会越拉越大),等到了千万级数据量的时候,可能你设计的表和别人设计的表是相同的内容,但是你的表无端的多出几百G的存储空间,如果你的应用还是多数据中心的话,那么这种无端的空间浪费还会被拷贝几十倍到不同的数据中心,而且只要你的应用还在线上运行,那么这种增长所带来的成本还会持续上升,这里也仅仅只是说对空间的浪费,下面在分析表结构存储上,还会具体说一下糟糕的设计对于性能会有多大的影响,这对企业来说就是边际成本的递增,从技术和架构上来说就会让你的系统不具备可扩展性
数据库的使用技巧
存储引擎的注意事项
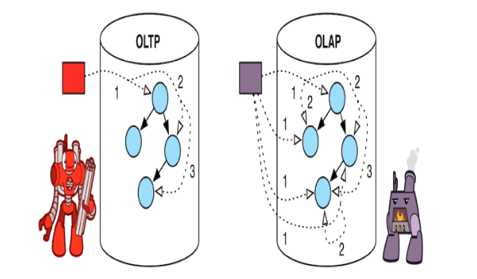
mysql 的开放性架构设计兼容了很多不种类的存储引擎(要是你足够厉害的话,也可以自己写一套存储引擎),存储引擎的设计初衷就是应对不同类型的数据仓库,工作中有见过不管什么表都直接用 Innodb(MySQL 5.0 的默认存储引擎,虽然大多数场景是不错的选择,但不是所有类型的表结构都适用)也见过根本不知道什么是存储引擎的同学,如果这些同学来设计数据库的话,那么你的系统就很容易踩到坑,出现很多你自己的预料不到的问题,合理的存储引擎的选择是应该结合实际业务场景,从目前最主流的 MySQL 来说,最常用的存储引擎主要是 MyISAM, Innodb,当然还有很多其他的存储引擎,例如 NDB(集群存储引擎),Memory(基于内存的存储引擎),Archive(归档存储引擎),因为这些平时使用不多,并不主流,工作中也很少用得到,意义不大,所以就不展开来讲,这里主要简单将下 MyISAM,Innodb 的区别,主要有以下特点:
MyISAM
- 无事务机制,表级锁,自带计数功能(count 全表毫秒级响应)
- 主要面向 OLAP 型应用,适合存储报表日志等类型数据
Innodb
- 行级别,高并发,支持事务,四种事务隔离级别(MySQL 5.0+ 默认是读已提交)
- 主要面向 OLTP 型应用,适合存储小量的事务型数据
字段类型的注意事项
因为不了解数据库的基本原理,所以很多初级程序员在选择数据库字段类型的时候比较迷茫,主要还是没有明确指导原则,工作中我见过在只有十几条数据的基础信息表中使用 long(8字节)作为 id 主键类型,还有就像上面说的状态类型字段只有 0,1 值的字段使用 int (4字节),还见过字符类型字段统一使用 varchar(255),数值类型字段统一使用 int,这种不基于数据库原理规则去随意选择字段的行为也只会出现在你 LocalHost 里的一些小项目或者玩具,基本上不了什么大台面
据我所知,主流的数据库大多都提供非常丰富的字段类型给开发者使用,老司机都是基于业务类型的判断从而选择合适的字段类型,最终收获的是性能(时间)和存储(空间)都非常低的高性能数据库,具体数据库有哪些字段类型,文章里面就不多数了,这方面的资料简直太多了,有兴趣的小伙伴可以自己去搜索,例如这里 MySQL Data Types,那么对于新手而言如何选择字段类型呢?
简单的基本原则如下:(后面会具体将原因)
- 优先数字型字段(比如尽量使用 int 作为数据库主键 id 的类型而不是 varchar)
- 在满足需求的前提下,字段类型尽量足够的小(例如 age 字段应该考虑使用 tinyint 而不是 int 或者 long 类型)
- 时间字段考虑 timestamp (4字节,支持 UTC)而不是 datetime(8字节,不支持 UTC)
遵循基本规范能带来什么好处?
- 节省存储的开销,避免空间浪费(如果1条数据造成的空间开销n,那么随着数据增长,浪费空间的比例也就是 n * n)
- 最好的性能(用户体验,另一种角度的节省资源-算力)
为什么要把“选择尽可能小的字段”作为基本原则?我们可以先看下 innodb 的逻辑存储结构
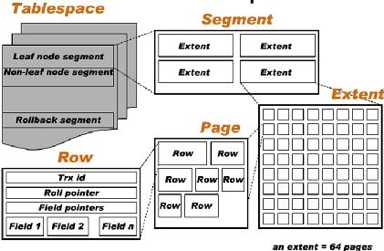
innodb 逻辑存储结构(图)
innodb 的存储结构如下:
- 表空间(Tablespace)
- 段(Segment):表空间由多个段组成
- 区(Extent):单个区由 64 个连续页(Page)组成
- 页(Page):磁盘的最小单位,默认大小 16 KB
- 行(Row):每条记录,也称行数据,数据存储在页中 Page
上图可以看到读取最小单元 Page,匹配的数据都是从 Page 里面取出,按照这个简单的逻辑来说页中存储的行数据越多,数据库的性能就越高,怎么算出来的呢?按最小类型 2B 来计算 Row,那么 Page 的默认大小(16KB)是可以匹配到 7992 行记录,相反,如果你的 Row 行数据过大,假如一行 32 KB,那么数据库就需要 2 个连续的 Page 来保存你一行的数据,那么性能可想而知会有多低,前后性能差距差不多 1.6 万倍,这块也不深入讲了,有兴趣的小伙伴推荐去阅读经典书籍,这里的内容也只是书里的冰山一角
选择索引的注意事项
索引是一种用空间换时间的优化手段,是数据库最重要的优化手段,也是最后的杀手锏,索引是否高效取决数据库设计是否良好,字段类型选择是否合理,索引是一把双刃剑,在提升检索速度的时候,也会减低插入,修改的性能(维护索引树的开销),在工作中这些年面试了不下几百人发现能把数据库索引原理讲明白的候选人非常的少,大多数情况下我们说索引通常默认指的是 BTREE 索引,BTREE 结构是特意为磁盘 I/O 这种缓慢的读取存储设计的数据结构,是一棵多路多叉树,和二叉树相反,每层的元素非常多,但是树的高度很矮(通常不会超过三层),从而可以保证最多不超过三次磁盘 I/O 即可定位到匹配的元素,所以说 BTREE 是一种非常适合磁盘的数据结构,也是 MySQL 默认索引类型是 BREE 的原因,如果能把这块吃透的话,那么去面试肯定是很大的加分项,索引在数据库可以简单参考下图:
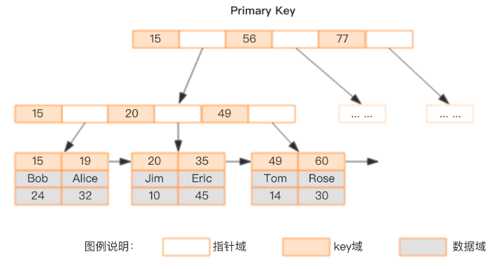
简单说了下索引的结构,那么新手程序员在使用数据库所以的时候可以遵循以下原则:
- 明白索引不是越多越好,过多的索引会降低读/写效率
- 数据小和选择性低的列没有必要建索引(就像没必要为只有几页的书建目录)
- 定期维护索引(移除不必要的索引,索引的最左匹配原则)
- 谨慎使用全文索引,哈希索引,谨慎使用 FORCE INDEX 强制索引(强制会干扰优化器对索引选择的判断)
索引这块可以玩的还有很多,例如如何通过 SHOW INDEX 查看数据库为索引做出的评级(通过 Cardinality 统计),通过 Explain 查看 SQL 是否命中索引,rows 列可以看到 SQL 扫描的数据行数,Extra 列还可以查看索引匹配的类型,例如 Using index 代表完全匹配索引(无需回到 Primary Key 表查询数据,也称回表,甚至直接使用索引的排序,无需排序)往往说明性能不错,Using temporary 代表查询有使用临时表,一般出现于排序,多表 join 的情况,查询效率不高,建议优化
还有哪些要避开的坑?
人生总会遇到很多坑,与其自己去踩坑不如去总结别人踩过的坑,自己少走一些弯路也许可以更快的成功,这里是最后一章,不想把文章拉的太长,所以我在这里就直接抛出结论,不会再说明原因,如果对数据库有兴趣推荐看到最后我推荐的书籍
避免使用触发器/存储过程
- 用存储过程写逻辑会导致代码非常的复杂难懂,并且难以定位问题
- 降低数据库的性能(数据库不应该执行除 SQL 外的其他逻辑操作)
避免使用预留字段
- 无法准确预测字段类型
- 增加后期维护成本
反范式设计
- 不必完全遵守古板的三大范式,对范式进行违反,用空间换时间
- 对数据进行有计划的冗余,可以达到减少关联,提高性能和效率
尽量避免使用 Null 字段
- Null 值会导致索引失效,让统计函数更加复杂,另外 Null 还会占用额外的空间(数据库需要额外标记)
- 对于 Null 值,数据库程序通常都会进行额外的逻辑处理,奖励数据库性能
- 从数据库中取出 Null 值容易造成程序出错,还会增加很多 if != null 的重复模板代码
最后 end
这篇文章写了三天(空闲时间),主要覆盖篇幅比较广,但是每个主题都是在幼儿园的入门水平,主要是给很多新手程序员一个简单的参考,我个人认为看文章分享只是为了点燃兴趣,就像一道开胃菜,最终的形成自己的知识体系,熟悉知识完整的结构还是推荐去阅读经典的书籍,这才是学习的正确姿势,数据库的书我读的不是很多,但还是可以简单推荐两本我读过的并且感觉非常不错的,并且本篇文章都是大量参考了书中的内容,非常值得推荐:
- 《MySQL 技术内幕 InnoDB 存储引擎》:这本书主要偏向对存储引擎的分析,对不同存储引擎的性能,存储结构和适用场景做了横向对比,作者最后还在表分区,约束和索引等技术上给出自己的见解,我在看这本书的时候无不佩服作者对存储引擎的了解程度
- 《高性能 MySQL》:这本可以说是 MySQL 的百科全书,内容覆盖非常全面,是公认 MySQL 领域的圣经级教科书,唯一的缺点就是太厚了,第三版都已经快 800 页了


值得推荐的书就以上两本,如果觉得看书不过瘾可以再推荐看看极客时间的 《MySQL 实战 45 讲》是由鼎鼎大名的数据库大神丁奇所写的专栏,如果用开药来比喻的话,看书就是内服,看专栏就等于外敷,总结就是,内服 + 外敷 疗效可能会好一些,最后打一波广告:如果要买极客时间专栏可以加我微信,我有推荐二维码并且返现红包,666666
更多技术咨询,请关注公众号,find me !

以上是关于猴子都能懂的数据库避坑指南的主要内容,如果未能解决你的问题,请参考以下文章