机器学习(06)——K近附算法实战
Posted emptyfs
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习(06)——K近附算法实战相关的知识,希望对你有一定的参考价值。
学习机器学习算法,最难的不是算法及公式推导的学习,因为这些很多都是成熟的现成的,有代码例子可以直接使用。最难的是将算法应用到实际的项目当中。
1. 算法概念
K最近邻(k-Nearest Neighbor,KNN)分类算法,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一。该方法的思路是:在特征空间中,如果一个样本附近的k个最近(即特征空间中最邻近)样本的大多数属于某一个类别,则该样本也属于这个类别。
使用KNN算法进行分析预测,K值的选择、距离度量和分类决策规则是该算法的三个基本要素,直接影响预测的准确率。
在运用KNN算法时,我们通常需要将相关的特征值转换为数值型,而该数值的大小、与其他特征的关联度或数值间隔关系的设计(也就是分类决策规则),都会直接影响各数据之间的距离,而最终预测计算时,所选择样本的数量(K值大小),都会直接影响最终结果的准确率。
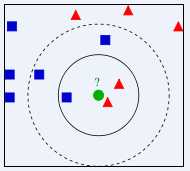
比如下图中的例子,当K=3时,答案为红色三角形,而K=5时,结果却变为蓝色正方形。
2. KNN实现公司电脑开关机预测
1)项目说明
我们的电脑里安装了各种软件,这些软件会时不时访问外网,通过防火墙日志记录,我们可以从中分析出公司电脑的开关机情况,查看哪些电脑正常开机关机,哪些没有一直没有关机,哪些没有开机。
使用KNN算法,实现对公司电脑开关机状态的预测功能。
2)日志信息
通过查看防火墙日志,可以看到日志中有日期、防火墙设备名称、源ip地址(局域网ip)、网卡mac地址等信息
date=2020-01-10 time=00:13:08 devname="AW-B1-901" devid="FG100ETK18038642" logid="0000000020" type="traffic" subtype="forward" level="notice" vd="root" eventtime=1578586388984224524 tz="+0800" srcip=192.168.10.13 srcport=16701 srcintf="Local-Office" srcintfrole="lan" dstip=220.175.160.92 dstport=17048 dstintf="wan1" dstintfrole="wan" poluuid="0f219964-b02c-51e9-b295-bc4f936d8f3c" sessionid=59239552 proto=17 action="accept" policyid=1 policytype="policy" service="udp/17048" dstcountry="China" srccountry="Reserved" trandisp="snat" transip=113.108.110.48 transport=16701 appcat="unknown" applist="default" duration=166 sentbyte=30 rcvdbyte=0 sentpkt=1 rcvdpkt=0 shapingpolicyid=9 shaperperipname="Limit-Wan1-15M" shaperperipdropbyte=0 sentdelta=30 rcvddelta=0 mastersrcmac="1c:ab:34:9f:a9:fb" srcmac="1c:ab:34:9f:a9:fb" srcserver=0
3)设计思路
在使用KNN算法预测之前,我们首先要解决的是,如何使用这些日志数据来判别电脑的开关机情况?
业务流程思考
通过分析我们日常对电脑的操作,可以得出这些操作流程:
早上上班 =》 打开电脑 =》 电脑软件请求网络访问 =》 防火墙记录请求日志 =》 晚上下班 =》 关闭电脑 =》 防火墙不再有这台电脑的请求日志记录
业务问题思考
需要思考的问题有:
- 有时请假半天,只有半天的记录
- 请假一天,当天没有记录
- 电脑一直开着,没有关机
- ip变更,有新机器加入网络或原ip改变了
- 节假日与工作日,电脑开机情况有很大差别
- 移动设备连接wifi如何区分
- 虚拟机如何处理
对于这些问题,我们可以做如下处理:
- 一天当中,挑选出4个时间段,查看是否有这些ip日志记录存在,有的则表示该时间段电脑处于开机状态,没有的则表示处于关机状态
- 4个时间段可以选早上10点到11点、下午15点到16点、凌晨2点到3点、4点到5点,白天只要有一条记录,则表示电脑开机了,凌晨只要有一条记录,则表示电脑没关机,而对于白天没有记录凌晨才有的,则记录为没关机状态
- 经查看日志数据分析,srcmac记录的并非是电脑网卡的mac,所以当前只能用ip地址来判断绑定电脑(如果防火墙能准确获取mac地址,则用mac判断指定电脑状态会更加准确)
- 需要设计ip表与状态表两个数据表,从日志中获取到未记录ip,需要先在ip表中进行添加,然后再更新状态表
- 每天需要为ip表记录在状态表里创建一条对应的绑定记录,因为员工请假后,当天没开机是没有记录的,除非不预测关机状态,只预测正常开关机与没关机两种状态
- 节假日与工作日的数据会有很大差别,需要作节假日判断,进行区分
- 移动设备如果在防火墙日志中区分不了,可使用独立的交换机与网段进行区分
- 虚拟机无法区分,也当作正常电脑来处理
基于KNN算法,数据结构的设计思考
针对KNN算法采用的是通过计算预测目标与学习数据集每个数据的差值,找出K个差值最小的数据,通过统计这些数据所属类别哪一个占比较大,来决定预测目标的类别方法。在做数据设计时,我们需要将ip、节假日和工作日转换为数值,这样才能通过计算学习,来判别指定ip在指定日期里,它的开关机状态可能是哪一种。
也就是说:我们需要将ip与节假日转化为可以进行加减运行的数值,方便和预测目标求差值,从而找出距离时最小的记录。
例如:我们将ip:192.168.10.10切分为4个数值,然后将它们分别乘于不同的256,计算得出一个唯一的数值,如:
192 * 256 * 256 * 256 + 168 * 256 * 256 + 10 * 256 + 10 = 3232238090
由于我们判断的是局域网的电脑,而这些电脑的网段都是以192.168开头的,所以我们只需要计算后面的差值即可:
10 * 256 + 10 = 2570
对于IP计算出来的值,为了区分每一个IP的变化状态,需要将结果再乘于500(到底乘多少需要根据其他参数值而定,只要能达到数据与数据的分隔就可以了),扩大数值的差距(因为每个人的操作习性不一样,IP差值太小时,很容易在预测计算时,发生越界,所求出差值最小的数据可能是多个不同ip的记录。比如192.168.10.10与192.168.10.11之间,相差1,预测时它们分别与其他参数相加,有可能筛选出来的结果就会混杂在一块)
(10 * 256 + 10) * 500 = 1285000
节假日与工作日,也可以转换为0至6(即周一到周日)来进行区分,对于周六、日等节假日,为了与工作日拉开距离,提升分析的准确率,值都设置为7。
而法定假期中,公历假期可以直接通过日期进行判断,农历假期则可以调用相关插件,获取农历日期来进行判断处理。对于节假日调休等情况,由于有更多的变数很难通过计算得知,对预测影响不大可以不作考虑。
通过上面转换,我们可以得出以下结果:
# 日期 IP 状态
2020-01-01 192.168.10.10 没开机 (周三,元旦)
2020-01-02 192.168.10.10 没关机 (周四)
2020-01-03 192.168.10.10 正常 (周五)
2020-01-04 192.168.10.10 没开机 (周六)
2020-01-05 192.168.10.10 没开机 (周日)
2020-01-06 192.168.10.10 正常 (周一)
2020-01-05 192.168.10.14 没开机 (周日)
2020-01-06 192.168.10.14 正常 (周一)
# 转换结果为
# 日期 IP值 周数
2020-01-01 1285000 7
2020-01-02 1285000 3
2020-01-03 1285000 4
2020-01-04 1285000 7
2020-01-05 1285000 7
2020-01-06 1285000 0
2020-01-06 1287000 7
2020-01-06 1287000 0
当我们要预测日期为2020-01-10,IP为192.168.10.10的开关机状态时,就可以先将预测参数先转为对应的数值,即2020-01-10是周五,即值为4,IP值为1285000,这两个值做为参数代入KNN算法中进行计算。
# 计算结果(将学习数据集中每一条数据都与预测目标相减,并将数据中的值求平方后相加————主要是为了去除负数)
相减后IP值 相减后周数值 相减后两参数平方之和
0 3 9
0 -1 1
0 0 0
0 3 9
0 3 9
0 -4 16
2000 3 4000009
2000 -4 4000016
通过从小到大排序,如果K值取1,则可以得出与目标值最近的数据为2020-01-03 192.168.10.10 正常 (周五)这一条数据,预测结果为“正常开关机”状态。
在做KNN预测时,数据量越大预测结果越准确,比如如果周五员工有8次正常开关机,2次没关机,预测结果肯定为正常开关机状态,在概率上更靠近真实结果。
而K的取值也是一样,通过使用大量数据进行测试,就可以找出预测成功率最高的区间,从而能更精确的进行预测。
在特征转数值时,有时候会遇到无法直接用数值代替的特征,可以使用索引或根据主观判断打分等方式进行转换,转换后需要使用大量数据对预测模型进行测试,然后根据预测结果的准确度进行微调,最终找到最优的数值模型。
ip表与状态表设计
ip表数据字典
| 表名 | 字段名称 | 字段类型 | 主键 | 是否允许空 | 默认值 | 字段说明 |
|---|---|---|---|---|---|---|
| pc_info | id | serial | PK | 0 | 主键Id | |
| pc_info | label | text | 电脑标签,标注是谁的电脑 | |||
| pc_info | ip | text | IX | 局域网内部ip | ||
| pc_info | ip_num | int | 0 | ip地址转int值 |
主要用来记录当前内网所使用的ip,绑定使用人信息,以及按前面要求,将ip转为数值,方便knn算法的计算使用
状态表数据字典
| 表名 | 字段名称 | 字段类型 | 主键 | 是否允许空 | 默认值 | 字段说明 |
|---|---|---|---|---|---|---|
| pc_info | id | serial | PK | 0 | 主键Id | |
| pc_info | date | timestamp | IX | 日期 | ||
| pc_info | pc_info_id | int | IX | 0 | ip表id | |
| pc_info | weekdays | int | 0 | 周工作日标识:0~4=工作日(周一到周五);7=休息日 | ||
| pc_info | ten_points_state | int | 0 | 10点开机状态 | ||
| pc_info | fifteen_points_state | int | 0 | 15点开机状态 | ||
| pc_info | two_points_state | int | 0 | 第二天凌晨2点开机状态 | ||
| pc_info | four_points_state | int | 0 | 第二天凌晨4点开机状态 | ||
| pc_info | calculate | text | 预测结果:normal=正常开关机;on=未关机;no_boot=没开机 | |||
| pc_info | state | text | no_boot | 电脑实际状态:normal=正常开关机;on=未关机;no_boot=没开机 |
状态表记录每天内部电脑的通讯情况记录,并根据这些记录所判别的电脑状态结果。同时也会记录使用KNN算法进行的预测结果,用于判断预测成功率。
3. 编码实现
编写代码实现前面设想的功能,需要分几个步骤处理,首先要做的是数据清洗,从日志中将我们需要的数据提取出来;然后对这些数据进行加工处理,转化为可能提供给机器学习算法使用的数据;然后再是编码算法代码,实现预测操作。
1)数据清洗
日志每五分钟会自动进行切割,生成新的日志文件,可以定时(前面所指定的检查时间)对日志文件进行批量检查处理。
本文主要是介绍根据KNN算法实现项目功能,所以略过数据清洗等功能实现。
针对我们想要实现的功能,我们只需要在固定时间段从日志中提取该时间内请求的所有ip即可。可以直接从日志文件中提取,也可以使用Flume+Kafka+HBase方式,将日志数据从各系统中收集整理好,再从HBase中获取。
# 10点防火墙请求ip集
192.168.10.38,192.168.20.30,192.168.20.23...192.168.20.34,192.168.20.41
# 15点防火墙请求ip集
192.168.10.28,192.168.10.23,192.168.10.26...192.168.20.9,192.168.20.15
# 第二天凌晨2点防火墙请求ip集
193.192.168.10.104,192.168.10.97,192.168.10.93...192.168.10.95,192.168.10.90
# 第二天凌晨4点防火墙请求ip集
192.168.10.96,192.168.10.66,192.168.20.89...192.168.10.57,192.168.10.73
2)数据加工
ip前面虽然已经提取出来了,但还需要将它们更新到数据库中,方便后续KNN算法的调用。所以需要实现一个状态更新服务,将清洗好的数据,更新到ip表与状态表中。
主要思路是:
- 开发一个pc状态定时更新服务,该服务在指定时间启动,读取清洗好的数据(ip列表),将这些ip记录更新到ip表中存储起来(已存在则不操作,不存在则添加)
- 在状态表为每一个ip创建一条对应的记录,日期为当天的时间。这主要是为了防止有些人请假或节假日关机,对应的ip没有请求日志,会被忽略掉。创建记录时,默认电脑实际状态为关机状态。
- 获取ip对应的id值,然后根据执行的时间,如果是白天则直接更新状态表中对应字段的状态值,表示该电脑已启动。如果是凌晨有记录,则表示该电脑一直未关机,将电脑状态更新为没关机状态。
""" 每天定时更新pc开关机状态服务 """ import logging import os import sys import json import datetime import zhdate from common import log_helper, datetime_helper, hbase_helper, convert_helper from common.string_helper import string from config import const from logic import pc_info_logic, pc_on_off_state_logic # 获取本脚本所在的路径 pro_path = os.path.split(os.path.realpath(__file__))[0] sys.path.append(pro_path) # 定义日志输出格式 logging.basicConfig(level=logging.INFO, format=‘%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s‘, filename=const.SERVICE_LOG_FILE_PATH + "/pc_on_off_state_update_service.log", filemode=‘a‘) # 定义数据表名称 table = ‘firewall‘ def update_state(update_date, check_time): """ 更新pc开关机状态 :param update_date: 更新状态的日期时间。需要判断是否是凌晨时间,凌晨是否开关机状态,需要同步的是昨天电脑状态数据,即下班后电脑开关机状态 :param check_time: 状态检查时间为:早上10点,下午的15点和第二天凌晨2点与4点 :return: """ # 记录服务启动时间 start_time = datetime.datetime.now() run_time_log = ‘ ----------------------------------- ‘ run_time_log = run_time_log + ‘开始:‘ + str(start_time) + ‘ ‘ with hbase_helper.Hbase() as hbase: # 从hbase中读取指定时间已处理好(已清洗)的分析汇总信息 result = hbase.get(table, ‘summary:hour,{},60‘.format(check_time)) if not result: log_helper.info(‘summary:hour,{},60 数据不存在‘.format(check_time), True) return # 获取各防火墙ip访问统计数据,并转为json格式 data = json.loads(result[‘log_analysis:data‘]) # 提取研发部该时间段内所有记录在防火墙日志中的ip数据,并过滤掉非研发部的其他ip数据 # [‘192.168.10.38‘,‘192.168.20.30‘,‘192.168.20.23‘...‘192.168.20.34‘,‘192.168.20.41‘] ips = [ip for dev in data for ip in data[dev] if ‘192.168.10.‘ in ip or ‘192.168.20.‘ in ip] # 对ip数据进行去重操作 ips = set(ips) # 判断日期是否是工作日,并返回对应日期的值 weekdays = get_weekdays(update_date) # 初始化状态表逻辑类 _pc_on_off_state_logic = pc_on_off_state_logic.PcOnOffStateLogic() # 检查当天的状态数据是否已生成,未生成则进行批量添加操作 if not _pc_on_off_state_logic.exists(‘date=‘{}‘‘.format(update_date)): _pc_on_off_state_logic.execute(‘insert into pc_on_off_state(date, pc_info_id, weekdays) select ‘{}‘, id, {} from pc_info‘.format(update_date, weekdays)) # 初始化ip表逻辑类 _pc_info_logic = pc_info_logic.PcInfoLogic() # 遍历所有ip,并对这些ip进行相关的处理操作 for ip in ips: # 检查当前ip是否已添加到ip表,不存在的则进行添加操作 model = _pc_info_logic.get_model_for_cache_of_where(‘ip=‘{}‘‘.format(ip)) if not model: # 将ip转为数值 _ip = ip.split(‘.‘) ip_num = (convert_helper.to_int0(_ip[2]) * 256 + convert_helper.to_int0(_ip[3])) * 500 # 组合ip表更新数据 fields = { ‘ip‘: string(ip), ‘ip_num‘: ip_num } # 添加新ip记录 model = _pc_info_logic.add_model(fields, returning=‘*‘) # 状态表也添加一条新的ip记录 _pc_on_off_state_logic.add_model({‘date‘: string(update_date), ‘pc_info_id‘: model.get(‘id‘)}) # 组合状态表更新数据 fields = { ‘date‘: string(update_date), ‘pc_info_id‘: model.get(‘id‘), ‘weekdays‘: weekdays, ‘state‘: string(‘normal‘) # 只要有ip请求,即表示该电脑当开已开机,设置它的默认值为正常开关机状态 } # 通过判断当前检查时间,来同步更新各时间段的状态 if check_time.hour == 10: fields[‘ten_points_state‘] = 1 elif check_time.hour == 15: fields[‘fifteen_points_state‘] = 1 # 凌晨只要有一条请求记录,就表示这台电脑没有关机 elif check_time.hour == 2: fields[‘two_points_state‘] = 1 fields[‘state‘] = string(‘on‘) # 设置为没关机状态 elif check_time.hour == 4: fields[‘four_points_state‘] = 1 fields[‘state‘] = string(‘on‘) # 更新状态表数据 _pc_on_off_state_logic.edit(fields, ‘date=‘{}‘ and pc_info_id={}‘.format(update_date, model.get(‘id‘))) # 记录程序运行结束时间 run_time_end = datetime.datetime.now() run_time_log = run_time_log + ‘服务执行结束:‘ + str(run_time_end) + ‘ ‘ run_time_log = run_time_log + ‘总用时:‘ + str(run_time_end - start_time) + ‘ ‘ run_time_log = run_time_log + ‘----------------------------------- ‘ print(run_time_log) def get_weekdays(date): """判断日期是否是工作日,并返回对应标识""" if is_holidays(date): return 7 elif date.weekday() >= 5: return 7 return date.weekday() def is_holidays(date): """ 判断是否为节假日 :param date: 需要检测的日期 :return: 返回True或False """ # 判断是否是阳历的节假日(元旦、五一、十一) if (date.month == 1 and date.day == 1) or (date.month == 5 and date.day == 1) or (date.month == 10 and (date.day >= 1 or date.day <=7)): return True # 使用zhdate包,将阳历日期转换成农历日期对象 lunar_calendar = zhdate.ZhDate.from_datetime(datetime.datetime(date.year, date.month, date.day)) # 检查是否是过年、端午节和中秋节,清明暂时无法计算出来,不做判断 lunar_calendar = lunar_calendar.chinese() if ‘腊月二十八‘ in lunar_calendar or ‘腊月二十九‘ in lunar_calendar or ‘腊月三十‘ in lunar_calendar or ‘正月初一‘ in lunar_calendar or ‘正月初二‘ in lunar_calendar or ‘正月初三‘ in lunar_calendar or ‘正月初四‘ in lunar_calendar or ‘正月初五‘ in lunar_calendar or ‘正月初六‘ in lunar_calendar or ‘五月初五‘ in lunar_calendar or ‘八月十五‘ in lunar_calendar: return True return False if __name__ == ‘__main__‘: ### 接收参数 ### if len(sys.argv) < 2: # 检查时间为10点、15点和第二天凌晨2点与4点,日志数据的清洗,也需要等该时间过后日志记录全部生成才能进行, # 所以运行本服务需要延后一小时,而更新处理时间得减1,调整回指定的时间 now = datetime_helper.timedelta(‘h‘, datetime.datetime.now(), -1) else: log_helper.info(‘接收参数:‘ + sys.argv, True) # 接收命令行参数,设置日志分析起始时间 now = convert_helper.to_datetime(sys.argv[1]) if not now: log_helper.info(‘日期参数格式必须为:2019-11-11 11:00:00‘, True) sys.exit() # 设置更新数据的日期 update_date = now.date() # 设置检查时间 check_time = datetime.datetime(now.year, now.month, now.day, now.hour) # 检查是否是凌晨,凌晨的开关机状态同步的是昨天电脑状态数据,即下班后电脑开关机状态 if now.hour < 6: # 设置日期为昨天 update_date = datetime_helper.timedelta(‘d‘, now, -1).date() # 执行状态更新操作 update_state(update_date, check_time) log_helper.info(‘任务提交完毕‘, True)
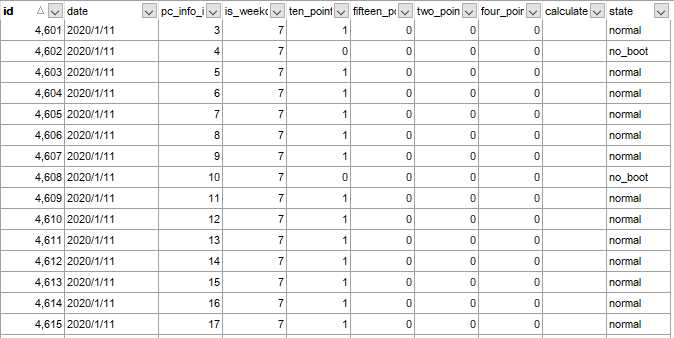
更新后数据表结果
3)使用KNN算法实现预测功能
从数据表中获取机器学习数据
# 初始化ip表与状态表逻辑类 _pc_info_logic = pc_info_logic.PcInfoLogic() _pc_on_off_state_logic = pc_on_off_state_logic.PcOnOffStateLogic() # 组合sql查询语句,获取最近2个月的分析数据作为机器学习数据 # select pc_info.id,ip,ip_num,weekdays,state from pc_info left join pc_on_off_state on pc_info.id=pc_on_off_state.pc_info_id where ‘2019-11-12‘<=date and date<‘2020-01-11‘ sql = """ select pc_info.id,ip,ip_num,weekdays,state from pc_info left join pc_on_off_state on pc_info.id=pc_on_off_state.pc_info_id where ‘{}‘<=date and date<‘{}‘ """.format(datetime_helper.timedelta(‘d‘, date, -60), datetime_helper.to_today()) # 提交查询,获取列表数据 # [{‘id‘: 101, ‘ip‘: ‘192.168.10.19‘, ‘ip_num‘: 1289500, ‘weekdays‘: 2, ‘state‘: ‘on‘}, {‘id‘: 100, ‘ip‘: ‘192.168.20.2‘, ‘ip_num‘: 2561000, ‘weekdays‘: 2, ‘state‘: ‘on‘}, ...] result = _pc_info_logic.select(sql) # 从查询结果列表中,提取ip_num与weekdays两个字段值,并组成list # [[1289500, 2], [2561000, 2], ...] ml_data = [[item[‘ip_num‘], item[‘weekdays‘]] for item in result] # 将最后一列值存储到标签集中(特征所对应的答案) # [‘on‘, ‘on‘, ‘on‘, ‘normal‘, ... ] ml_label = [item[‘state‘] for item in result] # 将数组转换为numpy数组,得到机器学习数据矩阵ml_data # [[1289500, 2] # [2561000, 2] # [1355000, 2] # ...] ml_data = numpy.array(ml_data) # 将数组中的值由字符串转为浮点型(int型数值如果不进行归一化处理,当数比较大时执行平方操作,会让值溢出越界,正数值变成负数值,产生错误) # [[1.2895e+06, 2.0000e+00] # [2.5610e+06, 2.0000e+00] # [1.3550e+06, 2.0000e+00] # ...] ml_data = ml_data.astype(float) # 到此,我们已获得机器学习需要使用到的数据矩阵ml_label以及对应的标签(答案)ml_label
对每个ip分别进行预测操作
从ip表中读取全部ip数据,对每个ip分别进行预测,将预测结果更新到状态表中
# 获取当前日期 date = datetime.datetime.now().date() # 检查当前时间是否为节假日 weekdays = get_weekdays(date) # 添加当天需要预测与记录的数据 if not _pc_on_off_state_logic.exists(‘date=‘{}‘‘.format(date)): _pc_on_off_state_logic.execute(‘insert into pc_on_off_state(date, pc_info_id, weekdays) select ‘{}‘, id, {} from pc_info‘.format(date, weekdays)) # 从ip表中读取全部ip数据 result = _pc_info_logic.get_list(is_return_list=True) # 对每个ip分别进行预测 for item in result: # 获取id、ip和ip值参数 id = item.get(‘id‘) ip = item.get(‘ip‘) ip_num = item.get(‘ip_num‘) # 组合成预测参数 # [1.299e+06, 7.000e+00] check_data = numpy.array([ip_num, weekdays]) check_data = check_data.astype(float) # 进行预测操作 label = knn_helper.knn_classify(ml_data, ml_label, check_data, 9) # 组合更新字段,更新预测结果 fields = { ‘calculate‘: string(label) } _pc_on_off_state_logic.edit(fields, ‘date=‘{}‘ and pc_info_id={}‘.format(date, id))
KNN算法实现
下面有两种完成KNN算法的代码,方法一利用python的特性简化的代码,方法二是对算法进行拆解说明的方法,代码实现主要参考: https://github.com/apachecn/AiLearning/blob/master/docs/ml/2.k-近邻算法.md 文档
# 实现方法一 def knn_classify(ml_data, ml_label, test_data, k): """ kNN分类算法函数 :param ml_data: 训练数据特征集(features) :param ml_label: 训练数据特征标签集(labels————特征集答案) :param test_data: 用于knn分类测试的数据 :param k: 选择最近邻的数目 :return: 返回knn算法预测的结果(所对应的标签值————分类值label) """ # 让预测参数矩阵(test_data)对每一个训练集矩阵(ml_data)相减,并求平方值(将负数转为正数), # 然后对矩阵中的值执行求和运算,得出每个训练集矩阵数据与预测参数矩阵的距离值 distances = numpy.sum((test_data - ml_data) ** 2, axis=1) # 将矩阵距离值(distances)从小到大排序,并提取其对应的index(索引),然后用索引值生成新的矩阵 # 只取出排在前k位的索引值,用于ml_label提取对应的标签 labels = [ml_label[index] for index in distances.argsort()[0: k]] # 使用Counter函数统计列表(labels)中,各标签出现的次数,并按从大到小排列, # 然后返回标签数最多的元素,将这个元素的标签返回给调用程序 return Counter(labels).most_common(1)[0][0] # 实现方法二 def knn_classify2(ml_data, ml_label, test_data, k): """ kNN分类算法函数 :param ml_data: 训练数据特征集(features) :param ml_label: 训练数据特征标签集(labels————特征集答案) :param test_data: 用于knn分类测试的数据 :param k: 选择最近邻的数目 :return: 返回knn算法预测的结果(所对应的标签值————分类值label) """ ### 1. 距离计算 # 获取训练集数据大小 data_size = ml_data.shape[0] # 使用numpy的tile函数,生成和训练样本对应的矩阵,并与训练样本求差 """ tile会将第一参数中的数组复制成指定数量的矩阵 比如:numpy.tile(test_data, (10, 1)) test_data = [1.299e+06, 7.000e+00] 当第二个参数为(5, 1)时,则表示会将创建一个行数为10的1维数组集,每一行等于test_data值的矩阵 即: result = [[1.299e+06, 7.000e+00], [1.299e+06, 7.000e+00], [1.299e+06, 7.000e+00], [1.299e+06, 7.000e+00], [1.299e+06, 7.000e+00]] numpy.tile(test_data, (data_size, 1)) 则会用test_data数据生成一个与ml_data一样大小的一个矩阵,用于与ml_data进行运算 """ data_tile = numpy.tile(test_data, (data_size, 1)) # 将测试数据test_data生成的矩阵与训练数据特征集数据ml_data相减,求两者的不同点 """ 比如训练集矩阵 ml_data = [[1.2895e+06, 2.0000e+00] [2.5610e+06, 2.0000e+00] [1.3550e+06, 2.0000e+00] [1.3615e+06, 2.0000e+00] [2.5720e+06, 2.0000e+00] [1.2815e+06, 2.0000e+00] ...] data_tile - ml_data = [[ 9.5000e+03, 5.0000e+00] [-1.2620e+06, 5.0000e+00] [-5.6000e+04, 5.0000e+00] [-6.2500e+04, 5.0000e+00] [-1.2730e+06, 5.0000e+00] [ 1.7500e+04, 5.0000e+00] ...] """ diff_mat = data_tile - ml_data # 矩阵相减计算出的结果求平方值 # 通过前面两个矩阵求差值后,得出的矩阵中的值有可能为负数,求平方是让结果全都变为正数,方便后面对结果进行比较与排序 """ # 对矩阵里的每个值都求平方,这些值可能会有点大,可以在前面做归一化处理,让这些值变小 diff_mat_square = [[9.02500000e+07, 2.50000000e+01] [1.59264400e+12, 2.50000000e+01] [3.13600000e+09, 2.50000000e+01] [3.90625000e+09, 2.50000000e+01] [1.62052900e+12, 2.50000000e+01] [3.06250000e+08, 2.50000000e+01] ...] """ diff_mat_square = numpy.square(diff_mat) # 将矩阵的每一行相加 """ 将预测参数矩阵与训练集矩阵求差求平方后,得出的结果再相加,这样就可以计算出预测参数与训练集中每个数据的距离(差距)值了,差距值越小,就表示与预测结果越相似 distances = [9.02500250e+07, 1.59264400e+12, 3.13600002e+09 ...] """ distances = diff_mat_square.sum(axis=1) # 根据距离排序从小到大的排序,返回对应的索引位置 """ argsort() 会将矩阵(distances)中的值从小到大排列,并提取其对应的index(索引),然后用索引值生成新的矩阵 例如: y = numpy.array([8,0,52,7,66,21,36]) 矩阵y使用argsort函数进行排序后,值为其值的索引组成的矩阵 y.argsort() = numpy.array([1,3,0,5,6,2,4]) 表示的是y[1] < y[3] < y[0] < y[5] < y[6] < y[2] < y[4] 即:0 < 7 < 8 < 21 < 36 < 52 < 66 使用distances.argsort()即表示,通过以上的计算,根据前面计算结果的相似度,生成了最相似的排序,排在最前面的验证码与测试验证码最相似 distances_sort = [4172, 3896, 4160, 388, 4048, 3038, 3097, 1035, 3141 ...] """ distances_sort = distances.argsort() ### 2. 从排序中,选取距离最小的k个点(选取与测试验证码最相似的k个训练数据) class_count = {} for i in range(k): # 从学习标签集(答案集)中提取最相似的标签值 label = ml_label[distances_sort[i]] # 通过字典累加的方式,统计最相似的各个标签数量 # class_count = {‘no_boot‘: 3, ‘on‘: 5, ‘normal‘: 1} 表示经过相似度计算,与测试相似的值中,no_boot有3个,on有5个,normal有1个 class_count[label] = class_count.get(label, 0) + 1 # 3. 将相似度统计结果从大到小进行排序 # class_count_sorted = [(‘on‘, 5), (‘no_boot‘, 3), (‘normal‘, 1)] class_count_sorted = sorted(class_count.items(), key=operator.itemgetter(1), reverse=True) # 返回第一个(数量最多)的标签 return class_count_sorted[0][0]
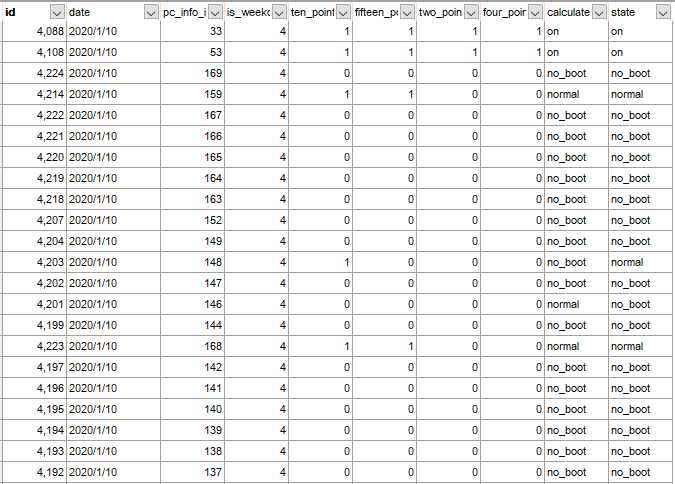
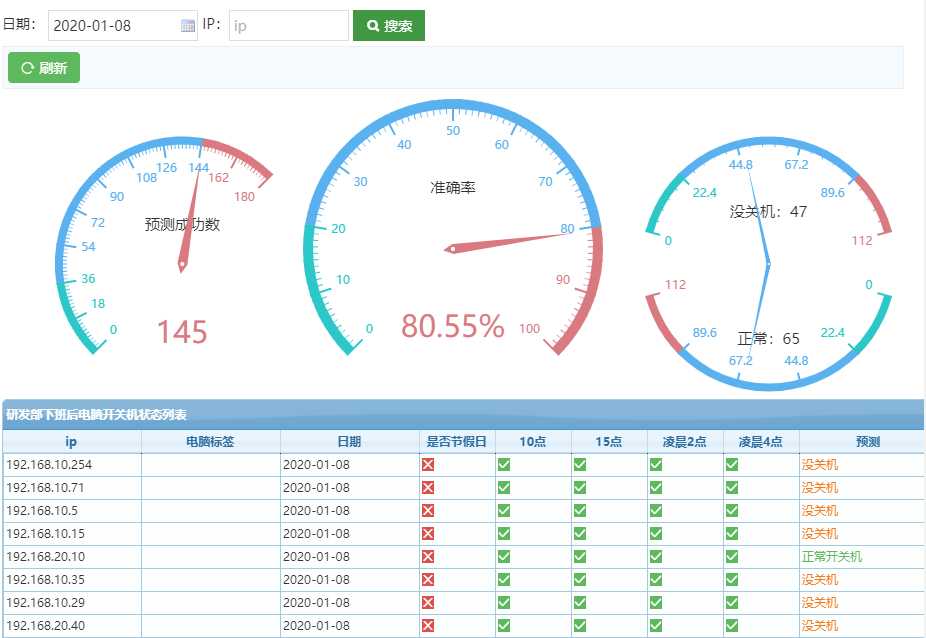
预测后数据表结果
3. KNN算法参数调优
完成开发以后,预测的准确率并不一定是最高的,需要调整算法的K值参数,以及对数据进行优化调整,才可能提升预测成功率。
K值的调整比较简单,只需要写一个脚本,通过调整K值的大小,对历史数据进行预测,并将预测结果与实际结果进行比较,计算出预测的准确率,然后汇总所有预测准确率计算其平均值,得出不同K值情况下,使用不同数量机器训练数据所预测出来的准确率,从中找出最优预测结果的参数,数据项与K值参数来使用。
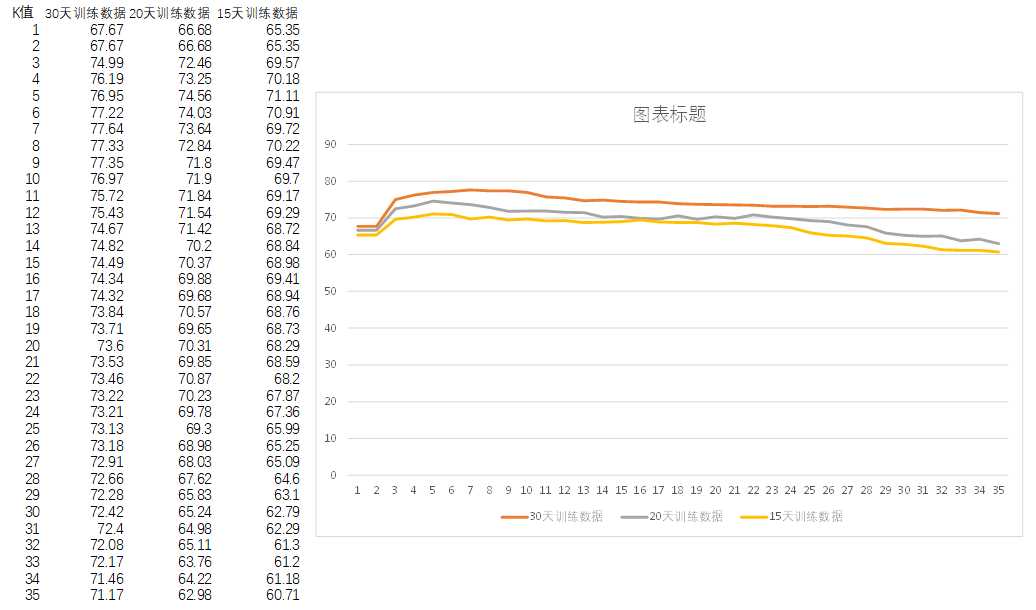
对于数据,需要对加工后的数据(KNN训练数据集)进行检查,查看里面的数据是否准确,是否存在问题,算法与规则是否符合要求。
比如这个例子中,weekdays值的变化,对预测结果有什么样的影响?对于节假日调休,对长期的预测准确率会有什么影响?ip转为int值后是否需要将ip之间拉开距离?拉开ip值与值距离的参数怎么设置?用10、50、100等值,会造成什么样的影响?为什么要用500?如果预测参数由两个变为更多时,这个值应该怎么设置?训练数据混杂在一块,对测试结果有什么影响?是否需要故意混杂这些数据,用于计算最近距离的数据有更多的可能性?在代码运行过程中,也需要通过debug或打印结果的方式进行查看分析,比如不使用浮点类型和归一化矩阵数据时,会有什么样的影响?对预测准确率有什么影响?如果一个ip使用很长时间后,不再使用或者某种习惯改变了,对于预测结果有什么样的影响?应该如何优化?参数应该如何设置才更加合理?
在算法参数调优时,需要多开动脑筋,多观察多思考多问为什么,这样才能及时发现问题,并对问题进行修正,多动手测试数据,才能找出最优的参数设置。
4. 其他例子
验证码识别与约会数据学习例子代码:
5. 参考资料
https://github.com/apachecn/AiLearning/blob/master/docs/ml/2.k-近邻算法.md
https://baike.baidu.com/item/k近邻算法/9512781?fr=aladdin
以上是关于机器学习(06)——K近附算法实战的主要内容,如果未能解决你的问题,请参考以下文章
机器学习实战☛k-近邻算法(K-Nearest Neighbor, KNN)