爬取哔哩哔哩全站所有投稿在 2020年03月09日 - 2020年03月12日 的播放前百视频
Posted syc0403
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬取哔哩哔哩全站所有投稿在 2020年03月09日 - 2020年03月12日 的播放前百视频相关的知识,希望对你有一定的参考价值。
#哔哩哔哩全站所有投稿在 2020年03月09日 - 2020年03月12日 的播放前百视频 #网页链接:https://www.bilibili.com/ranking?spm_id_from=333.851.b_7072696d61727950616765546162.3S import requests from bs4 import BeautifulSoup #发出request请求,获取html网页 response=requests.get(‘https://www.bilibili.com/ranking?spm_id_from=333.851.b_7072696d61727950616765546162.3S‘) response.text#获取源代码 html=response.text #解析网页,发现标题title和播放量data-box,提取内容 soup=BeautifulSoup(html,‘lxml‘)#构造Soup的对象 a=soup.find(‘a‘,class_=‘title‘)#python有关键词class了,要加_ res=soup.find_all(‘a‘,class_=‘title‘) #for循环提取a标签 num=0 text=‘‘ for i in res: num+=1 text+=‘{}{} ‘.format(num,i.string)#先把内容保存到变量里去 print(text) #保存 with open(‘rank.text‘,‘w‘,encoding=‘utf8‘)as fout: fout.write(text)
1.打开网页
2.获取源代码
3.解析网页,提取需要的内容,先找第一名的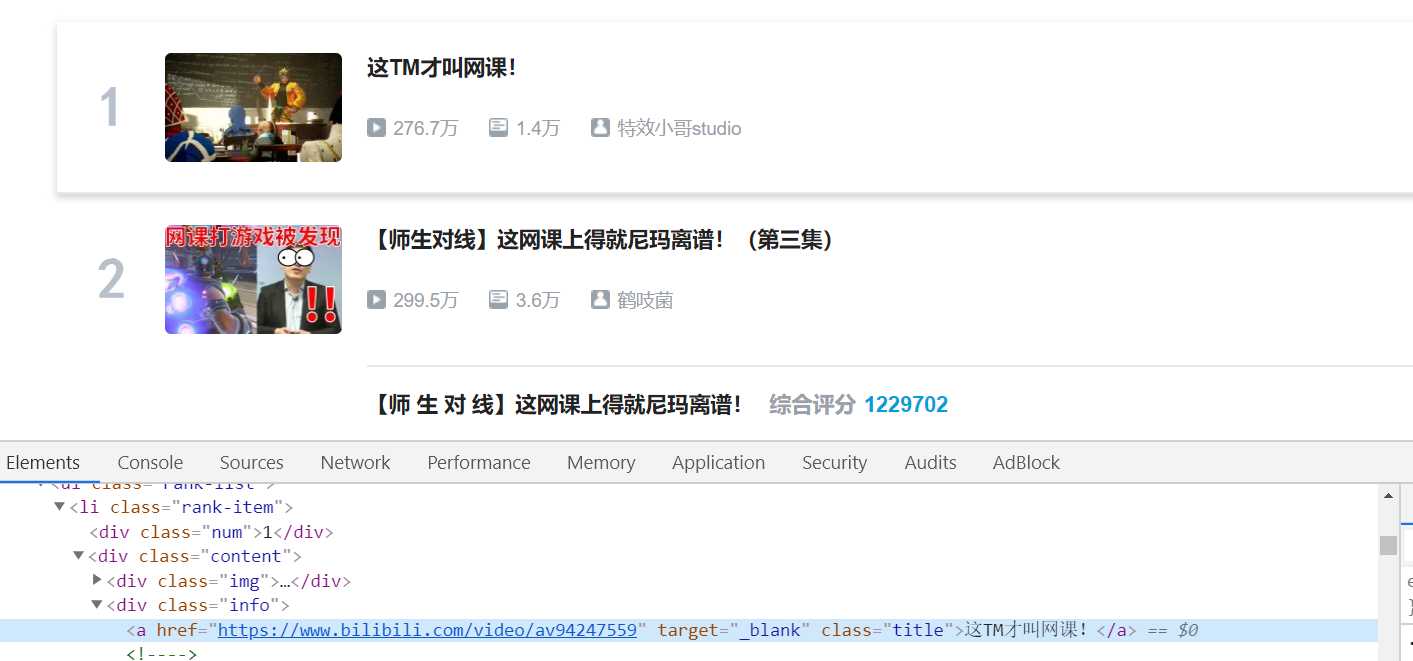
这里找到需要提取的标题a标签,分析特点,它的类是title,在代码中可以用find函数查找
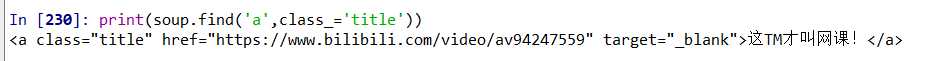
但是发现打印只能打出一条,所以改用另一条find_all函数

发现成功将排行榜爬取下来,想到可以用for循环把结果一个个打印出来

因为内容都是按顺序排下来的,所以可以自己弄数字形成排名

然后把内容保存到一个变量里去并检查有没有正常保存
最后直接保存到文件里面去,创建一个rank.txt,以写入的方式打开,把它赋值到fout这个变量里,fout写入获取到的文本内容

这里是全部代码
#哔哩哔哩全站所有投稿在 2020年03月09日 - 2020年03月12日 的播放前百视频
#网页链接:https://www.bilibili.com/ranking?spm_id_from=333.851.b_7072696d61727950616765546162.3S
import requests
from bs4 import BeautifulSoup
#发出request请求,获取html网页
response=requests.get(‘https://www.bilibili.com/ranking?spm_id_from=333.851.b_7072696d61727950616765546162.3S‘)
response.text#获取源代码
html=response.text
#解析网页,发现标题title和播放量data-box,提取内容
soup=BeautifulSoup(html,‘lxml‘)#构造Soup的对象
a=soup.find(‘a‘,class_=‘title‘)#python有关键词class了,要加_
res=soup.find_all(‘a‘,class_=‘title‘)
#for循环提取a标签
num=0
text=‘‘
for i in res:
num+=1
text+=‘{}{}
‘.format(num,i.string)#先把内容保存到变量里去
print(text)
#保存
with open(‘rank.text‘,‘w‘,encoding=‘utf8‘)as fout:
fout.write(text)
这是获取数据的截图

以上是关于爬取哔哩哔哩全站所有投稿在 2020年03月09日 - 2020年03月12日 的播放前百视频的主要内容,如果未能解决你的问题,请参考以下文章
爬虫使用线程池爬取哔哩哔哩数据,只能打印出一页的数据,加了锁也不行,如何修改呢?
Python+selenium 自媒体自动化 - 实现自动投稿自动发布哔哩哔哩B站短视频实例演示