爬虫使用线程池爬取哔哩哔哩数据,只能打印出一页的数据,加了锁也不行,如何修改呢?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬虫使用线程池爬取哔哩哔哩数据,只能打印出一页的数据,加了锁也不行,如何修改呢?相关的知识,希望对你有一定的参考价值。
import requests
from lxml import etree
import time
from multiprocessing.pool import ThreadPool
def spider(url):
headers =
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/87.0.4280.88 Safari/537.36'
resopnse = requests.get(url=url, headers=headers)
page_text = resopnse.text
tree = etree.HTML(page_text)
li_list = tree.xpath('//*[@id="all-list"]/div[1]/div[2]/ul[2]/li')
all_list=[]
for li in li_list:
data =[]
play_url='https:'+li.xpath('./a/@href')[0]
name=li.xpath('./div/div/a//text()')
name=''.join(name)
number=li.xpath('./div//div[@class="tags"]//text()')[0].strip()
publish_time=li.xpath('./div//div[@class="tags"]/span[3]//text()')[0].strip()
publisher=li.xpath('./div//div[@class="tags"]/span[4]//text()')[0]
data.append([play_url+name+number+publish_time+publisher])
all_list.append(data)
print(all_list)
if __name__ == '__main__':
urls=[]
for i in range(1,3):
url = f'https://search.bilibili.com/all?keyword=python&page=i'
urls.append(url)
# print(urls)
pool=ThreadPool(5)
pool.map(spider,urls)
pool.close()
pool.join()
爬虫。。。(哔哩哔哩)
零、目的:
掌握爬虫的使用方法,在B站上爬取出有用的信息来节省流量(bushi)
一、实现:
首先,进行了最初级的实验,将数据“爬”出来
代码如下: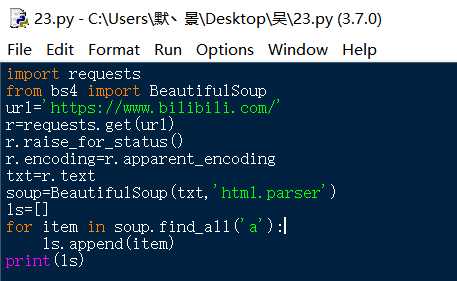
结果令人眼花缭乱》》》
二、改进:
于是乎,尝试将那些多余的标签什么的去掉,结果(= =)



不出所料,之前我掌握的数据处理技巧对这个数据类型“束手无策”

果真,一开始就上手这个看起来这么复杂的网站还是有一点难度的~~~~~~~~~~~~
三、总结:
学无止境,数据的大海在眼前,而我们只能在岸边捡捡贝壳。但我相信不断努力、学习进步,终有一天能中流击水,浪遏飞舟。
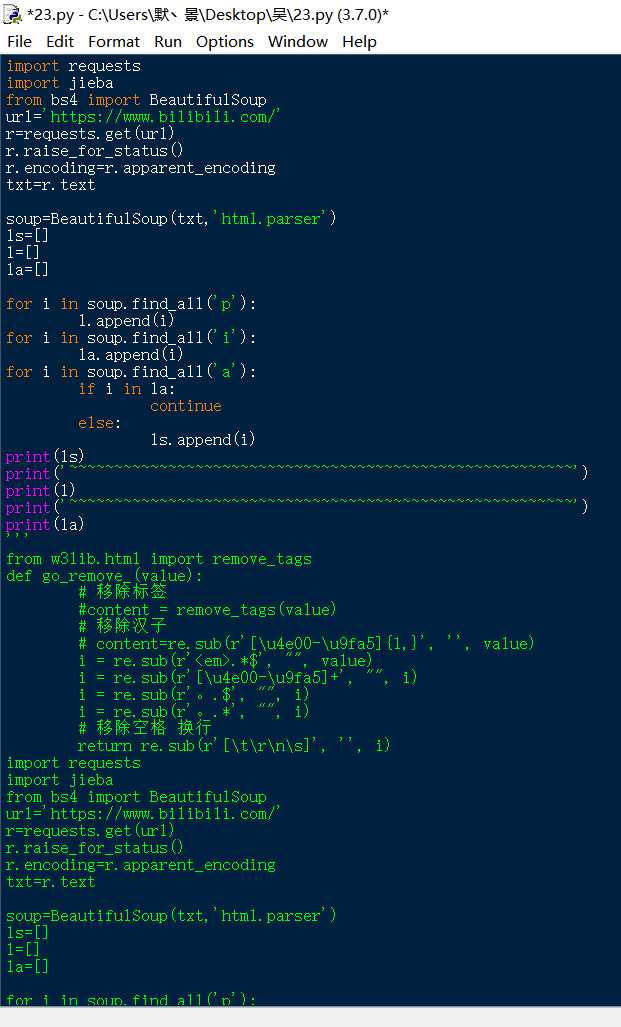 (失败的尝试)
(失败的尝试)

以上是关于爬虫使用线程池爬取哔哩哔哩数据,只能打印出一页的数据,加了锁也不行,如何修改呢?的主要内容,如果未能解决你的问题,请参考以下文章