YOLOv2(YOLO9000)
Posted ziwh666
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了YOLOv2(YOLO9000)相关的知识,希望对你有一定的参考价值。
OLOv2相对v1版本,在继续保持处理速度的基础上,从预测更准确(Better),速度更快(Faster),识别对象更多(Stronger)这三个方面进行了改进。其中识别更多对象也就是扩展到能够检测9000种不同对象,称之为YOLO9000。
下面具体看下YOLO2都做了哪些改进。
预测更准确(Better)
论文[1]中给出了下面的改进项目列表,列出各项改进对mAP的提升效果。

1)batch normalization(批归一化)
批归一化使mAP有2.4的提升。
批归一化有助于解决反向传播过程中的梯度消失和梯度爆炸问题,降低对一些超参数(比如学习率、网络参数的大小范围、激活函数的选择)的敏感性,并且每个batch分别进行归一化的时候,起到了一定的正则化效果(YOLO2不再使用dropout),从而能够获得更好的收敛速度和收敛效果。
通常,一次训练会输入一批样本(batch)进入神经网络。批规一化在神经网络的每一层,在网络(线性变换)输出后和激活函数(非线性变换)之前增加一个批归一化层(BN),BN层进行如下变换:①对该批样本的各特征量(对于中间层来说,就是每一个神经元)分别进行归一化处理,分别使每个特征的数据分布变换为均值0,方差1。从而使得每一批训练样本在每一层都有类似的分布。这一变换不需要引入额外的参数。②对上一步的输出再做一次线性变换,假设上一步的输出为Z,则Z1=γZ + β。这里γ、β是可以训练的参数。增加这一变换是因为上一步骤中强制改变了特征数据的分布,可能影响了原有数据的信息表达能力。增加的线性变换使其有机会恢复其原本的信息。
2)使用高分辨率图像微调分类模型
mAP提升了3.7。
图像分类的训练样本很多,而标注了边框的用于训练对象检测的样本相比而言就比较少了,因为标注边框的人工成本比较高。所以对象检测模型通常都先用图像分类样本训练卷积层,提取图像特征。但这引出的另一个问题是,图像分类样本的分辨率不是很高。所以YOLO v1使用ImageNet的图像分类样本采用 224*224 作为输入,来训练CNN卷积层。然后在训练对象检测时,检测用的图像样本采用更高分辨率的 448*448 的图像作为输入。但这样切换对模型性能有一定影响。
所以YOLO2在采用 224*224 图像进行分类模型预训练后,再采用 448*448 的高分辨率样本对分类模型进行微调(10个epoch),使网络特征逐渐适应 448*448 的分辨率。然后再使用 448*448 的检测样本进行训练,缓解了分辨率突然切换造成的影响。
3)采用先验框(Anchor Boxes)
召回率大幅提升到88%,同时mAP轻微下降了0.2。
借鉴Faster RCNN的做法,YOLO2也尝试采用先验框(anchor)。在每个grid预先设定一组不同大小和宽高比的边框,来覆盖整个图像的不同位置和多种尺度,这些先验框作为预定义的候选区在神经网络中将检测其中是否存在对象,以及微调边框的位置。
同时YOLO2移除了全连接层。另外去掉了一个池化层,使网络卷积层输出具有更高的分辨率。
之前YOLO1并没有采用先验框,并且每个grid只预测两个bounding box,整个图像98个。YOLO2如果每个grid采用9个先验框,总共有13*13*9=1521个先验框。所以,相对YOLO1的81%的召回率,YOLO2的召回率大幅提升到88%。同时mAP有0.2%的轻微下降。
不过YOLO2接着进一步对先验框进行了改良。
4)聚类提取先验框尺度
聚类提取先验框尺度,结合下面的约束预测边框的位置,使得mAP有4.8的提升。
之前先验框都是手工设定的,YOLO2尝试统计出更符合样本中对象尺寸的先验框,这样就可以减少网络微调先验框到实际位置的难度。YOLO2的做法是对训练集中标注的边框进行聚类分析,以寻找尽可能匹配样本的边框尺寸。
聚类算法最重要的是选择如何计算两个边框之间的“距离”,对于常用的欧式距离,大边框会产生更大的误差,但我们关心的是边框的IOU。所以,YOLO2在聚类时采用以下公式来计算两个边框之间的“距离”。
centroid是聚类时被选作中心的边框,box就是其它边框,d就是两者间的“距离”。IOU越大,“距离”越近。YOLO2给出的聚类分析结果如下图所示:

上图左边是选择不同的聚类k值情况下,得到的k个centroid边框,计算样本中标注的边框与各centroid的Avg IOU。显然,边框数k越多,Avg IOU越大。YOLO2选择k=5作为边框数量与IOU的折中。对比手工选择的先验框,使用5个聚类框即可达到61 Avg IOU,相当于9个手工设置的先验框60.9 Avg IOU。
上图右边显示了5种聚类得到的先验框,VOC和COCO数据集略有差异,不过都有较多的瘦高形边框。
5)约束预测边框的位置
借鉴于Faster RCNN的先验框方法,在训练的早期阶段,其位置预测容易不稳定。其位置预测公式为:
其中,
是预测边框的中心,
是先验框(anchor)的中心点坐标,
是先验框(anchor)的宽和高,
是要学习的参数。
注意,YOLO论文中写的是,根据Faster RCNN,应该是"+"。
由于的取值没有任何约束,因此预测边框的中心可能出现在任何位置,训练早期阶段不容易稳定。YOLO调整了预测公式,将预测边框的中心约束在特定gird网格内。
σ是sigmoid函数。
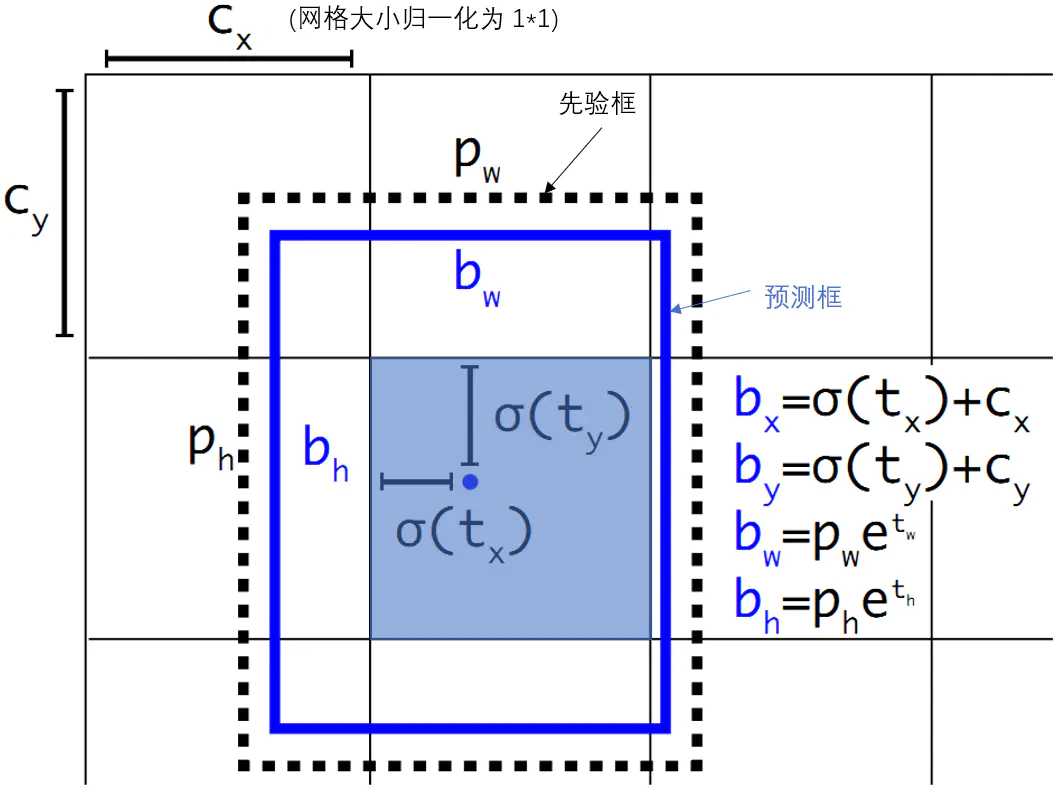
参考上图,由于σ函数将约束在(0,1)范围内,所以根据上面的计算公式,预测边框的蓝色中心点被约束在蓝色背景的网格内。约束边框位置使得模型更容易学习,且预测更为稳定。
6)passthrough层检测细粒度特征
passthrough层检测细粒度特征使mAP提升1。
对象检测面临的一个问题是图像中对象会有大有小,输入图像经过多层网络提取特征,最后输出的特征图中(比如YOLO2中输入416*416经过卷积网络下采样最后输出是13*13),较小的对象可能特征已经不明显甚至被忽略掉了。为了更好的检测出一些比较小的对象,最后输出的特征图需要保留一些更细节的信息。
YOLO2引入一种称为passthrough层的方法在特征图中保留一些细节信息。具体来说,就是在最后一个pooling之前,特征图的大小是26*26*512,将其1拆4,直接传递(passthrough)到pooling后(并且又经过一组卷积)的特征图,两者叠加到一起作为输出的特征图。

具体怎样1拆4,下面借用参考文章[3]中的一副图看的很清楚。图中示例的是1个4*4拆成4个2*2。因为深度不变,所以没有画出来。

另外,根据YOLO2的代码,特征图先用1*1卷积从 26*26*512 降维到 26*26*64,再做1拆4并passthrough。下面图6有更详细的网络输入输出结构。
7)多尺度图像训练
多尺度图像训练对mAP有1.4的提升。
因为去掉了全连接层,YOLO2可以输入任何尺寸的图像。因为整个网络下采样倍数是32,作者采用了{320,352,...,608}等10种输入图像的尺寸,这些尺寸的输入图像对应输出的特征图宽和高是{10,11,...19}。训练时每10个batch就随机更换一种尺寸,使网络能够适应各种大小的对象检测。
8)高分辨率图像的对象检测
图1表格中最后一行有个hi-res detector,使mAP提高了1.8。因为YOLO2调整网络结构后能够支持多种尺寸的输入图像。通常是使用416*416的输入图像,如果用较高分辨率的输入图像,比如544*544,则mAP可以达到78.6,有1.8的提升。
速度更快(Faster)
为了进一步提升速度,YOLO2提出了Darknet-19(有19个卷积层和5个MaxPooling层)网络结构。DarkNet-19比VGG-16小一些,精度不弱于VGG-16,但浮点运算量减少到约1/5,以保证更快的运算速度。

YOLO2的训练主要包括三个阶段。第一阶段就是先在ImageNet分类数据集上预训练Darknet-19,此时模型输入为 224*224 ,共训练160个epochs。然后第二阶段将网络的输入调整为 448*448 ,继续在ImageNet数据集上finetune分类模型,训练10个epochs,此时分类模型的top-1准确度为76.5%,而top-5准确度为93.3%。第三个阶段就是修改Darknet-19分类模型为检测模型,移除最后一个卷积层、global avgpooling层以及softmax层,并且新增了三个 3*3*1024卷积层,同时增加了一个passthrough层,最后使用 1*1 卷积层输出预测结果,输出的channels数为:num_anchors*(5+num_classes) ,和训练采用的数据集有关系。由于anchors数为5,对于VOC数据集(20种分类对象)输出的channels数就是125,最终的预测矩阵T的shape为 (batch_size, 13, 13, 125),可以先将其reshape为 (batch_size, 13, 13, 5, 25) ,其中 T[:, :, :, :, 0:4] 为边界框的位置和大小 ,T[:, :, :, :, 4] 为边界框的置信度,而 T[:, :, :, :, 5:] 为类别预测值。
对象检测模型各层的结构如下(参考文章[4]):

看一下passthrough层。图中第25层route 16,意思是来自16层的output,即26*26*512,这是passthrough层的来源(细粒度特征)。第26层1*1卷积降低通道数,从512降低到64(这一点论文在讨论passthrough的时候没有提到),输出26*26*64。第27层进行拆分(passthrough层)操作,1拆4分成13*13*256。第28层叠加27层和24层的输出,得到13*13*1280。后面再经过3*3卷积和1*1卷积,最后输出13*13*125。
YOLO2 输入->输出
综上所述,虽然YOLO2做出了一些改进,但总的来说网络结构依然很简单。就是一些卷积+pooling,从416*416*3 变换到 13*13*5*25。稍微大一点的变化是增加了batch normalization,增加了一个passthrough层,去掉了全连接层,以及采用了5个先验框。

对比YOLO1的输出张量,YOLO2的主要变化就是会输出5个先验框,且每个先验框都会尝试预测一个对象。输出的 13*13*5*25 张量中,25维向量包含 20个对象的分类概率+4个边框坐标+1个边框置信度。
YOLO2 误差函数
误差依然包括边框位置误差、置信度误差、对象分类误差。

公式中:
意思是预测边框中,与真实对象边框IOU最大的那个,其IOU<阈值Thresh,此系数为1,即计入误差,否则为0,不计入误差。YOLO2使用Thresh=0.6。
意思是前128000次迭代计入误差。注意这里是与先验框的误差,而不是与真实对象边框的误差。可能是为了在训练早期使模型更快学会先预测先验框的位置。
意思是该边框负责预测一个真实对象(边框内有对象)。
各种是不同类型误差的调节系数。
识别对象更多(Stronger)/ YOLO9000
VOC数据集可以检测20种对象,但实际上对象的种类非常多,只是缺少相应的用于对象检测的训练样本。YOLO2尝试利用ImageNet非常大量的分类样本,联合COCO的对象检测数据集一起训练,使得YOLO2即使没有学过很多对象的检测样本,也能检测出这些对象。
基本的思路是,如果是检测样本,训练时其Loss包括分类误差和定位误差,如果是分类样本,则Loss只包括分类误差。
1)构建WordTree
要检测更多对象,比如从原来的VOC的20种对象,扩展到ImageNet的9000种对象。简单来想的话,好像把原来输出20维的softmax改成9000维的softmax就可以了,但是,ImageNet的对象类别与COCO的对象类别不是互斥的。比如COCO对象类别有“狗”,而ImageNet细分成100多个品种的狗,狗与100多个狗的品种是包含关系,而不是互斥关系。一个Norfolk terrier同时也是dog,这样就不适合用单个softmax来做对象分类,而是要采用一种多标签分类模型。
YOLO2于是根据WordNet[5],将ImageNet和COCO中的名词对象一起构建了一个WordTree,以physical object为根节点,各名词依据相互间的关系构建树枝、树叶,节点间的连接表达了对象概念之间的蕴含关系(上位/下位关系)。

整个WordTree中的对象之间不是互斥的关系,但对于单个节点,属于它的所有子节点之间是互斥关系。比如terrier节点之下的Norfolk terrier、Yorkshire terrier、Bedlington terrier等,各品种的terrier之间是互斥的,所以计算上可以进行softmax操作。上面图10只画出了3个softmax作为示意,实际中每个节点下的所有子节点都会进行softmax。
2)WordTree的构建方法。
构建好的WordTree有9418个节点(对象类型),包括ImageNet的Top 9000个对象,COCO对象,以及ImageNet对象检测挑战数据集中的对象,以及为了添加这些对象,从WordNet路径中提取出的中间对象。
构建WordTree的步骤是:①检查每一个将用于训练和测试的ImageNet和COCO对象,在WordNet中找到对应的节点,如果该节点到WordTree根节点(physical object)的路径只有一条(大部分对象都只有一条路径),就将该路径添加到WrodTree。②经过上面操作后,剩下的是存在多条路径的对象。对每个对象,检查其额外路径长度(将其添加到已有的WordTree中所需的路径长度),选择最短的路径添加到WordTree。这样就构造好了整个WordTree。
3)WordTree如何表达对象的类别
之前对象互斥的情况下,用一个n维向量(n是预测对象的类别数)就可以表达一个对象(预测对象的那一维数值接近1,其它维数值接近0)。现在变成WordTree,如何表达一个对象呢?如果也是n维向量(这里WordTree有9418个节点(对象),即9418维向量),使预测的对象那一位为1,其它维都为0,这样的形式依然是互斥关系,这样是不合理的。合理的向量应该能够体现对象之间的蕴含关系。
比如一个样本图像,其标签是是"dog",那么显然dog节点的概率应该是1,然后,dog属于mammal,自然mammal的概率也是1,......一直沿路径向上到根节点physical object,所有经过的节点其概率都是1。参考上面图10,红色框内的节点概率都是1,其它节点概率为0。另一个样本假如标签是"Norfolk terrier",则从"Norfolk terrier"直到根节点的所有节点概率为1(图10中黄色框内的节点),其它节点概率为0。
所以,一个WordTree对应且仅对应一个对象,不过该对象节点到根节点的所有节点概率都是1,体现出对象之间的蕴含关系,而其它节点概率是0。
4)预测时如何确定一个WordTree所对应的对象
上面讲到训练时,有标签的样本对应的WordTree中,该对象节点到根节点的所有节点概率都是1,其它节点概率是0。那么用于预测时,如何根据WordTree各节点的概率值来确定其对应的对象呢?
根据训练标签的设置,其实模型学习的是各节点的条件概率。比如我们看WordTree(图10)中的一小段。假设一个样本标签是dog,那么dog=1,父节点mammal=1,同级节点cat=0,即P(dog|mammal)=1,P(cat|mammal)=0。
既然各节点预测的是条件概率,那么一个节点的绝对概率就是它到根节点路径上所有条件概率的乘积。比如
P(Norfolk terrier) = P(Norfolk terrier|terrier) * P(terrier|hunting dog) * P(hunting dog|dog) *......* P(animal|physical object) * P(physical object)
对于分类的计算,P(physical object) = 1。
不过,为了计算简便,实际中并不计算出所有节点的绝对概率。而是采用一种比较贪婪的算法。从根节点开始向下遍历,对每一个节点,在它的所有子节点中,选择概率最大的那个(一个节点下面的所有子节点是互斥的),一直向下遍历直到某个节点的子节点概率低于设定的阈值(意味着很难确定它的下一层对象到底是哪个),或达到叶子节点,那么该节点就是该WordTree对应的对象。
5)分类和检测联合训练
由于ImageNet样本比COCO多得多,所以对COCO样本会多做一些采样(oversampling),适当平衡一下样本数量,使两者样本数量比为4:1。
YOLO9000依然采用YOLO2的网络结构,不过5个先验框减少到3个先验框,以减少计算量。YOLO2的输出是13*13*5*(4+1+20),现在YOLO9000的输出是13*13*3*(4+1+9418)。假设输入是416*416*3。
由于对象分类改成WordTree的形式,相应的误差计算也需要一些调整。对一个检测样本,其分类误差只包含该标签节点以及到根节点的所有节点的误差。比如一个样本的标签是dog,那么dog往上标签都是1,但dog往下就不好设置了。因为这个dog其实必然也是某种具体的dog,假设它是一个Norfolk terrier,那么最符合实际的设置是从Norfolk terrier到根节点的标签都是1。但是因为样本没有告诉我们这是一个Norfolk terrier,只是说一个dog,那么从dog以下的标签就没法确定了。
对于分类样本,则只计算分类误差。YOLO9000总共会输出13*13*3=507个预测框(预测对象),计算它们对样本标签的预测概率,选择概率最大的那个框负责预测该样本的对象,即计算其WrodTree的误差。
另外论文中还有一句话,"We also assume that the predicted box overlaps what would be the ground truth label by at least .3 IOU and we backpropagate objectness loss based on this assumption."。感觉意思是其它那些边框,选择其中预测置信度>0.3的边框,作为分类的负样本(objectness)。即这些边框不应该有那么高的置信度来预测该样本对象。具体的就要看下代码了。
小结
总的来说,YOLO2通过一些改进明显提升了预测准确性,同时继续保持其运行速度快的优势。YOLO9000则开创性的提出联合使用分类样本和检测样本的训练方法,使对象检测能够扩展到缺乏检测样本的对象。
作者:X猪
链接:https://www.jianshu.com/p/517a1b344a88
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
以上是关于YOLOv2(YOLO9000)的主要内容,如果未能解决你的问题,请参考以下文章