wc.exe 功能实现
Posted suantouwangba
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了wc.exe 功能实现相关的知识,希望对你有一定的参考价值。
github 代码地址:https://github.com/1471104698/wc
1、题目描述
Word Count
1. 实现一个简单而完整的软件工具(源程序特征统计程序)。
2. 进行单元测试、回归测试、效能测试,在实现上述程序的过程中使用相关的工具。
3. 进行个人软件过程(PSP)的实践,逐步记录自己在每个软件工程环节花费的时间。
2、WC 项目要求
wc.exe 是一个常见的工具,它能统计文本文件的字符数、单词数和行数。这个项目要求写一个命令行程序,模仿已有wc.exe 的功能,并加以扩充,给出某程序设计语言源文件的字符数、单词数和行数。
实现一个统计程序,它能正确统计程序文件中的字符数、单词数、行数,以及还具备其他扩展功能,并能够快速地处理多个文件。
具体功能要求:
程序处理用户需求的模式为:
wc.exe [parameter] [file_name]
基本功能列表:
wc.exe -c file.c //返回文件 file.c 的字符数
wc.exe -w file.c //返回文件 file.c 的词的数目
wc.exe -l file.c //返回文件 file.c 的行数
扩展功能:
-s 递归处理目录下符合条件的文件。
-a 返回更复杂的数据(代码行 / 空行 / 注释行)。
空行:本行全部是空格或格式控制字符,如果包括代码,则只有不超过一个可显示的字符,例如“{”。
代码行:本行包括多于一个字符的代码。
注释行:本行不是代码行,并且本行包括注释。一个有趣的例子是有些程序员会在单字符后面加注释:
} //注释
在这种情况下,这一行属于注释行。
[file_name]: 文件或目录名,可以处理一般通配符。
高级功能:
-x 参数。这个参数单独使用。如果命令行有这个参数,则程序会显示图形界面,用户可以通过界面选取单个文件,程序就会显示文件的字符数、行数等全部统计信息。
需求举例:
wc.exe -s -a *.c
返回当前目录及子目录中所有*.c 文件的代码行数、空行数、注释行数。
3、具体代码
①、构造方法
//默认处理 .java 文件 private String suffixName = ".java"; /** * 构造方法 * @param suffixName 需要处理的文件后缀名 */ public WcTest(String suffixName){ this.suffixName = suffixName; } public WcTest(){ }
②、输入函数,也是对外开放主函数
这里主要做 Scanner 输入,并且其中 的 opStrsIsOk() 方法是对输入的命令行进行验证是否可用,该方法这里不做展开
为了后续处理方便,因此要求 -s 必须在 -w 之类的指令之前输入
/** * 对外开放主函数 */ public void input(){ Scanner scanner = new Scanner(System.in); do { System.out.println("命令行格式:wc [options] [filePath]"); System.out.println("ps:如需 -s 递归处理当前目录及其子目录,请输入目录路径"); System.out.println("退出输入:exit"); String inStr = scanner.nextLine(); if("exit".equals(inStr)){ break; } String[] opStrs = inStr.split("s+"); /* wc -c F:idea-workspace uangong1srccnoy estTest.java wc -s -c F:idea-workspace uangong1srccnoy est wc -c F:idea-workspace uangong1srccnoy estwcWcTest.java wc -c F:idea-workspace uangong1srccnoy estwc??????.java */ //前置检查:判断操作数组是否符合标准 if(!StringUtil.opStrsIsOk(opStrs)){ //异常处理,这里用输出代替 System.out.println("指令输入有误,请重新输入!!!"); continue; } try { if(!StringConstant.RECURSION_CHARACTER.equals(opStrs[1])){ op(opStrs); }else { recHandle(opStrs); } } catch (IOException e) { System.out.println("出现未知错误!!!"); } System.out.println("***********************************"); System.out.println("***********************************"); } while (true); }
③、文件操作函数,根据传进来的操作指令进行不同的处理
ps:这里使用的是 switch 对应不同的情况,扩展性较低,其实我是想建一个接口,然后每个处理都建一个类,继承该接口,然后使用 map 将 操作指令 和 类实例进行绑定,
之后就可以通过操作指令直接获取实例进行处理,这样后续新功能只需要添加一个类继承接口即可,无需动这里的代码,不过这里就没必要弄了
/** * 文件操作函数 * @param opStrs 操作字符串数组 * @throws IOException */ private void op(String[] opStrs) throws IOException { int pos = opStrs.length - 1; //如果文件类型不符合 if(!fileIsOk(opStrs[pos])){ //异常处理,这里用输出代替 System.out.println("文件格式错误"); return; } File file = new File(opStrs[pos]); //文件不存在 if(!file.exists()){ //判断是否满足通配符匹配,如果是从 -s 过来的,文件肯定是存在的,因此不会进入到这里的匹配阶段 if(!matchFileHandle(opStrs, file)){ //异常处理,这里用输出代替 System.out.println("文件不存在"); } return; } System.out.println("文件名:" + file.getName()); BufferedReader reader = null; // 如果是 -s 递归进来的,如 wc -s -c -a file.c ,那么就是 从 opStrs[2] 开始, // 如果是普通操作,如 -a、-c 那么从 opStrs[1] 开始 for(int i = StringConstant.RECURSION_CHARACTER.equals(opStrs[1]) ? 2 : 1; i < pos; i++){ /* 获取文件字符输出流 为什么需要写在这里? 而不是在 for 循环外面? 因为如果写在外面,那么所有操作都使用一个 reader,而第一个操作会持续 readLine() 将字符全部读完,导致其他操作的 readLine() 为空 因此,每一个操作都需要 重新获取一次 字符输出流 */ reader = StreamUtil.getReaderStream(file); switch (opStrs[i]){ case "-c": System.out.println("字符数:" + readFileCharacter(reader)); break; case "-w": System.out.println("单词数:" + readFileWord(reader)); break; case "-l": System.out.println("行数:" + readFileLine(reader)); break; case "-a": readFileSpecialLine(reader); default: break; } } //关闭流 StreamUtil.closeStream(reader); }
④、递归处理文件
先判断目录是否存在以及是否是文件,在通过 listFiles() 方法获取当前目录下的文件及目录,进行遍历,如果是文件,那么存储起来,如果是目录,那么 继续 dfs
目录处理完毕,那么就对文件统一进行处理,在这里为了保证进入上面的 文件操作函数 op() 是满足条件的文件,同时也是为了能够防止当前目录下没有满足条件的文件而输出那句 "当前目录:" 导致输出不可观,因此边遍历边进行判断
同时处理文件也很简单,直接将 操作指令数组的最后一个位置 的文件路径替换为当前文件的 path 即可
/** * 递归处理目录及子目录下的文件 * * 路径下的 / 和 是等价的 * @param opStrs 操作字符串 */ //wc -s -c file.c private void recHandle(String[] opStrs) throws IOException { int pos = opStrs.length - 1; //记录当前目录位置,防止因为后续修改而丢失 String curCatalog = opStrs[pos]; File file = new File(opStrs[pos]); //file.isFile() 能判断是否是文件 if(!file.exists() || file.isFile()){ //异常处理 System.out.println("目录错误 或 所选择路径不是一个目录"); } //获取子目录 File[] files = file.listFiles(); //判空 if(files != null){ List<File> fileList = new ArrayList<>(); for(File f : files){ //如果是文件那么将文件先存储起来 if(f.isFile()){ fileList.add(f); }else{ //将最后文件目录修改为子目录 opStrs[pos] = f.getPath(); recHandle(opStrs); } } boolean flag = false; //统一处理文件 for(File f : fileList){ //判断是否是 .java 文件,如果文件类型不符合,不进行处理 if(!fileIsOk(f.getPath())){ continue; } //该目录下有满足条件,即存在 java 文件的话,才输出目录,并且记录是否已经输出,保证只输出一次 if(!flag){ System.out.println("当前目录:" + curCatalog); } flag = true; opStrs[pos] = f.getPath(); op(opStrs); } } }
④、基本函数,没什么可说的
/** * 获取行数 * @param reader * @return * @throws IOException */ private int readFileLine(BufferedReader reader) throws IOException { int countLine = 0; while(reader.readLine() != null){ countLine++; } return countLine; } /** * 获取字符数 * @param reader * @return * @throws IOException */ private int readFileCharacter(BufferedReader reader) throws IOException { int countCharacter = 0; String str = ""; while((str = reader.readLine()) != null){ countCharacter += str.length(); } return countCharacter; } /** * 获取单词数 * @param reader * @return * @throws IOException */ private int readFileWord(BufferedReader reader) throws IOException { //使用正则进行分割:空格 Tab { } ;: ~ ! ? ^ % + - * / | & >> >>> << <<< [ ] ( ) int countWord = 0; String str = ""; while((str = reader.readLine()) != null){ //这里只使用部分符号,还有更多符号没有进行添加 countWord += str.split("s+|(|)|,|.|:|{|}|-|*|+|;|?|/|\\|/").length; } return countWord; } /** * 读取特殊行 * @param reader */ private void readFileSpecialLine(BufferedReader reader) throws IOException { // /* 注释行的情况: 单行注释:开头: 1、// 2、空格 + // 3、单个字符 + // 多行注释:开头:/* ,使用 flag 进行记录接下来内容是否属于该注释行的注释内容,直到找到 * / 为止 空行:1、空格 2、除空格外的,只有 1 个字符 代码行:不包括空格,至少有 2 个字符 */ List<String> noteList = Arrays.asList("//", "/*", "*/"); String oneNote = "//"; String moreNoteStart = "/*"; String moreNoteEnd = "*/"; int noteLine = 0; int trimLine = 0; int codeLine = 0; boolean flag = false; String str = ""; while ((str = reader.readLine()) != null){ str = str.trim(); if(str.length() < 2){ //空行,0 个字符或 1 个字符 trimLine++; }else if(oneNote.equals(str.substring(0, 2)) || str.length() > 2 && oneNote.equals(str.substring(1, 3))){ //单行注释 noteLine++; }else if(moreNoteStart.equals(str.substring(0, 2))){ //多行注释开头 noteLine++; //判断结尾标识符 */ 是否在当前行 if(!str.contains(moreNoteEnd)){ flag = true; } }else if(flag){ //是否仍是注释的范围 noteLine++; }else if(str.contains(moreNoteEnd)){ //该行是否是注释的结尾 noteLine++; flag = false; }else{ codeLine++; } } //wc -a F:idea-workspace uangong1srccnoy estwcT.java System.out.println("注释行:" + noteLine); System.out.println("空行:" + trimLine); System.out.println("代码行:" + codeLine); }
⑤、通配符匹配,这里使用动态规划进行文件名的匹配
具体过程:
1、第一个 函数 matchFileHandle() 是通配符匹配方法的 入口,里面最开始调用 isExistMatch() 判断文件名是否存在通配符 "*"、"?",如果不存在,那么可以直接返回了
2、获取当前文件的父目录下的所有文件,比如 当前文件是 F://a//b//c//x.txt,那么父目录就是 F://a//b//c,然后获取父目录下的所有文件,使用 isMatch() 方法,利用动态规划方法进行匹配,如果匹配成功,那么返回 true,证明该文件需要处理,否则跳过
/** * 查找目录下的通配符匹配文件,不包括递归,只遍历跟当前文件同目录的文件 * @param file */ private boolean matchFileHandle(String[] opStrs, File file) throws IOException { //得到当前文件名称 String fileName = file.getName(); //判断是否存在匹配通配符 if(!isExistMatch(fileName)){ return false; } //得到父路径 File parentFile = file.getParentFile(); //遍历父路径下的所有文件 File[] files = parentFile.listFiles(); if (files != null) { for(File f : files){ //判断是否匹配 if(isMatch(f.getName(), fileName)){ //修改文件路径 opStrs[opStrs.length - 1] = f.getPath(); op(opStrs); } } } return true; } /** * 判断文件名是否存在 ? 或 * 通配符 * @param fileName * @return */ private boolean isExistMatch(String fileName){ return fileName.contains("?") || fileName.contains("*"); } /** * 通配符匹配 ? 可表示任意单个字符, * 可以表示任意单个或多个字符,也可以表示空串 * s1 和 s2 是否匹配 * @param s * @param p * @return */ private boolean isMatch(String s, String p){ /* 输入:s = "aa" p = "a" 输出: false 解释: "a" 无法匹配 "aa" 整个字符串。 输入:s = "aa" p = "*" 输出: true 解释: ‘*‘ 可以匹配任意字符串。 使用动态规划 dp[i][j] 表示 s1 的前 i 个字符是否能被 s2 的前 j 个字符进行匹配 "" a d c e b "" T F F F F F * T T T T T T * T T T T T T a F T F F F F * F T T T T T b F F F F F T */ char[] ss = s.toCharArray(); char[] ps = p.toCharArray(); boolean[][] dp = new boolean[ss.length + 1][ps.length + 1]; //当 ss 和 ps 都只有 0 个字符的时候,那么匹配 dp[0][0] = true; //当 ss 为空串时,那么只有 ps 全部为 * 时才可以进行匹配(? 必须匹配单个字符,不能匹配空串) for(int i = 1; i <= ps.length; i++){ dp[0][i] = ps[i - 1] == ‘*‘ && dp[0][i - 1]; } for(int i = 1; i <= ss.length; i++){ for(int j = 1; j <= ps.length; j++){ if(ps[j - 1] == ‘?‘ || ps[j - 1] == ss[i - 1]){ //如果 ps 的当前字符为 ? 或者 ss 和 ps 当前字符相同,那么直接看两者上一个字符的匹配情况 dp[i][j] = dp[i - 1][j - 1]; }else if(ps[j - 1] == ‘*‘){ //如果 ps 当前字符为 *,那么有两种情况,匹配 ss 当前字符(该选择类似完全背包问题) 或者不匹配,即匹配空串 dp[i][j] = dp[i - 1][j] || dp[i][j - 1]; } } } return dp[ss.length][ps.length]; }
⑥、工具类之一,也是处理操作指令的方法
一看就懂
public class StringUtil { static List<String> opList = Arrays.asList("-a", "-c", "-l", "-w", "-s"); /** * 判断操作字符串数组是否符合标准 * @param opStrs * @return 当不符合标准时返回 false */ public static boolean opStrsIsOk(String[] opStrs){ //wc -c F:idea-workspace uangong1srccnoy estTest.java int len = opStrs.length; //1、操作数组长度不满足要求 if(len < StringConstant.OP_COMMON_MIN_LEN){ return false; } //2、首字符串不符合要求,即不为 "wc" if(!StringConstant.HEAD_CHARACTER.equals(opStrs[0])){ return false; } //3、最后一个元素不是目录而仍然是操作数 if(opList.contains(opStrs[len - 1])){ return false; } //4、递归标识符位置检查 以及 指令查重 、中间是否是操作数检查 if(!checkOp(opStrs)){ return false; } return true; } /** * 指令查重 以及 递归标识符 -s 可用性检查 * * @param opStrs * @return 指令有误返回 false */ private static boolean checkOp(String[] opStrs){ //是否出现其他操作符 boolean com_flag = false; //是否出现过递归标识符 boolean rec_flag = false; Set<String> set = new HashSet<>(); for(int i = 1; i < opStrs.length - 1; i++){ //出现重复指令 if(!set.add(opStrs[i])){ return false; } //出现递归标识符 -s if(StringConstant.RECURSION_CHARACTER.equals(opStrs[i])){ //在之前就出现了普通操作数,那么顺序不对 if(com_flag){ return false; }else{ rec_flag = true; } }else if(opList.contains(opStrs[i])){ //普通操作数 com_flag = true; }else { //如果什么都不是,即不是 -s、-c、-a 等指令 return false; } } //两个同时出现(在此已经保证了顺序的正确性,因为上面对顺序不正确的已经做了处理) 或者 只出现普通操作数 return rec_flag && com_flag || !rec_flag && com_flag; } /** * 判断是否是需要处理的文件类型 * @param fileName * @return */ public static boolean fileFilter(String fileName, String suffixName){ return fileName.endsWith(suffixName); } }
4、测试截图
测试类
package cn.oy.test; import cn.oy.test.utils.StringUtil; import cn.oy.test.wc.WcTest; import java.io.File; import java.io.IOException; import java.util.Scanner; /** * @author 蒜头王八 * @project: ruangong1 * @Description: * @Date 2020/3/14 22:43 */ public class Test { /** * 测试函数 * @param args */ public static void main(String[] args) throws IOException { WcTest wcTest = new WcTest(); wcTest.input(); // File file = new File("F:idea-workspace uangong1srccnoy estwcWcTest.java"); // System.out.println(file.getParentFile()); // System.out.println("//".split("//").length); } }
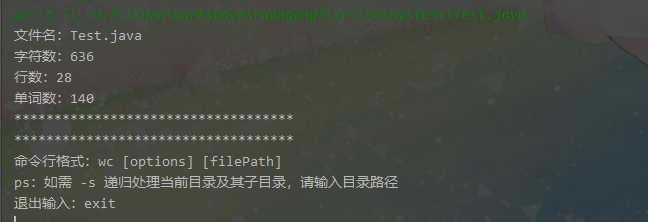
1、基本函数测试
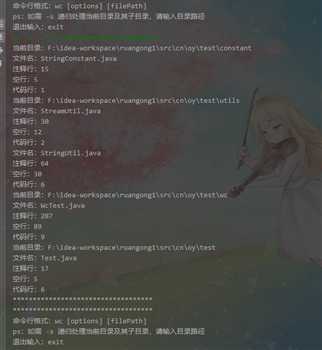
2、递归处理
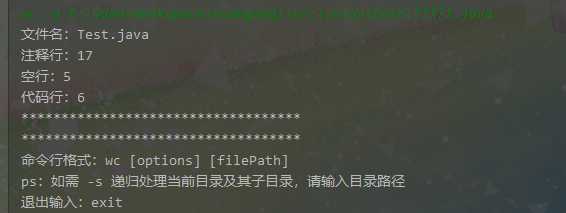
3、通配符处理
测试类为上述 Test.java
5、PSP表格
| PSP | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 15 | 20 |
| · Estimate | · 估计这个任务需要多少时间 | 15 | 20 |
| Development | 开发 | 200 | 250 |
| · Analysis | · 需求分析 (包括学习新技术) | 30 | 60 |
| · Design Spec | · 生成设计文档 | 10 | 10 |
| · Design Review | · 设计复审 (和同事审核设计文档) | 5 | 5 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 10 | 5 |
| · Design | · 具体设计 | 5 | 5 |
| · Coding | · 具体编码 | 30 | 15 |
| · Code Review | · 代码复审 | 10 | 5 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 20 | 10 |
| Reporting | 报告 | 30 | 60 |
| · Test Report | · 测试报告 | 10 | 20 |
| · Size Measurement | · 计算工作量 | 10 | 10 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 10 | 20 |
| 合计 | 195 | 260 |
6、项目总结
这是我第一次练习做项目,虽然功能尚不完善,但是仍还是满足基本需求,总结如下:
一、理论到实践需要一步步走,不是一步登天。
二、 PSP 表格可以让我们对自己能力有所了解,并规范自己。
三、此次练习我也发现了自己的不足,会努力进行改进
这是我第一次做完成的项目,虽然部分功能未完成,但也满足基本需求。这也是我第一次使用软件工程的方式完成项目。对此,有以下总结:
以上是关于wc.exe 功能实现的主要内容,如果未能解决你的问题,请参考以下文章