爬虫之Scrapy框架
Posted golanguage
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬虫之Scrapy框架相关的知识,希望对你有一定的参考价值。
- 框架:具有很强的通用性,且封装了一些通用实现方法的项目模板
scrapy(异步框架):- 高性能的网络请求
- 高性能的数据解析
- 高性能的持久化存储
- 高性能的全站数据爬取
- 高性能的深度爬取
- 高性能的分布式
Scrapy环境安装
ios和Linux
pip install scrapy
windows
a. pip3 install wheel
b. 下载twisted http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted
# Twisted?17.1.0?cp35?cp35m?win_amd64.whl; Python是3.5版本的就选择cp35下载
c. 进入下载目录,执行 pip3 install Twisted?17.1.0?cp35?cp35m?win_amd64.whl
# 安装失败可能是这个文件的版本导致的,即使Python版本都是对的,可以重新下载一个32位的试试
# 还安装失败的话就下载其python版本的,总有一个能成功
d. pip3 install pywin32
e. pip3 install scrapy
安装完成后,输入``scrapy`测试一下,出现如下图显示,即安装成功。
Scrapy的基本使用
创建工程
scrapy startprojct proNmamecd proNmame进入到工程目录下执行爬虫文件
proName # 工程名字
spiders # 爬虫包(文件夹)
__init__.py
__init__.py
items.py
middlewares.py
pipelines.py
settings.py # 创建好的工程的配置文件
scrapy.cfg # scrapy的配置文件,不用修改
创建爬虫文件
- 创建爬虫文件是py源文件
scrapy genspider spiderName www.xxx.com网址后期可以修改- 在
spiders包下创建一个py文件
- 在
# -*- coding: utf-8 -*-
import scrapy
class FirstSpider(scrapy.Spider): # scrapy.Spider所有爬虫类的父类
# name表示的爬虫文件的名称,当前爬虫文件的唯一标识
name = ‘first‘
# 允许的域名,通常会注释掉
# allowed_domains = [‘www.xx.com‘]
# 起始的url列表,最开始要爬的网址列表
# 作用:可以将内部的列表元素进行get请求的发送
start_urls = [‘http://www.sougou.com/‘,‘www.baidu.com‘]
# 调用parse方法解析数据,方法调用的次数由start_urls列表元素个数决定的
def parse(self, response): # response表示一个响应对象,
pass
基本配置
- UA伪装
- robots协议的不遵从
- 在
settings.py中将ROBOTSTXT_OBEY = True修改为False
- 在
- 指定日志等级
- 在
settings.py中添加LOG_LEVEL = ‘ERROR‘
- 在
执行工程
scrapy crawl spiderName- 执行工程是不展示日志文件
scrapy crawl spiderName --nolog- 这种方式下程序报错,不会展示;设置好日志等级后直接执行工程即可。
数据解析
response.xpath(‘xpath表达式‘)- 与
etree的不同之处:- 取文本/属性:返回的是一个
Selector对象,文本数据是存储在该对象中Selector对象[0].extract()返回字符串Selector对象.extract_first()返回字符串Selector对象.extract()返回列表
- 取文本/属性:返回的是一个
常用操作
- 如果列表只有一个元素用
Selector对象.extract_first(),返回字符串 - 如果列表有多个元素
Selector对象.extract(),返回列表,列表里装的是字符串
spiderName.py文件
# -*- coding: utf-8 -*-
import scrapy
class DuanziSpider(scrapy.Spider):
name = ‘first‘
# allowed_domains = [‘www.xx.com‘]
start_urls = [‘https://duanziwang.com/‘]
def parse(self, response):
article_list = response.xpath(‘/html/body/section/div/div/main/article‘) # 基于xpath表达式解析
for article in article_list:
title = article.xpath(‘./div[1]/h1/a/text()‘)[0] # 返回一个Selector对象
# <Selector xpath=‘./div[1]/h1/a/text()‘ data=‘关于健康养生、延年益寿的生活谚语_段子网收录最新段子‘>
title = article.xpath(‘./div[1]/h1/a/text()‘)[0].extract() # 返回字符串
# 关于健康养生、延年益寿的生活谚语_段子网收录最新段子
title = article.xpath(‘./div[1]/h1/a/text()‘).extract_first() # 返回字符串
# 关于健康养生、延年益寿的生活谚语_段子网收录最新段子
title = article.xpath(‘./div[1]/h1/a/text()‘).extract() # 返回列表
# [‘关于健康养生、延年益寿的生活谚语_段子网收录最新段子‘]
print(title)
break
持久化存储
基于终端指令的持久化存储
- 只可以将parse方法的返回值存储到指定后缀的文本文件中
- 指定后缀:
‘json‘, ‘jsonlines‘, ‘jl‘, ‘csv‘, ‘xml‘, ‘marshal‘, ‘pickle‘,通常用csv - 指令
scrapy crawl spiderName -o filePath
- 指定后缀:
案例:将文本数据持久化存储
# -*- coding: utf-8 -*-
import scrapy
class DuanziSpider(scrapy.Spider):
name = ‘duanzi‘
# allowed_domains = [‘www.xx.com‘]
start_urls = [‘https://duanziwang.com/‘]
# 基于终端指令的持久化存储
def parse(self, response):
article_list = response.xpath(‘/html/body/section/div/div/main/article‘) # 基于xpath表达式解析
all_data = []
for article in article_list:
title = article.xpath(‘./div[1]/h1/a/text()‘).extract_first()
content = article.xpath(‘./div[2]/p//text()‘).extract()
content = ‘‘.join(content)
dic = {
"title": title,
"content": content
}
all_data.append(dic)
return all_data
# 终端指令
# proNmame>scrapy crawl spiderName -o duanzi.csv
基于管道的持久化存储
? scrapy建议使用管道持久化存储
实现流程
-
数据解析(
spiderName .py) -
实例化item类型对象(
items.py)- 在
items.py的item类中定义相关的属性fieldNmae = scrapy.Field()
- 在
-
将解析的数据存储封装到item类型的对象中(
spiderName .py)item[‘fileName‘] = value给item对象的fieldNmae属性赋值
-
将item对象提交给(
spiderName .py)yield item将item提交给优先级最高的管道
-
在管道中接收item,可以将item中存储的数据进行任意形式的持久化存储(
pipelines.py)process_item():负责接收item对象且对其进行持久化存储
-
在配置文件
settings.py中开启管道机制- 找到如下代码,取消注释
ITEM_PIPELINES = { # 300表示的是优先级,数值越小,优先级越高 ‘duanziPro.pipelines.DuanziproPipeline‘: 300, }
案例:将文本数据持久化存储
按上述在settings.py找到管道代码,取消注释。
spiderName .py
# -*- coding: utf-8 -*-
import scrapy
from duanziPro.items import DuanziproItem
class FirstSpider(scrapy.Spider):
name = ‘duanzi‘
# allowed_domains = [‘www.xx.com‘]
start_urls = [‘https://duanziwang.com/‘]
# 基于管道的持久化存储
def parse(self, response):
article_list = response.xpath(‘/html/body/section/div/div/main/article‘) # 基于xpath表达式解析
for article in article_list:
title = article.xpath(‘./div[1]/h1/a/text()‘).extract_first()
content = article.xpath(‘./div[2]/pre/code//text()‘).extract()
content = ‘‘.join(content)
print(content)
# 实例化item对象
item = DuanziproItem()
# 通过中括号的形式访问属性给其赋值
item[‘title‘] = title
item[‘content‘] = content
# 向管道提交item
yield item
items.py
import scrapy
class DuanziproItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# 使用固有属性定义了两个属性
# Field是一个万能数据类型
title = scrapy.Field()
content = scrapy.Field()
pipelines.py
class DuanziproPipeline(object):
# 重写父类的该方法:该方法只会在爬虫开始的时候执行一次
fp = None
# 打开文件
def open_spider(self, spider):
print(‘open spider‘)
self.fp = open(‘./duanzi.txt‘, ‘w‘, encoding=‘utf-8‘)
# 关闭文件
def close_spider(self, spider):
print(‘close spider‘)
self.fp.close()
# 接收爬虫文件返回item对象,process_item方法每调用一次可接收一个item对象
# item参数:接收到的某一个item对象
def process_item(self, item, spider):
# 取值
title = item[‘title‘]
content = item[‘content‘]
self.fp.write(title + ":" + content + "
")
return item
管道存储细节处理
- 管道文件中的管道类表示的是什么?
- 一个管道类对应的就是一种存储形式(文本文件,数据库)
- 如果想要实现数据备份,则需要使用多个管道类(多种存储形式:mysql,Redis)
- process_item中的
retutn item:- 将item传递给下一个即将被执行(按照配置文件中ITEM_PIPELINES得权重排序)的管道类
存储到MySQL
在pipelines.py中添加如下代码
import pymysql
class MysqlPipeline(object):
conn = None
cursor = None
def open_spider(self, spider):
self.conn = pymysql.Connect(host=‘127.0.0.1‘, port=3306, user=‘root‘, password=‘123‘, db=‘spider‘,
charset=‘utf8‘)
def process_item(self, item, spider):
# 取值
title = item[‘title‘]
content = item[‘content‘]
self.cursor = self.conn.cursor()
# sql语句
sql = ‘insert into duanzi values ("%s","%s")‘ % (title, content)
try:
self.cursor.execute(sql)
self.conn.commit()
except Exception as e:
print(e)
self.conn.rollback()
return item
def close_spider(self, spider):
self.cursor.close()
self.conn.close()
在settings.py中将MysqlPipeline类注册到ITEM_PIPELINES中
ITEM_PIPELINES = {
# 300表示的是优先级,数值越小,优先级越高
‘duanziPro.pipelines.DuanziproPipeline‘: 300,
‘duanziPro.pipelines.MysqlPipeline‘: 301,
}
存储到Redis
- 如果报错:因为redis有的版本不支持存储字典,下载2.1.0.6版本
pip install redis==2.10.6
在pipelines.py中添加如下代码
from redis import Redis
class RedisPipeline(object):
conn = None
def open_spider(self, spider):
self.conn = Redis(host=‘127.0.0.1‘, port=6379, password=‘yourpassword‘)
def process_item(self, item, spider):
self.conn.lpush(‘duanziList‘, item)
# 报错:因为redis有的版本不支持存储字典,pip install redis==2.10.6
在settings.py中将RedisPipeline类注册到ITEM_PIPELINES中
ITEM_PIPELINES = {
# 300表示的是优先级,数值越小,优先级越高
‘duanziPro.pipelines.DuanziproPipeline‘: 300,
‘duanziPro.pipelines.RedisPipeline‘: 301,
}
手动发送请求
- 可以在start_urls这个列表中添加url,但是比较繁琐
- get请求发送
yield scrapy.Request(url,callback)- url:指定好请求的url
- callback:callback指定的回调函数一定会被执行(数据解析)
- post请求发送
yield scrapy.FormRequest(url,callback,formdata)
- 父类中start_requests请求发送的原理
# 简单模拟父类的方法,主要看yield
def start_requests(self):
for url in self.start_urls:
# 发起get请求
yield scrapy.Request(url=url,callback=self.parse)
# 发起get请求,formdat存放请求参数
yield scrapy.FormRequest(url=url,callback=self.parse,formdata={})
代码实现
-
主要是在
spiderName .py中使用递归方法,且明确递归结束的条件;使用父类yield实现全站爬取
# -*- coding: utf-8 -*-
import scrapy
from duanziPro.items import DuanziproItem
class DuanziSpider(scrapy.Spider):
name = ‘duanzi‘
# allowed_domains = [‘www.xx.com‘]
start_urls = [‘https://duanziwang.com/‘]
# 手动请求的发送,对其他页码的数据进行请求操作
# 定义通用url模板
url = "https://duanziwang.com/page/%d/"
pageNum = 2
def parse(self, response):
article_list = response.xpath(‘/html/body/section/div/div/main/article‘) # 基于xpath表达式解析
all_data = []
for article in article_list:
title = article.xpath(‘./div[1]/h1/a/text()‘).extract_first()
content = article.xpath(‘./div[2]/pre/code//text()‘).extract()
content = ‘‘.join(content)
# 实例化item对象
item = DuanziproItem()
# 通过中括号的形式访问属性给其赋值
item[‘title‘] = title
item[‘content‘] = content
# 向管道提交item
yield item
if self.pageNum < 5:
new_url = format(self.url%self.pageNum)
self.pageNum += 1
# 递归实现全站数据爬取,callback指定解析的方法
yield scrapy.Request(url=new_url, callback=self.parse)
- 在
pipelines.py中实现数据持久化存储
class DuanziproPipeline(object):
# 重写父类的该方法:该方法只会在爬虫开始的时候执行一次
fp = None
def open_spider(self, spider):
print(‘open spider‘)
self.fp = open(‘./duanzi.txt‘, ‘w‘, encoding=‘utf-8‘)
# 关闭fp
def close_spider(self, spider):
print(‘close spider‘)
self.fp.close()
# 接收爬虫文件返回item对象,process_item方法每调用一次可接收一个item对象
# item参数:接收到的某一个item对象
def process_item(self, item, spider):
# 取值
title = item[‘title‘]
content = item[‘content‘]
self.fp.write(title + ":" + content + "
")
# 将item转交给下一个即将被执行的管道类
return item
- 在
settings.py中开启管道类
ITEM_PIPELINES = {
# 300表示的是优先级,数值越小,优先级越高
‘duanziPro.pipelines.DuanziproPipeline‘: 300,
}
yield在scrapy中的使用
-
向管道中提交item对象
yield item
-
手动请求发送
yield scrapy.Request(url,callback)
五大核心组件
-
引擎(Scrapy Engine)
处理整个系统的数据流,触发事物(框架核心)。
-
调度器(Scheduer)
用来接收引擎发过来的请求,压入队列中,并在引擎再次请求的时候返回。
-
下载器(Downloader)
用于下载网页内容,并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效模型上的)。
-
爬虫(Spiders)
爬虫主要是干活的,用于从特定的网页中提取自己需要的信息,即所谓的实体(item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面
-
管道(item Pipeline)
负责处理爬虫从网页抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。
五大核心组件的工作流程
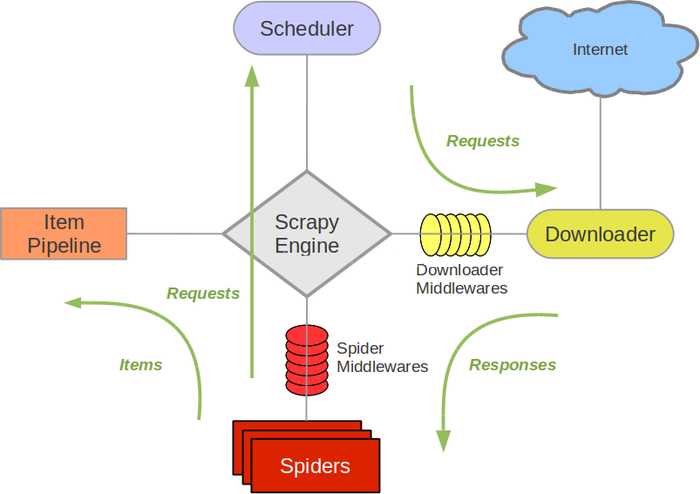
当执行爬虫文件时,5大核心组件就在工作了
首先执行爬虫文件spider,spider的作用是
(1)解析(2)发请求,原始的url存储在于spider中
1:当spider执行的时候,首先对起始的url发送请求,将起始url封装成请求对象
2:将请求对象传递给引擎
3:引擎将请求对象传递给调度器(内部含有队列和过滤器两个机制),调度器将请求存储在队列(先进先出)中
4:调度器从队列中调度出url的相应对象再将请求传递给引擎
5:引擎将请求对象通过下载中间件发送给下载器
6:下载器拿到请求到互联网上去下载
7:互联网将下载好的数据封装到响应对象给到下载器
8:下载器将响应对象通过下载中间件发送给引擎
9:引擎将封装了数据的响应对象回传给spider类parse方法中的response对象
10:spider中的parse方法被调用,response就有了响应值
11:在spider的parse方法中进行解析代码的编写;
(1)会解析出另外一批url,(2)会解析出相关的文本数据
12: 将解析拿到的数据封装到item中
13:item将封装的文本数据提交给引擎
14:引擎将数据提交给管道进行持久化存储(一次完整的请求数据)
15:如果parder方法中解析到的另外一批url想继续提交可以继续手动进行发请求
16:spider将这批请求对象封装提交给引擎
17:引擎将这批请求对象发配给调度器
16:这批url通过调度器中过滤器过滤掉重复的url存储在调度器的队列中
17:调度器再将这批请求对象进行请求的调度发送给引擎
引擎作用:
1:处理流数据 2:触发事物
引擎根据相互的数据流做判断,根据拿到的流数据进行下一步组件中方法的调用
下载中间件: 位于引擎和下载器之间,可以拦截请求和响应对象;拦截到请求和响应对象后可以
篡改页面内容和请求和响应头信息。
爬虫中间件:位于spider和引擎之间,也可以拦截请求和响应对象,不常用。
未完待续...
以上是关于爬虫之Scrapy框架的主要内容,如果未能解决你的问题,请参考以下文章