人脸真伪验证与识别:ICCV2019论文解析
Posted wujianming-110117
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了人脸真伪验证与识别:ICCV2019论文解析相关的知识,希望对你有一定的参考价值。
人脸真伪验证与识别:ICCV2019论文解析
Face Forensics++: Learning to Detect Manipulated Facial Images

论文链接:
摘要
合成图像生成和处理技术的迅速发展,使人们对其对社会的影响产生了极大的关注。充其量,这会导致人们对数字内容失去信任,但通过传播虚假信息或虚假新闻,可能会造成进一步的伤害。本文探讨了最先进的图像处理技术的现实性,以及自动或由人类检测它们的困难。 为了规范检测方法的评估,本文提出了一个自动的面部操作检测基准。特别是,基准是基于DeepFakes[1]、Face2Face[56]、FaceSwap[2]和NeuralTextures[54]作为随机压缩级别和大小的面部操作的突出代表。基准测试是公开可用的,它包含一个隐藏的测试集以及一个包含超过180万个操作图像的数据库。这个数据集比可比的、公开的、伪造的数据集大一个数量级以上。基于这些数据,本文对数据驱动的伪造检测器进行了深入的分析。本文表明,使用额外的领域特定知识可以将伪造检测提高到前所未有的准确度,即使在强压缩的情况下也是如此,并且明显优于人类观察者。
1. Introduction
目前的面部操作方法可分为两类:面部表情操作和面部身份操作(见图2)。最突出的面部表情操作技术之一是Thies等人[56]的方法,称为面到面。它只使用商品硬件就能实时地将一个人的面部表情传送给另一个人。后续的工作,如“合成奥巴马”[52]能够根据音频输入序列对人的面部进行动画制作。
本文的论文做出了以下贡献:
•一个用于在随机压缩下进行标准化比较的面部操作检测的自动基准,包括人类基准, •一个由180多万张来自1000个视频,包含原始(即真实)源和目标地面真相,以实现监督学习,
•广泛评估各种情况下最先进的手工制作和学习的伪造探测器,
•最先进的伪造检测方法,专门针对面部操作。
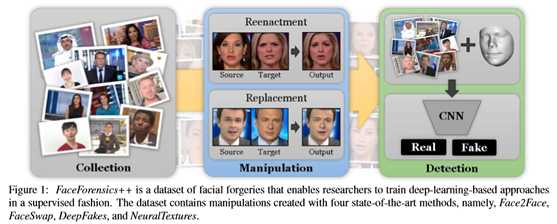

2. Related Work
Face Manipulation Methods
近年来,人们提出了几种基于深度学习的人脸图像合成方法。Lu等人。[45]概述。生成性对抗网络(GANs)用于应用面部老化[6],生成新视角[33],或改变面部属性,如肤色[44]。深度特征插值[59]在改变人脸属性(如年龄、胡子、微笑等)方面显示了令人印象深刻的结果。属性插值的类似结果由Fader网络实现[41]。这些基于深度学习的图像合成技术大多存在图像分辨率低的问题。最近,Karras等人。[36]利用GANs的渐进生长提高了图像质量,产生了高质量的人脸合成。
Multimedia Forensics
其他一些工作明确提到检测与人脸相关的操作,例如区分计算机生成的人脸和自然人脸[21、14、49]、变形的人脸[48]、人脸拼接[23、22]、人脸交换[62、37],还有深赝品[4,42,32]。对于面部操作检测,一些方法利用合成过程中产生的特定伪影,例如眨眼[42],或颜色、纹理和形状提示[23、22]。其他的工作更一般,并提出了一个深度网络训练,以捕捉由低级和/或高级特征引起的微妙不一致[48,62,37,4,32]。这些方法显示了令人印象深刻的结果,然而健壮性问题通常仍然没有得到解决,尽管它们对于实际应用至关重要。例如,压缩和调整大小之类的操作因清洗数据中的操作痕迹而闻名。在现实场景中,当图像和视频上传到社交媒体(这是法医分析最重要的应用领域之一)时,这些基本操作是标准的。为此,本文的数据集被设计用来覆盖这些现实场景,即来自野外的视频,以不同的质量级别进行操作和压缩(见第3节)。这样一个庞大而多样的数据集的可用性可以帮助研究人员对他们的方法进行基准测试,并为面部图像开发更好的伪造检测器。
Forensic Analysis Datasets
鉴证分析数据集:经典的鉴证数据集是在非常可控的条件下,通过大量的人工操作创建的,以分离像相机伪影一样的数据的特定属性。虽然有人提出了一些数据集,其中包括图像处理,但只有少数数据集也涉及到视频片段的重要情况。例如,MICC F2000是一个图像拷贝移动操作数据集,由700个来自不同来源的伪造图像组成[5]。第一个IEEE图像取证挑战数据集包括1176个伪造图像;包含90个来自Web的真实操作案例的Wild Web数据集[61]和包含220个伪造图像的真实篡改数据集[40]。Zhou等人[62]提出了一个2010年FaceSwap和SwapMe生成图像的数据库。最近,Korshunov和Marcel[39]为43名受试者构建了一个由多个视频创建的620个深度赝品视频的数据集。美国国家标准与技术研究所(NIST)发布了最广泛的通用图像处理数据集,其中包括约5万张伪造图像(包括本地和全球操作)和约500个伪造视频[31]。相反,本文构建了一个包含1个以上的数据库。4000个假视频中的800万张图片——比现有数据集高出一个数量级。本文在第四节评估了如此庞大的训练语料库的重要性。
3. Large-Scale Facial Forgery Database
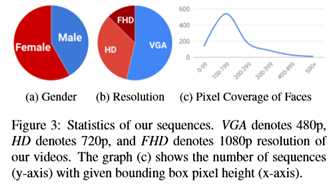
本文的一个核心贡献是本文的FaceForensics++数据集扩展了初步的FaceForensics数据集 [50]。这个新的大规模数据集使本文能够训练一个最先进的伪造检测器,以监督的方式进行面部图像处理(见第4节)。为此,本文利用四种最先进的自动面部操作方法,这些方法应用于从互联网上下载的1000个原始视频(统计数据见图3)。为了模拟真实的场景,本文选择了在野外收集视频,特别是从YouTube上。然而,早期对所有操纵方法的实验表明,为了防止操纵方法失败或产生强伪影,目标脸必须接近正面。因此,本文对生成的剪辑执行手动筛选,以确保高质量的视频选择,并避免视频与面部遮挡。本文选择了1000个包含509914幅图像的视频序列作为原始数据。为了生成一个大规模的操作数据库,本文采用了最先进的视频编辑方法来完全自动工作。在下面的段落中,本文将简要介绍这些方法。对于本文的数据集,本文选择了两种基于计算机图形的方法(Face2Face和FaceSwap)和两种基于学习的方法(DeepFakes和NeuralTextures)。所有四种方法都需要源和目标参与者视频对作为输入。每种方法的最终输出是由生成的图像组成的视频。除了操作输出外,本文还计算了指示像素是否被修改的地面真值掩码,可以用来训练伪造定位方法。有关更多信息和超参数,请参阅补充材料。
FaceSwap
FaceSwap是一种基于图形的方法,用于将人脸区域从源视频传输到目标视频。基于稀疏检测到的人脸标志,提取人脸区域。利用这些标志,该方法使用混合图形建立了一个三维模板模型。该模型利用输入图像的纹理,通过最小化投影形状和局部地标之间的差异,实现对目标图像的反投影。最后,将渲染模型与图像融合,并进行颜色校正。本文对所有源帧和目标帧对执行这些步骤,直到一个视频结束。该实现在计算上是轻量级的,并且可以在CPU上高效地运行。
Deepfakes
Deepfakes一词已经广泛地成为基于深度学习的面部置换的同义词,但它也是通过在线论坛传播的一种特殊操作方法的名称。为了区分这些,本文在下面的文章中用深度赝品来表示这种方法。有各种各样的DeepFakes公共实现可用,最显著的是FakeApp[3]和faceswap github[1]。将目标序列中的面替换为在源视频或图像集合中观察到的面。该方法基于两个具有共享编码器的自动编码器,分别训练用于重建源人脸和目标人脸的训练图像。人脸检测器用于裁剪和对齐图像。为了产生一幅假图像,将训练好的源人脸编解码器应用到目标人脸上。然后使用Poisson图像编辑将自动编码器输出与图像的其余部分混合[47]。对于本文的数据集,本文使用faceswap github实现。本文用一个完全自动化的数据加载器替换手动的训练数据选择,从而稍微修改了实现。本文使用默认参数来训练视频对模型。由于这些模型的训练非常耗时,本文还将模型作为数据集的一部分发布。这有助于通过不同的后处理对这些人产生额外的操作。
Face2Face
Face2Face[56]是一个面部再现系统,它将源视频的表达式传输到目标视频,同时保持目标人的身份。最初的实现是基于两个视频输入流,使用手动关键帧选择。这些帧用于生成一个密集的人脸重建,可用于在不同的光照和表情下重新合成人脸。为了处理本文的视频数据库,本文采用Face2Face方法来完全自动创建重生成操作。本文在预处理过程中处理每个视频;在这里,本文使用第一帧以获得临时的面部身份(即3D模型),并在剩余帧上跟踪表达式。为了选择该方法所需的关键帧,本文自动选择具有面的最左和最右角度的帧。基于这种身份重建,本文跟踪整个视频,以计算每帧的表达式、刚性姿势和照明参数,就像在最初的Face2Face实现中一样。本文通过将每个帧的源表达式参数(即76个混合形状系数)传输到目标视频来生成再现视频输出。有关再制造过程的更多细节,请参阅原始文件[56]。
NeuralTextures
Thies等人 [54]以面部重建为例,说明基于神经纹理的绘制方法。它利用原始视频数据学习目标人的神经纹理,包括一个渲染网络。这是训练与光度重建损失与对抗性损失相结合。在本文的实现中,本文应用了Pix2Pix【35】中使用的基于补丁的GAN损耗。Neuratextures方法依赖于列车和测试期间使用的跟踪几何结构。本文使用Face2Face的跟踪模块来生成这些信息。本文只修改与嘴区域相对应的面部表情,即眼睛区域保持不变(否则渲染网络将需要类似于深视频肖像的眼睛运动的条件输入[38])。
Postprocessing-Video Quality
为了给被操纵的视频创建一个真实的设置,本文生成不同质量级别的输出视频,类似于许多社交网络的视频处理。由于原始视频很少在互联网上找到,本文使用H.264编解码器压缩视频,这被社交网络或视频共享网站广泛使用。为了生成高质量的视频,本文使用HQ(恒定速率量化参数等于23)表示的视觉上几乎无损的光压缩。低质量视频(LQ)使用40的量化产生。
4. Forgery Detection
本文将伪造检测问题归结为被操纵视频的每帧二进制分类问题。以下各节显示了手动和自动伪造检测的结果。对于所有实验,本文将数据集分成固定的训练、验证和测试集,分别由720、140和140个视频组成。使用测试集中的视频报告所有评估。对于所有的图表,本文在补充材料中列出了确切的数字。
4.1. Forgery Detection of Human Observers
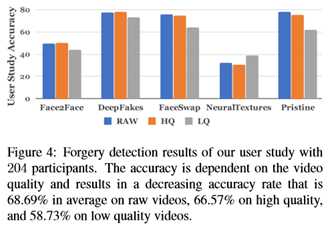
为了评估人类在伪造检测任务中的表现,本文对204名参与者进行了一项用户研究,参与者主要是计算机科学大学的学生。这形成了自动伪造检测方法的基线。 Layout of the User Study
在简单介绍了二进制任务之后,用户被要求对从本文的测试集中随机选择的图像进行分类。所选图像在图像质量和操作方法上都有所不同;本文使用50:50的原始图像和伪图像分割。由于检查图像的时间量可能很重要,为了模拟用户在社交媒体上每个图像只花费有限时间的场景,本文随机设置了2、4或6秒的时间限制,然后隐藏图像。之后,用户被问到显示的图像是“真实的”还是“假的”。为了确保用户在检查上花费可用的时间,在图像显示后而不是在观察期间询问问题。本文将研究设计为每个参与者只需几分钟,每个参与者展示60张图片,这就产生了12240个人类决策的集合。
请注意,用户研究包含了所有四种操作方法的假图像和原始图像。在这种情况下,面部和神经组织结构尤其难以被人类观察者发现,因为它们没有引入强烈的语义变化,与面部置换方法相比,只引入了细微的视觉伪影。神经纹理似乎特别难以检测,因为人类的检测精度低于随机概率,而且只会在具有挑战性的低质量任务中增加。
4.2. Automatic Forgery Detection Methods
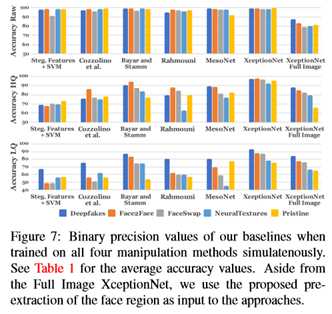
本文的伪造检测管道如图5所示。由于本文的目标是检测面部图像的伪造,因此本文使用了可以从输入序列中提取的额外域特定信息。为此,本文使用了Thies等人[56]最先进的人脸跟踪方法。跟踪视频中的面部并提取图像的面部区域。本文使用保守的crop(扩大1.3倍) 围绕被跟踪面的中心,包围重建的面。领域知识的整合 与使用整个图像作为输入的朴素方法相比,改进了伪造检测器的总体性能(参见第4.2.2节)。本文使用不同的最新分类方法评估了本文方法的各种变体。本文正在考虑在医学界使用基于学习的方法进行通用操作检测[9,16]、计算机生成的与自然图像检测[49]和人脸篡改检测[4]。此外,本文还表明基于ExceptionNet[13]的分类在检测假货方面优于所有其他变体。
4.2.1 Detection based on Steganalysis Features
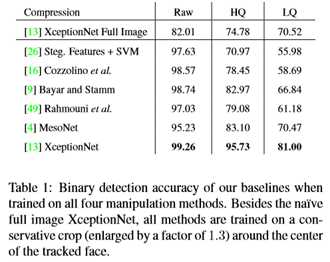
本文根据Fridrich等人[26]的方法,从隐写分析特征中评估检测。采用手工制作的特征。这些特征在高通图像上沿水平和垂直方向共出现在4个像素图案上,总特征长度为162。然后利用这些特征训练线性支持向量机(SVM)分类器。这项技术是第一次IEEE图像鉴证挑战赛的制胜方法[15]。本文提供一个128×128的中心裁剪作为方法的输入。虽然手工制作的方法在原始图像上的精确度大大超过了人类,但它很难处理压缩,这导致低质量视频的精确度低于人类的性能(见图6和表1)。
4.2.2 Detection based on Learned Features
为了从学习到的特征中进行检测,本文评估了文献中已知的五种网络架构,以解决分类任务:
(1) Cozzolino等人 [16] 将前一节手工制作的隐写分析功能投射到基于CNN的网络中。本文在本文的大规模数据集上精确地调整这个网络。
(2) 本文使用本文的数据集训练Bayar和Stamm[9]提出的卷积神经网络,该网络使用一个约束卷积层,然后是两个卷积层、两个最大池和三个完全连接层。约束卷积层被专门设计来抑制图像的高层次内容。与前面的方法类似,本文使用中心128×128裁剪作为输入。
(3) Rahmouni等人 [49]采用不同的CNN架构,具有计算四个统计数据(平均值、方差、最大值和最小值)的全局池层。本文认为Stats-2L网络性能最好。 (4) MesoInception-4[4]是一个基于CNN的网络,灵感来源于InceptionNet[53],用于检测视频中的人脸篡改。该网络有两个初始模块和两个经典卷积层与最大池层交错。之后,有两个完全连接的层。在经典交叉熵损失的基础上,提出了真标签和预测标签的均方误差。本文将人脸图像的大小调整为256×256,这是网络的输入。 (5) XceptionNet[13]是一种基于残差连接可分离卷积的传统CNN。本文通过用两个输出替换最终的完全连接层来将其转移到本文的任务中。其他层用ImageNet权重初始化。为了建立新插入的完全连接层,本文将所有权值乘以最终层,并对网络进行3个阶段的预训练。在这一步之后,本文对网络进行了15个阶段的训练,并根据验证精度选择了性能最佳的模型。有关本文的培训和超参数的详细说明,请参阅补充文件。
Comparison of our Forgery Detection Variants
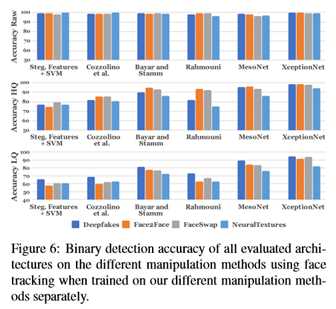
图6示出了使用在所有四种操作方法上分别评估的所有网络架构以及在不同视频质量水平下的二进制伪造检测任务的结果。所有的方法都能在原始输入数据上获得很高的性能。压缩视频的性能下降,特别是手工制作的功能和浅层CNN架构[9,16]。神经网络能够更好地处理这些情况,ExceptionNet能够在弱压缩上取得令人信服的结果,同时在低质量图像上保持合理的性能,因为它得益于ImageNet上的预训练以及更大的网络容量。为了将用户研究的结果与自动检测器的性能进行比较,本文还测试了包含所有操作方法的图像的数据集上的检测变量。图7和表1显示了完整数据集上的结果。在这里,本文的自动探测器在很大程度上优于人类的性能(参见图4)。本文还评估了在完整图像上操作的朴素伪造检测器(调整为ExceptionNet输入),而不是使用面部跟踪信息(见图7,最右边的列)。由于缺乏特定领域的信息,ExceptionNet分类程序在这种情况下的准确度明显较低。总而言之,域特定信息与ExceptionNet分类相结合显示了每次测试中的最佳性能。本文使用这个网络来进一步了解训练语料大小的影响及其区分不同操作方法的能力。
Forgery Detection of GAN-based methods
实验表明,所有的检测方法在基于GAN的神经提取方法上都达到了较低的检测精度。neuraltexture为每一种操作训练一个独特的模型,这将导致可能的伪影的更高的变化。尽管DeepFakes也在为每次操作训练一个模型,但它使用了一个固定的后处理管道,类似于基于计算机的操作方法,因此具有一致的工件。
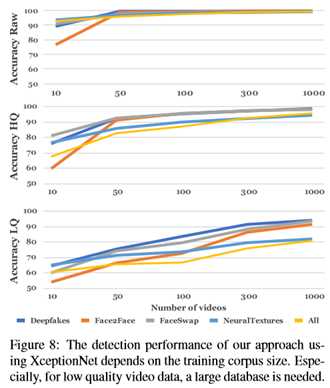
Evaluation of the Training Corpus Size
图8显示了训练语料大小的重要性。为此,本文分别在三个视频质量级别上训练了具有不同训练语料大小的ExceptionNet分类器。总体性能随着训练图像数量的增加而增加,这对于低质量视频片段尤其重要,如图底部所示。

5. Benchmark
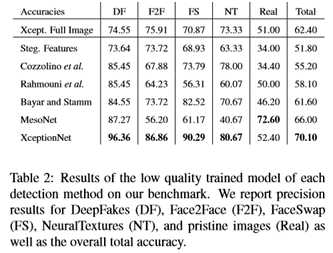
除了本文的大规模操作数据库,本文还发布了一个有竞争力的面部伪造检测基准。为此,本文收集了1000个额外的视频,并以与第3节中四种操作方法相似的方式操作其中的一个子集。由于上传的视频(例如,到社交网络)将以各种方式进行后处理,因此本文多次隐藏所有选定的视频(例如,通过未知的重新调整大小、压缩方法和比特率),以确保真实条件。此处理直接应用于原始视频。最后,在视觉检测的基础上,从每个视频中手动选择一个具有挑战性的帧。具体来说,本文收集了一组1000张图片,每张图片都是从操作方法或原始镜头中随机拍摄的。请注意,本文不一定有一个等分的原始和假图像,也不一定有一个等分使用的操作方法。地面真值标签隐藏在主机服务器上,用于评估提交模型的分类精度。自动基准允许一个提交者每两周提交一次,以防止过度提交(类似于现有基准[18])。作为基准,本文在基准上评估本文以前训练过的模型的低质量版本,并分别报告每种检测方法的数量(见表2)。除了全图像异常网络外,本文还将提出的人脸区域预提取方法作为输入。分类模型的相对性能与本文的数据库测试集相似(见表1)。但是,由于基准场景偏离了训练数据库,模型的整体性能较低,特别是对于原始图像的检测精度;主要的变化是随机质量水平以及测试过程中可能出现的跟踪误差。由于本文提出的方法依赖于人脸检测,因此本文在跟踪失败的情况下,将假作为默认值进行预测。该基准已经向社会公开,本文希望它能导致后续工作的标准化比较。
6. Discussion & Conclusion
虽然目前最先进的面部图像处理方法显示出惊人的视觉效果,但本文证明,它们可以被训练的伪造检测器检测到。尤其令人鼓舞的是,基于学习的方法也可以解决低质量视频的挑战性问题,在这种方法中,人类和手工制作的功能表现出困难。为了利用领域特定知识训练检测器,本文引入了一个新的人工人脸视频数据集,其数量超过了所有现有的公开的法医数据集一个数量级。在本文中,本文关注压缩对最新操作方法可检测性的影响,提出了后续工作的标准化基准。所有的图像数据、经过训练的模型以及本文的基准都是公开的,并且已经被其他研究人员使用。特别是,转移学习在法医学界具有很高的兴趣。随着新的操纵方法的出现,必须开发出能够在几乎没有训练数据的情况下检测出假货的方法。本文的数据库已经用于这个法医学转移学习任务,其中一个源操作域的知识转移到另一个目标域,如Cozzolino等人[17]所示。本文希望数据集和基准成为数字媒体取证领域未来研究的垫脚石,特别是关注面部伪造。
以上是关于人脸真伪验证与识别:ICCV2019论文解析的主要内容,如果未能解决你的问题,请参考以下文章
python基于tensorflow的人脸识别系统设计与实现.zip(论文+源码)
CVPR-2020 AAAI2020 CVPR-2019 NIPS-2019 ICCV-2019 IJCAI-2019 论文超级大合集下载,整理好累,拿走不谢
#ICCV2019论文阅读#Fully_convolutional_Features