《繁凡的论文精读》CVPR 2019 基于决策的高效人脸识别黑盒对抗攻击(清华朱军)
Posted 繁凡さん
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《繁凡的论文精读》CVPR 2019 基于决策的高效人脸识别黑盒对抗攻击(清华朱军)相关的知识,希望对你有一定的参考价值。
《繁凡的深度学习笔记》,包含深度学习基础和 TensorFlow2.0,PyTorch 详解,以及 CNN,RNN,GNN,AE,GAN,Transformer,强化学习,元学习,对抗攻击防御,迁移学习等主流研究方向万字综述!
文章目录
Efficient Decision-based Black-box Adversarial Attacks on Face Recognition [1]
基于决策的高效人脸识别黑盒对抗攻击
Abstract
Face recognition has obtained remarkable progress in recent years due to the great improvement of deep convolutional neural networks (CNNs). However, deep CNNs are vulnerable to adversarial examples, which can cause fateful consequences in real-world face recognition applications with security-sensitive purposes. Adversarial attacks are widely studied as they can identify the vulnerability of the models before they are deployed. In this paper, we evaluate the robustness of state-of-the-art face recognition models in the decision-based black-box attack setting, where the attackers have no access to the model parameters and gradients, but can only acquire hard-label predictions by sending queries to the target model. This attack setting is more practical in real-world face recognition systems. To improve the efficiency of previous methods, we propose an evolutionary attack algorithm, which can model the local geometry of the search directions and reduce the dimension of the search space. Extensive experiments demonstrate the effectiveness of the proposed method that induces a minimum perturbation to an input face image with fewer queries. We also apply the proposed method to attack a real-world face recognition system successfully.
Translation
近年来,由于深度卷积神经网络(CNN)的巨大改进,人脸识别取得了显着进展。然而,深度 CNN 容易受到对抗性示例的影响,这可能会在具有安全敏感目的的现实世界人脸识别应用程序中造成致命的后果。对抗性攻击被广泛研究,因为它们可以在部署之前识别模型的漏洞。在本文中,我们评估了最先进的人脸识别模型在基于决策的黑盒攻击设置中的鲁棒性,其中攻击者无法访问模型参数和梯度,而只能获取硬标签通过向目标模型发送查询来进行预测。这种攻击设置在现实世界的人脸识别系统中更实用。为了提高先前方法的效率,我们提出了一种进化攻击算法,该算法可以**对搜索方向的局部几何形状进行建模并降低搜索空间的维度。**大量实验证明了所提出方法的有效性,该方法以较少的查询对输入人脸图像产生最小扰动。我们还应用所提出的方法成功地攻击了现实世界的人脸识别系统。
Summarize
- 提出了一种进化攻击算法来在基于决策的黑盒设置中生成对抗样本。
- 通过对搜索方向的局部几何形状进行建模,同时降低搜索空间的维度,从而提高了效率。
- 应用所提出的方法来综合研究几种最先进的人脸识别模型的鲁棒性。
- 表明现有的人脸识别模型极易受到黑盒方式的对抗性攻击。
- 通过所提出的方法攻击了现实世界的人脸识别系统,证明了其实际适用性。
0x01 论文总结
1. Introduction
人脸识别通常有两个子任务:
-
人脸验证
- 区分一对人脸图像是否代表同一身份。
-
人脸识别
- 将一个图像分类为一个身份。
最先进的人脸识别模型通过使用深度神经网络提取类内方差最小和类间方差最大的人脸特征来实现这两个任务。
现有的人脸识别攻击方法[24,25]主要基于白盒场景,攻击者知道被攻击系统的内部结构和参数。因此,可以通过基于梯度的方法直接优化攻击目标函数。我们关注的是一个更加现实和通用的基于决策的黑盒设置[1],其中没有模型信息被暴露,除了攻击者只能查询目标模型并获得相应的硬标签预测。攻击的目标是通过有限的查询生成具有最小扰动的对抗性例子。这种攻击场景更具挑战性,因为无法直接计算梯度,也无法提供预测概率。另一方面,它更加现实和重要,因为大多数现实世界的人脸识别系统都是黑盒的,只提供硬标签输出。
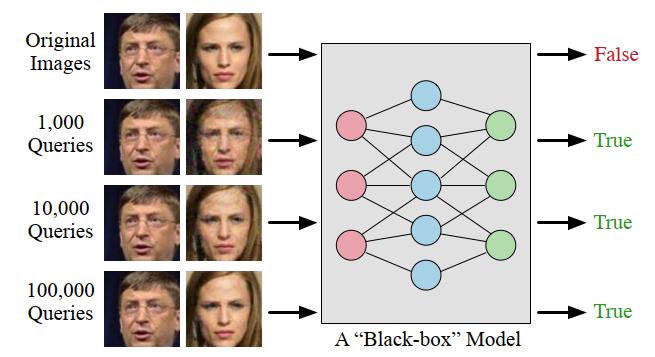
图1. 基于决策的黑盒攻击设置的演示。给定一个黑盒模型,攻击者使用查询生成具有最小扰动的对抗性示例。
已有多种基于决策的黑盒攻击方法被提出[1,14,4]。然而,它们通常需要大量查询才能收敛从而缺乏效率,或者在有限的查询预算下只能获得扰动相对较大的对抗性示例。因此,我们考虑如何通过用更少的查询对每个样本引入更小的扰动来有效地生成基于决策的黑盒攻击的对抗示例。
- 在基于决策的黑盒场景下,我们提出了一种新的进化攻击方法,它可以模拟搜索方向的局部几何形状,同时降低搜索空间的维数。进化攻击方法一般适用于任何图像识别任务,并且相对于现有方法显著提高了效率。
- 我们通过各种环境下基于决策的黑盒攻击,全面评估了几种最先进的人脸识别模型的鲁棒性。我们展示了这些人脸模型在这种环境下的脆弱性。
- 通过成功攻击一个真实世界的人脸识别系统,我们展示了所提出方法的实际适用性。
2.Related Work
深度人脸识别 DeepFace[31]和DeepID[28]将人脸识别视为一个多类分类问题,并使用深度CNNs来学习softmax loss监督的特征。提出了三重损失[23]和中心损失[33]来增加类别之间的特征空间中的欧几里德余量。在SphereFace [16]中提出了角度软最大损失来学习角度分辨特征。CosFace [32]使用大裕度余弦损失来最大化余弦裕度。ArcFace[5]中提出了附加角裕度损失来学习高分辨特征。
对人脸识别的对抗性攻击 深层CNNs极易受到对抗性例子的影响[30,9,19]。人脸识别也显示出抵抗攻击的脆弱性。在[24]中,扰动被限制在眼镜区域,并由基于梯度的方法生成,这甚至在物理世界中也欺骗了人脸识别系统。敌对的眼镜也可以由生殖网络产生[25]。然而,这些方法依赖于人脸识别模型的白盒操作,这在现实世界的应用中是不现实的。相反,我们着重于评估人脸识别模型在基于决策的黑盒攻击环境中的鲁棒性。
黑盒攻击 黑盒攻击可以分为基于转移、基于分数和基于决策的攻击。基于转移的攻击为白盒模型生成对立的例子,并基于可转移性攻击黑盒模型[17,6]。在基于分数的攻击中,预测概率由模型给出。有几种方法依靠近似梯度来产生对立的例子[3,14]。在基于决策的攻击中,我们只能获得硬标签预测。边界攻击法是基于决策边界上的随机游走[1]。基于优化的方法[4]将该问题表述为连续优化问题,并估计用于优化的梯度。然而,它需要计算沿二分搜索法方向到决策边界的距离。在[14]中,预测概率是通过硬标签预测来估计的。然后,使用自然进化策略(NES)来最大化目标类概率或最小化真实类概率。这些方法通常需要大量的查询来生成具有最小扰动的对抗性例子,或者用很少的查询收敛到大的扰动。
3.Methodology
3.1.Attack Setting
设 f ( x ) : X → Y ( X ⊂ R n ) f(\\boldsymbolx): \\mathcalX \\rightarrow \\mathcalY\\left(\\mathcalX \\subset \\mathbbR^n\\right) f(x):X→Y(X⊂Rn) 表示预测输入人脸图像标签的人脸识别模型。
对于人脸验证,该模型依靠另一张人脸图像来识别这对图像是否属于同一身份,并输出一个 Y = 0 , 1 Y = \\0,1\\ Y=0,1 的二进制标签。
对于人脸识别,模型 f ( x ) f(x) f(x) 将输入图像 x x x 与人脸图像图库集进行比较,然后将 x x x 分类为特定身份。所以可以看作是多类分类任务,其中 Y = 1 , 2 , . . . , K Y = \\1,2,...,K\\ Y=1,2,...,K, K K K 为恒等式个数。
给定一个真实的人脸图像
x
x
x ,攻击的目标是在
x
x
x 附近生成一个敌对的人脸图像
x
∗
x^*
x∗ ,但是被模型错误分类。它可以通过求解一个约束优化问题
min
x
∗
D
(
x
∗
,
x
)
,
s.t.
C
(
f
(
x
∗
)
)
=
1
\\min _x^* \\mathcalD\\left(\\boldsymbolx^*, \\boldsymbolx\\right), \\text s.t. \\mathcalC\\left(f\\left(\\boldsymbolx^*\\right)\\right)=1
x∗minD(x∗,x), s.t. C(f(x∗))=1
得到,其中
D
(
⋅
,
⋅
)
\\mathcal D(·,·)
D(⋅,⋅) 是距离度量,
C
(
⋅
)
\\mathcal C(·)
C(⋅) 是一个对抗准则,如果满足攻击要求,取
1
1
1,否则取
0
0
0。我们使用
ℓ
2
\\ell_2
ℓ2 距离作为
D
\\mathcal D
D。
E
q
.
(
1
)
Eq.(1)
Eq.(1) 中的约束问题显然可以等价地重新表述为以下无约束优化问题:
min
x
∗
L
(
x
∗
)
=
D
(
x
∗
,
x
)
+
δ
(
C
(
f
(
x
∗
)
)
=
1
)
\\min _\\boldsymbolx^* \\mathcalL\\left(\\boldsymbolx^*\\right)=\\mathcalD\\left(\\boldsymbolx^*, \\boldsymbolx\\right)+\\delta\\left(\\mathcalC\\left(f\\left(\\boldsymbolx^*\\right)\\right)=1\\right)
x∗minL(x∗)=D(x∗,x)+δ(C(f(x∗))=1)
其中,如果
a
a
a 为真,则
δ
(
a
)
=
0
\\delta(a)=0
δ(a)=0 ,否则
δ
(
a
)
=
+
∞
\\delta(a)=+\\infin
δ(a)=+∞ 。
通过优化 E q . ( 2 ) Eq. (2) Eq.(2),我们可以得到一个扰动最小的图像 x ∗ x^* x∗ ,根据对抗准则显然它也是有对抗性的。
由于模型 f ( x ) f(x) f(x) 仅提供离散的硬标签输出,因此对抗准则 C \\mathcal C C 不能定义为交叉熵损失等连续的准则。
我们根据以下两种类型的攻击来指定 C \\mathcal C C 。
❑ ❑ ❑ 躲避攻击(Dodging Attack,非目标攻击)
产生一个被认为是错误的或不被承认的对抗性图像。
对于人脸验证,给定一对属于同一身份的人脸图像,攻击者希望通过修改其中一张图像,使模型识别它们不是同一身份。
准则
C
\\mathcal C
C 为:
C
(
f
(
x
∗
,
x
)
)
=
I
(
f
(
x
∗
,
x
)
=
0
)
\\mathcalC\\left(f\\left(\\boldsymbolx^*,\\boldsymbol x\\right)\\right)=\\mathbbI\\left(f\\left(\\boldsymbolx^*,\\boldsymbol x\\right)=0\\right)
C(f(x∗,x))=I(f(x∗,x)=0)
其中
I
\\mathbbI
I 是指示函数。
I
A
(
x
)
=
1
若
x
∈
A
0
若
x
∉
A
\\mathbbI_A(x)=\\left\\\\beginarrayll1 & \\text 若 x \\in A \\\\0 & \\text 若 x \\notin A\\endarray\\right.
IA(x)=10 若 x∈A 若 x∈/A
对于人脸识别,攻击者生成一个敌对的人脸图像,目的是将其识别为任何其他身份。
准则
C
\\mathcal C
C 为:
C
(
f
(
x
∗
)
)
=
I
(
f
(
x
∗
)
≠
y
)
\\mathcalC\\left(f\\left(\\boldsymbolx^*\\right)\\right)=\\mathbbI\\left(f\\left(\\boldsymbolx^*\\right) \\neq y\\right)
C(f(x∗))=I(f(x∗)=y)
其中
y
y
y 是真实图像
x
x
x 的真实身份。
❑ ❑ ❑ 假冒攻击( Impersonation Attack,目标攻击)
工作原理是寻找被识别为特定身份的对抗图像,这可以用来逃避面部认证系统。
对于人脸验证,攻击者试图找到被识别为另一个图像 x ′ \\boldsymbol x' x′ 的相同身份的敌对图像,而与原始图像不是来自相同的身份。
准则 C \\mathcal C C 为
C ( f ( x ∗ , x ′ ) ) = I ( f ( x ∗ , x ′ ) = 1 ) \\mathcalC\\left(f\\left(\\boldsymbolx^*, \\boldsymbol x'\\right)\\right)=\\mathbbI\\left(f\\left(\\boldsymbolx^*, \\boldsymbol x'\\right)=1\\right) C(f(x∗以上是关于《繁凡的论文精读》CVPR 2019 基于决策的高效人脸识别黑盒对抗攻击(清华朱军)的主要内容,如果未能解决你的问题,请参考以下文章