《概率统计》经典统计推断:寻找最大似然
Posted traditional
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《概率统计》经典统计推断:寻找最大似然相关的知识,希望对你有一定的参考价值。
统计推断的两大学派
在统计领域,有两种对立的思想学派:贝叶斯学派和经典学派(也称频率学派),它们之间最重要的区别就是如何看待被估计的未知参数。贝叶斯学派的观点是将其看成是已知分布的随机变量,而经典学派的观点是将其看成未知的待估计的常量。
贝叶斯统计推断
具体来说,贝叶斯推断方法是将未知参数看做是一个随机变量,它具备某种先验分布。在已知观测数据 x 的基础上,可以利用贝叶斯公式来推导后验概率分布,这样就同时包含人的先验知识以及观测值 x 所能提供的关于 θ 的新信息。贝叶斯统计推断的内容,我们这一篇里不展开,下一篇会详细介绍。
经典统计推断
而经典统计方法是将未知参数 θ 看作是一个常数,但是它是未知的,那么,这就需要去估计它了。经典统计的目标就是提出参数 θ 的估计方法,并且保证其具有一定的性质。
举个栗子
我们举个简单的例子,比如我们要通过一个物理试验来测量某个粒子的质量,从经典学派的观点来看,虽然粒子的质量未知,但它本质上是一个确定的常数,不能将其看成是一个随机变量。而贝叶斯学派则截然不同,会将待估计的粒子质量看做是一个随机变量,并利用人们对该粒子的已有的认知给它一个先验分布,按照分布的概率模型,使其集中在某个指定的范围中。
极大似然估计法
下面,我们重点介绍经典统计推断当中的极大似然估计法。为了给大家一个直观的感觉,这里我先来两个例子。
第一个例子还是盒子摸球的例子:
有两个盒子,一号盒子里面有 100 个球,其中 99 个是白球,1 个是黑球;二号盒子里面也有100 个球,其中 99 个是黑球,1 个是白球。
现在我告诉你,我从其中某一个盒子中随机摸出来一个球,这个球是白球,那么你说,我更有可能是从哪个盒子里摸出的这个球?
显然,你会说是一号盒子。道理很简单,因为一号盒子当中,摸出白球的概率是 0.99,而二号盒子摸出白球的概率是 0.01。显然更有可能是一号盒子了。
第二个例子也是大家熟悉的丢硬币的例子:
我有三个不均匀的硬币,其中第一个硬币抛出正面的概率是 2/5,第二个硬币抛出正面的概率是 1/2,第三个硬币抛出正面的概率是 3/5,这时我取其中一个硬币,抛了 20 次,其中正面向上的次数是 13 次,请问我最有可能是拿的哪一个硬币?
思考的过程也很简单,三枚硬币,抛掷 20 次,13 次正面向上的概率分别是:
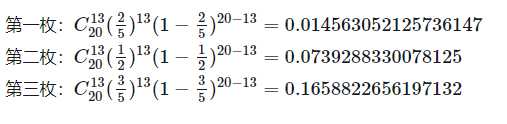
第三枚硬币抛掷出这种结果的概率最大,我更有可能拿的第三枚硬币?这种直观的认识是正确的,这种思维方式的背后正是我们要介绍的极大似然估计法,它就是这么的简单粗暴而有效。
似然函数的由来
有了这个例子,下面我们开始介绍极大似然估计方法。我们重点要理解的是似然这个词,这个词听起来比较陌生。
我们首先看离散型的情形,随机变量 X 的概率分布已知,但是这个分布的参数是未知的,需要我们去估计,我们把它记作是 θ,好比上面抛掷硬币的试验中,硬币正面朝上的概率是未知的,需要我们去估计,那么此时 θ 就代表了这个待估计的正面向上的概率值。
随机变量X的取值(x_i)表示抛k次硬币,正面朝上的次数,那么这个概率就表示为:
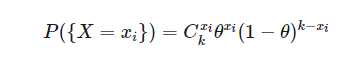
需要注意的是,k和(x_i)都是已知的,而θ是一个未知的参数。因此在这个大背景下,抛掷k次,其中有(x_i)次正面朝上的概率是一个关于θ的未知参数,我们把它写作:P({X=(x_i)}) = P((x_i);θ)
概括地说:概率质量函数PMF是一个关于代估参数θ的函数
那么此时,我们做 n 次这种实验,每次实验中,都是连续抛掷 k 次硬币,统计正面出现的次数,这样就能取得一系列的样本:(x_1,x_2,x_3...x_n),这些样本之间满足相互独立,那么这一串样本取得上述取值({X_1=x_1,X_2=x_2,X_3=x_3,...,X_n=x_n})的联合概率为:(P(x_1;θ),P(x_2;θ),P(x_3;θ),...,P(x_n;θ))
用连乘符号写起来就是:(∏_{i=1}^{n}P(x_i;θ))
这是一个通用的表达式,实际上,你别看它表达式是长长的一串,实际上它的未知数就是一个θ,而其它的(x_i)都是已知的样本值,因此我们说θ的取值,完全决定了这一连串样本取值的联合概率。因此,我们可以换一个更有针对的写法:(∏_{i=1}^{n}P(x_i;θ))
L(θ) = L((x_1, x_2, x_3,...,x_n;θ)) =?(∏_{i=1}^{n}P(x_i;θ))
那么,L(θ) = L((x_1, x_2, x_3,...,x_n;θ)) 就是这一串已知样本(x_1,x_2,x_3,...,x_n)的似然函数,它描述了取得这一串指定样本值的概率值,而这个概率值完全由未知参数 θ 决定。这就是似然函数的由来。
当然如果 X 是一个连续型的随机变量,我们只要相应地把离散型的概率质量函数替换成连续型的概率密度函数即可:
L(θ) = L((x_1, x_2, x_3,...,x_n;θ)) = (∏_{i=1}^{n}F(x_i;θ)),另外这里的F应该是小写,表示函数,包括上面的P((x_i);θ)中的P也应该是小写,只不过我个人习惯写成大写
极大似然估计的思想
显然,似然函数 L((x_1, x_2, x_3,...,x_n;θ))指的就是随机变量X取到指定的这一组样本值:(x_1, x_2, x_3,...,x_n)时的概率大小。当未知的待估计的参数 θ 取不同的值时,计算出来的概率的值会发生变化。
例如,当θ=(θ_0)时,似然函数 L((x_1, x_2, x_3,...,x_n;θ_0))的取值为0或者趋近于0,那么意味着:当θ=(θ_0)时,随机变量X取得这一组样本(x_1,x_2,x_3,...,x_n)的概率为0,即压根不可能取到这一组样本值,或者可能性非常小,那么你肯定觉得参数θ不应该取(θ_0)。
那么当θ取(θ_1)和(θ_2)两种不同的值时,似然函数的值L((x_1, x_2, x_3,...,x_n;θ_1)) >?L((x_1, x_2, x_3,...,x_n;θ_2))。意味着,当θ = (θ_1)时,随机变量X取得这一组的指定样本的概率要更大一些,换句话说,θ取(θ_1)比取(θ_2)有更大的可能获得这一组样本值:(x_1, x_2, x_3,...,x_n),那么当你面对这一组已经获得的采样值,在(θ_1)和(θ_2)当中二选一作为估计值的时候,倾向于选择使似然函数取值更大的估计值,就是再自然不过的了。
这里就是盒子摸球试验中,我们选择一号盒子,丢硬币试验中,我们选择第三枚硬币的原因。
那么更进一步,跳出前面几个引导例子的限制,当我们的未知参数选择的余地更大时,比如我们的未知参数 θ 是对一个概率值的估计,那么它的取值范围就是一个在 [0,1] 之间取值的连续变量,如果是估计总体的方差,那么它的范围就是非负数,如果估计的是总体的均值,那么它的范围就是全体实数了。
此时我们要做的就是在未知参数θ 的取值范围中选取能够让似然函数L((x_1, x_2, x_3,...,x_n;θ_1))取得最大值的(hat θ),作为未知参数的估计值。由于(hat θ)使得似然函数取值达到最大,因此(hat θ)未知参数 θ 的极大似然估计。
换句话说,未知参数 θ 取估计值(hat θ)时获取到这组已知样本(x_1, x_2, x_3,...,x_n)的可能性比取其他任何值时都要大,在这种思维框架下,我们有什么理由不用它呢?
极大似然估计值的计算
那么接下来,问题就到了如何求解这个极大似然估计值了。问题转换为一个求最值的问题:
即:在给定概率模型和一组相互独立的观测样本(x_1, x_2, x_3,...,x_n)的基础上,求解使得似然函数L(θ) = L((x_1, x_2, x_3,...,x_n;θ)) = (∏_{i=1}^{n}P(x_i;θ))取得最大值的未知参数θ的值。当然如果是连续性随机变量,就把P换成F即可。
那么下面问题就变得很直接了,对似然函数求导,使得导数为 0 的θ的取值,就是我们要找的极大似然估计值:(hat θ)
我们两边同时取对数:
ln(L(θ)) = (ln(∏_{i=1}^{n}P(x_i;θ))) = (ln(P(x_1;θ))·ln(P(x_2;θ))·ln(P(x_3;θ))·...·ln(P(x_n;θ)))?= (∑_{i=1}^{n}ln(P(x_i;θ)))
l此时再对它进行求导就变得容易了,如果方程有唯一解,且是极大值点,那么我们就求得了极大似然估计值。如果有多个未知参数需要我们去估计呢?那也好办,用上偏导数就可以了,对每个未知量(θ_i)都用上偏导数即可。
然后我们使得:({?lnL} over {?θ})等于0,把θ解出来即可。
如果是多个位置参数,那么就让:({?lnL} over {?θ_1})、({?lnL} over {?θ_2})、...、({?lnL} over {?θ_n})分别等于0,解出一组(θ_1、θ_2、θ_3...θ_n)即可。
极大似然估计的例子
第一个例子还是抛硬币的例子,我们的硬币正反面不规则,我们想要估计它正面向上的概率 θ,我们连续抛掷 10 次,抛掷10次的结果形成的样本序列如下:
正,正,正,反,反,正,反,正,正,反
很显然,每次抛掷的过程是都是彼此独立的,并且X 是一个伯努利随机变量。我们知道:P({(x_i)=正}) = θ,P({(x_i)=反}) = 1-θ,那么这组观测数据的似然函数为:
L((x_1, x_2, x_3,...,x_{10};θ)) = (∏_{i=1}^{10}P(x_i;θ)) = ({θ^3}{(1-θ)^2}{θ}{(1-θ)}{θ^2}{(1-θ)}) = (θ^6(1-θ)^4)
将其转换为对数似然函数:
ln(L((x_1, x_2, x_3,...,x_{10};θ)))? = ln((θ^6(1-θ)^4)) = 6lnθ + 4ln(1 - θ)
然后对对数似然函数求导:
ln′(L((x_1, x_2, x_3,...,x_{10};θ))) = (6lnθ + 4ln(1 - θ))′ = (6 over θ)?+ (4 over {θ-1}) = (10θ - 6 over {θ(θ-1)})
让对数似然函数的导数为 0:
得到极大似然估计值(hat θ)?= 6 / 10
以上是关于《概率统计》经典统计推断:寻找最大似然的主要内容,如果未能解决你的问题,请参考以下文章
[概率论与数理统计]笔记:5.2 参数的最大似然估计与矩估计
机器学习基础系列--先验概率 后验概率 似然函数 最大似然估计(MLE) 最大后验概率(MAE) 以及贝叶斯公式的理解