使用 Numpy 手动实现深度学习 -- 线性回归
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了使用 Numpy 手动实现深度学习 -- 线性回归相关的知识,希望对你有一定的参考价值。
概述以房价预测为例,使用numpy实现深度学习网络--线性回归代码。
数据链接:https://pan.baidu.com/s/1pY5gc3g8p-IK3AutjSUUMA
提取码:l3oo
导入库
import numpy as np
import matplotlib.pyplot as plt加载数据
def LoadData():
#读取数据
data = np.fromfile( ‘./housing.data‘, sep=‘ ‘ )
#变换数据形状
feature_names = [‘CRIM‘, ‘ZN‘, ‘INDUS‘, ‘CHAS‘, ‘NOX‘, ‘RM‘, ‘AGE‘, ‘DIS‘, ‘RAD‘, ‘TAX‘, ‘PTRATIO‘, ‘B‘, ‘LSTAT‘, ‘MEDV‘]
feature_num = len( feature_names )
data = data.reshape( [-1, feature_num] )
#计算数据最大值、最小值、平均值
data_max = data.max( axis=0 )
data_min = data.min( axis=0 )
data_avg = data.sum( axis=0 ) / data.shape[0]
#对数据进行归一化处理
for i in range( feature_num ):
data[:, i] = ( data[:, i] - data_avg[i] ) / ( data_max[i] - data_min[i] )
#划分训练集和测试集
ratio = 0.8
offset = int( data.shape[0] * ratio )
train_data = data[ :offset ]
data_test = data[ offset: ]
return data_train, data_test模型设计
class Network( object ):
‘‘‘
线性回归神经网络类
‘‘‘
def __init__( self, num_weights ):
‘‘‘
初始化权重和偏置
‘‘‘
self.w = np.random.randn( num_weights, 1 ) #随机初始化权重
self.b = 0.
def Forward( self, x ):
‘‘‘
前向训练:计算预测值
‘‘‘
y_predict = np.dot( x, self.w ) + self.b #根据公式,计算预测值
return y_predict
def Loss( self, y_predict, y_real ):
‘‘‘
计算损失值:均方误差法
‘‘‘
error = y_predict - y_real #误差
cost = np.square( error ) #代价函数:误差求平方
cost = np.mean( cost ) #求代价函数的均值(即:MSE法求损失)
return cost
def Gradient( self, x, y_real ):
‘‘‘
根据公式,计算权重和偏置的梯度
‘‘‘
y_predict = self.Forward( x ) #计算预测值
gradient_w = ( y_predict - y_real ) * x #根据公式,计算权重的梯度
gradient_w = np.mean( gradient_w, axis=0 ) #计算每一列的权重的平均值
gradient_w = gradient_w[:, np.newaxis] #reshape
gradient_b = ( y_predict - y_real ) #根据公式,计算偏置的梯度
gradient_b = np.mean( gradient_b ) #计算偏置梯度的平均值
return gradient_w, gradient_b
def Update( self, gradient_w, gradient_b, learning_rate=0.01 ):
‘‘‘
梯度下降法:更新权重和偏置
‘‘‘
self.w = self.w - gradient_w * learning_rate #根据公式,更新权重
self.b = self.b - gradient_b * learning_rate #根据公式,更新偏置
def Train( self, x, y, num_iter=100, learning_rate=0.01 ):
‘‘‘
使用梯度下降法,训练模型
‘‘‘
losses = []
for i in range( num_iter ): #迭代计算更新权重、偏置
#计算预测值
y_predict = self.Forward( x )
#计算损失
loss = self.Loss( y_predict, y )
#计算梯度
gradient_w, gradient_b = self.Gradient( x, y )
#根据梯度,更新权重和偏置
self.Update( gradient_w, gradient_b, learning_rate )
#打印模型当前状态
losses.append( loss )
if ( i+1 ) % 10 == 0:
print( ‘iter = {}, loss = {}‘.format( i+1, loss ) )
return losses模型训练
#获取数据
train_data, test_data = LoadData()
x_data = train_data[:, :-1]
y_data = train_data[:, -1:]
#创建网络
net = Network( 13 )
num_interator = 1000
learning_rate = 0.01
#进行训练
losses = net.Train( x_data, y_data, num_interator, learning_rate )
#画出损失函数变化趋势
plot_x = np.arange( num_interator )
plot_y = losses
plt.plot( plot_x, plot_y )
plt.show()训练结果

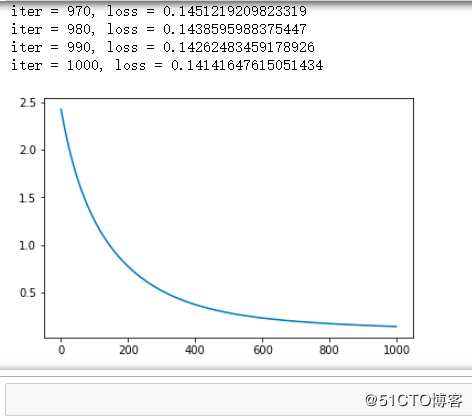
以上是关于使用 Numpy 手动实现深度学习 -- 线性回归的主要内容,如果未能解决你的问题,请参考以下文章
《动手学深度学习》线性回归的简洁实现(linear-regression-pytorch)