爬虫简介和requests模块
Posted cnhyk
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬虫简介和requests模块相关的知识,希望对你有一定的参考价值。
爬虫介绍
爬虫的本质就是模拟发送http请求(requests模块),之后解析返回的数据(re,bs4,lxml,json等模块),最后将数据入库(redis,mysql,mongodb)。
app的爬虫,本质上是一模一样的。
python做爬虫的优势在于:包多,而且有爬虫的框架scrapy,是一个性能很高的爬虫框架,类似后台框架中的Django,该框架,大而全(爬虫相关的东西都集成了。)
百度和谷歌其实就是个大爬虫,在百度搜索,其实是去百度的服务器的库搜的,百度一直开着爬虫,一刻不停的在互联网上爬取,把页面存储到自己库中
requests模块
该模块可以模拟http请求,是基于urlib2封装出来的模块(urlib2:内置库,不太好用,繁琐)。
安装:
pip3 install requests
requests模块
1、requests模块的基本使用
import requests
# get,delete,post等等请求方式都是调用的requests模块中的request函数
ret = requests.post()
# ret = requests.request(‘post‘, ) 内部都是调用request函数
ret = requests.delete()
ret = requests.get(‘https://www.cnblogs.com‘)
print(ret.status_code) # 响应状态码
print(ret.text) # 响应体,转成字符串
print(ret.content) # 响应体,二进制的,用于获取视频等
2、get 请求携带参数,调用params参数,其本质上还是调用urlencode
# 方式一
ret = requests.get(‘https://www.baidu.com/s?wd=python&pn=1‘,
headers={
‘User-Agent‘: ‘Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/80.0.3987.149 Safari/537.36‘,
})
print(ret.text)
# 方式二(建议使用方式二),因为中文会自动转码
ret = requests.get(‘https://www.baidu.com/‘,
params={
‘wd‘: "美女",
‘pn‘: 1
},
headers={
‘User-Agent‘: ‘Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36‘,
})
print(ret.text)
3、携带headers,请求头是将自身伪装成浏览器的关键
ret = requests.get(‘http://0.0.0.0:8001/?name=%E7%BE%8E%E5%A5%B3‘,
headers={
# 标志,什么东西发出的请求,浏览器信息,django框架,从哪取?(meta)
‘User-Agent‘: ‘‘,
# 上一个页面的地址,图片防盗链,大型网站通常回根据该参数判断请求的来源
‘Referer‘: ‘xxx‘,
# 存放cookie的地方
‘Cookie‘: ‘‘
})
print(ret)
"""
图片防盗链:如果图片的referer不是我自己的网站,就直接禁止掉
<img src="https://www.lgstatic.com/lg-community-fed/community/modules/common/img/avatar_default_7225407.png">
"""
4、带cookie
随机字符串(用户信息:也代表session),不管后台用的token认证,还是session认证,一旦登陆了,带着cookie发送请求,表示登陆了(可以下单,可以12306买票,可以评论)
# 第一种方式
ret = requests.get(‘http://0.0.0.0:8001/?name=%E7%BE%8E%E5%A5%B3‘,
headers={
‘cookie‘: ‘key3=value;key2=value‘,
})
# 第二种方式
ret = requests.get(‘http://0.0.0.0:8001/?name=%E7%BE%8E%E5%A5%B3‘,
cookies={"islogin":"xxx"})
print(ret)
5、发送post请求(注册,登陆),携带数据(body)
# data=None, json=None
# data: urlencoded编码
ret = requests.post(‘http://0.0.0.0:8001/‘,data={‘name‘:"lqz",‘age‘:18})
# json: json编码
import json
data = json.dumps({‘name‘:"lqz",‘age‘:18})
ret = requests.post(‘http://0.0.0.0:8001/‘,json=data)
print(ret)
# 注意:编码格式是请求头中带的,所有我可以手动修改,在headers中改
6、session对象
session = requests.session()
# 跟requests.get/post用起来完全一样,但是它处理了cookie
# 假设是一个登陆,并且成功登陆,就可以使用session.post()进行请求,但无需携带cookie
session.post()
# 再向该网站发请求,就是登陆状态,不需要手动携带cookie
session.get("地址")
7、响应对象
print(respone.text) # 响应体转成str
print(respone.content) # 响应体二进制(图片,视频)
print(respone.status_code) # 响应状态码
print(respone.headers) # 响应头
print(respone.cookies) # 服务端返回的cookie
print(respone.cookies.get_dict()) # 转成字典
print(respone.cookies.items())
print(respone.url) # 当次请求的地址
"""
print(respone.history) # 如果有重定向,放到一个列表中
ret=requests.post(‘http://0.0.0.0:8001/‘)
ret=requests.get(‘http://0.0.0.0:8001/admin‘)
#不要误解
ret=requests.get(‘http://0.0.0.0:8001/user‘)
print(ret.history) # 只能获取到ret=requests.get(‘http://0.0.0.0:8001/user‘)的重定向网址
# 上面的三个ret是不同的三个响应,ret.history只能获取到一个响应对象的重定向的历史网址
"""
print(respone.encoding) # 编码方式
# response.iter_content() # 视频,图片迭代取值,避免一次取完,撑爆内存
with open("a.mp4",‘wb‘) as f:
for line in response.iter_content():
f.write(line)
8、乱码问题
ret.encoding=‘gbk‘
ret = requests.get(‘http://0.0.0.0:8001/user‘)
# ret.apparent_encoding 获取当前页面采用的编码
ret.encoding = ret.apparent_encoding
9、解析json
# 返回数据,有可能是json格式,有可能是html格式
ret = requests.get(‘http://0.0.0.0:8001/‘)
print(type(ret.text))
print(ret.text)
a = ret.json()
print(a[‘name‘])
print(type(a))
10、使用代理
# 正向代理
# django如何拿到客户端ip地址 META.get("REMOTE_ADDR")
# 使用代理有什么用? 可以让服务端以为来访问的是代理的网站
# 一些网站,会限制ip的访问次数,因此我们可以使用代理池,去访问该网站,突破限制
ret = requests.get(‘http://0.0.0.0:8001/‘, proxies={‘http‘:‘地址‘})
print(type(ret.text))
print(ret.text)
11、异常处理
# 用try except捕获一下 就用它就行了:Exception
12、上传文件(爬虫用的比较少,一般用于后台写服务,将爬取下来的文件上传给其他服务端)
file={‘myfile‘:open("1.txt",‘rb‘)}
ret=requests.post(‘http://0.0.0.0:8001/‘,files=file)
print(ret.content)
利用requests模块爬取梨视频
############
# 2 爬取视频
#############
#categoryId=9 分类id
#start=0 从哪个位置开始,每次加载12个
# https://www.pearvideo.com/category_loading.jsp?reqType=5&categoryId=9&start=0
import requests
import re
ret=requests.get(‘https://www.pearvideo.com/category_loading.jsp?reqType=5&categoryId=9&start=0‘)
# print(ret.text)
# 正则取解析
reg=‘<a href="(.*?)" class="vervideo-lilink actplay">‘
video_urls=re.findall(reg,ret.text)
print(video_urls)
for url in video_urls:
ret_detail=requests.get(‘https://www.pearvideo.com/‘+url)
reg=‘srcUrl="(.*?)",vdoUrl=srcUrl‘
mp4_url=re.findall(reg,ret_detail.text)[0] #type:str
# 下载视频
video_content=requests.get(mp4_url)
video_name=mp4_url.rsplit(‘/‘,1)[-1]
with open(video_name,‘wb‘) as f:
for line in video_content.iter_content():
f.write(line)
代码可以优化,使用多线程进行爬取
模拟登陆某网站
############
# 3 模拟登陆某网站
#############
import requests
ret = requests.post(‘http://www.aa7a.cn/user.php‘,
data={
‘username‘: ‘616564099@qq.com‘,
‘password‘: ‘lqz123‘,
‘captcha‘: ‘f5jn‘,
‘remember‘: ‘1‘,
‘ref‘: ‘http://www.aa7a.cn/‘,
‘act‘: ‘act_login‘,
})
cookie=ret.cookies.get_dict()
print(cookie)
# 如果不出意外,咱么就登陆上了,再向首页发请求,首页返回的数据中就有616564099@qq.com
ret1=requests.get(‘http://www.aa7a.cn/‘,cookies=cookie)
# ret1=requests.get(‘http://www.aa7a.cn/‘)
print(‘616564099@qq.com‘ in ret1.text)
# 秒杀小米手机,一堆小号
# 定时任务:一到时间,就可以发送post请求,秒杀手机
# 以后碰到特别难登陆的网站,代码登陆不进去怎么办?
# 之所以要登陆,就是为了拿到cookie,下次发请求(如果程序拿不到cookie,自动登陆不进去)
# 就手动登陆进去,然后用程序发请求
代理
## 代理
# 网上会有免费代理,不稳定
# 使用代理有什么用?
# drf:1分钟只能访问6次,限制ip
# 每次发请求都使用不同代理,random一下
# 代理池:列表,其实就是代理池的一种
import requests
ret=requests.get(‘https://www.cnblogs.com/‘,proxies={‘http‘:‘222.85.28.130:40505‘})
#高匿:服务端,根本不知道我是谁
#普通:服务端是能够知道我的ip的
# http请求头中:X-Forwarded-For:代理的过程,可以获取到最初发起请求的客户端ip地址和代理服务的ip地址,但对于高匿,是无法获取到的最初请求的客户端ip地址。
ret=requests.get(‘http://101.133.225.166:8080‘,proxies={‘http‘:‘222.85.28.130:40505‘})
ret=requests.get(‘http://101.133.225.166:8080‘,proxies={‘http‘:‘114.99.54.65:8118‘})
print(ret.text)
X-Forwarded-For: <client>, <proxy1>, <proxy2>
<client>
客户端的IP地址。
<proxy1>, <proxy2>
如果一个请求经过了多个代理服务器,那么每一个代理服务器的IP地址都会被依次记录在内。也就是说,最右端的IP地址表示最近通过的代理服务器,而最左端的IP地址表示最初发起请求的客户端的IP地址。
正向代理和反向代理
正向代理即是客户端代理,代理客户端,服务端不知道实际发起请求的客户端。
反向代理即是服务端代理,代理服务端,客户端不知道实际提供服务的服务端。
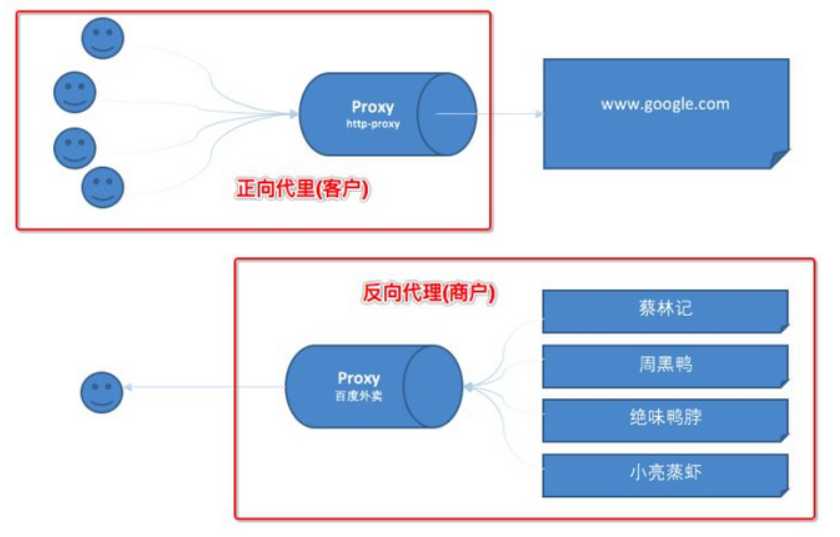
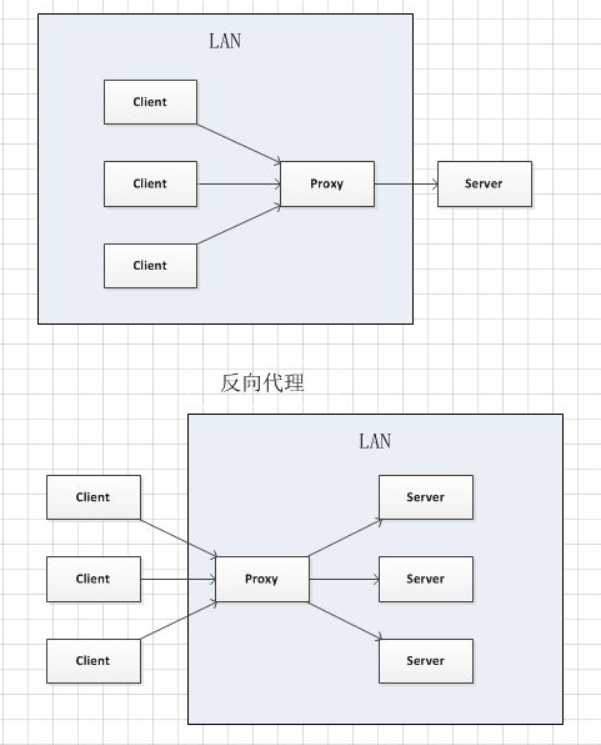
正向代理中,proxy和client同属一个LAN,对server透明;
反向代理中,proxy和server同属一个LAN,对client透明。
实际上proxy在两种代理中做的事都是代为收发请求和响应,不过从结构上来看正好左右互换了下,所以把后出现的那种代理方式叫成了反向代理
静态,动态和伪静态
静态是指http://127.0.0.1/user.html这种url,页面中的内容是固定死的,数据也是死的,加载速度快,容易被搜索引擎爬取收录,可以优化seo。
动态是指http://127.0.0.1/?name=‘张三‘&age=12这种url,页面的数据是从数据库中获取的,加载速度较慢,不容易被搜索引擎爬取收录,seo没有优势。
伪静态是指http://127.0.0.1/user.html通过一些路径规则(正则表达式)将动态url伪装为静态url,加载速度较慢,seo有优势。
总结:
静态url: 不方便管理,修改麻烦, seo优化相当好.
动态url : 方便管理,修改简单, seo没优势.
伪静态: 结合两者的优势. 方便管理, seo有优势.
以上是关于爬虫简介和requests模块的主要内容,如果未能解决你的问题,请参考以下文章