1爬虫简介与request模块
Posted pyedu
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了1爬虫简介与request模块相关的知识,希望对你有一定的参考价值。
一 爬虫简介
概述
近年来,随着网络应用的逐渐扩展和深入,如何高效的获取网上数据成为了无数公司和个人的追求,在大数据时代,谁掌握了更多的数据,谁就可以获得更高的利益,而网络爬虫是其中最为常用的一种从网上爬取数据的手段。
网络爬虫,即Web Spider,是一个很形象的名字。如果把互联网比喻成一个蜘蛛网,那么Spider就是在网上爬来爬去的蜘蛛。网络蜘蛛是通过网页的链接地址来寻找网页的。从网站某一个页面(通常是首页)开始,读取网页的内容,找到在网页中的其它链接地址,然后通过这些链接地址寻找下一个网页,这样一直循环下去,直到把这个网站所有的网页都抓取完为止。

爬虫的价值
互联网中最有价值的便是数据,比如天猫商城的商品信息,链家网的租房信息,雪球网的证券投资信息等等,这些数据都代表了各个行业的真金白银,可以说,谁掌握了行业内的第一手数据,谁就成了整个行业的主宰,如果把整个互联网的数据比喻为一座宝藏,那我们的爬虫课程就是来教大家如何来高效地挖掘这些宝藏,掌握了爬虫技能, 你就成了所有互联网信息公司幕后的老板,换言之,它们都在免费为你提供有价值的数据。
爬虫的基本流程
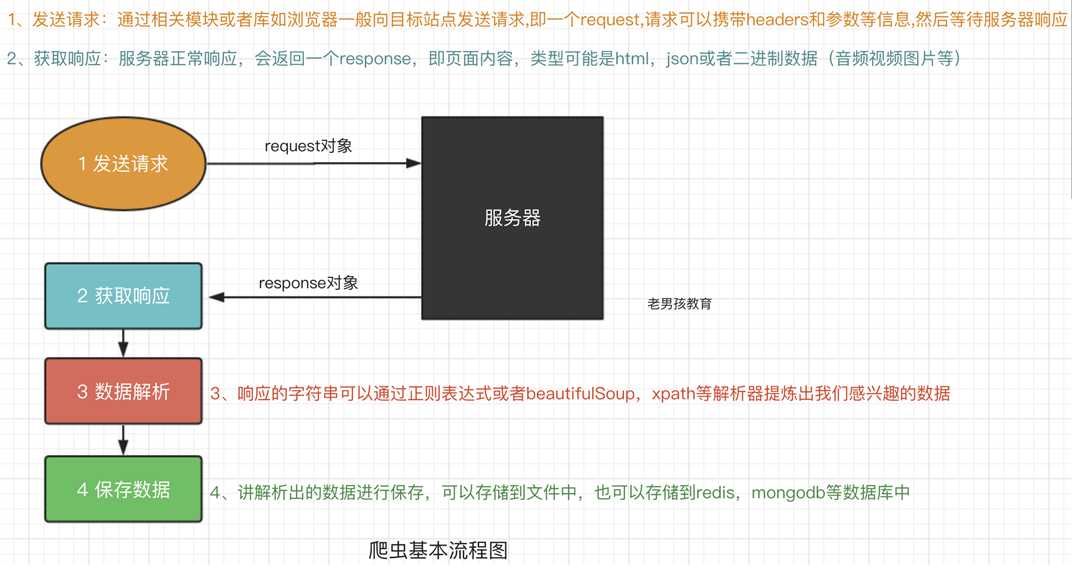
预备知识
二 requests模块
以上是关于1爬虫简介与request模块的主要内容,如果未能解决你的问题,请参考以下文章