knn原理及借助电影分类实现knn算法
Posted wutanghua
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了knn原理及借助电影分类实现knn算法相关的知识,希望对你有一定的参考价值。
KNN最近邻算法原理
KNN英文全称K-nearst neighbor,中文名称为K近邻算法,它是由Cover和Hart在1968年提出来的
KNN算法原理:
1. 计算已知类别数据集中的点与当前点之间的距离;
2. 按照距离递增次序排序;
3. 选择与当前距离最小的k个点;
4. 确定前k个点所在类别的出现概率
5. 返回前k个点出现频率最高的类别作为当前点的预测分类
如果数据集中序号1-12为已知的电影分类,分为喜剧片、动作片、爱情片三个种类,使用的特征值分别为搞笑镜头、打斗镜头、拥抱镜头的数量。那么来了一部新电影《唐人街探案》,它属于上述3个电影分类中的哪个类型?
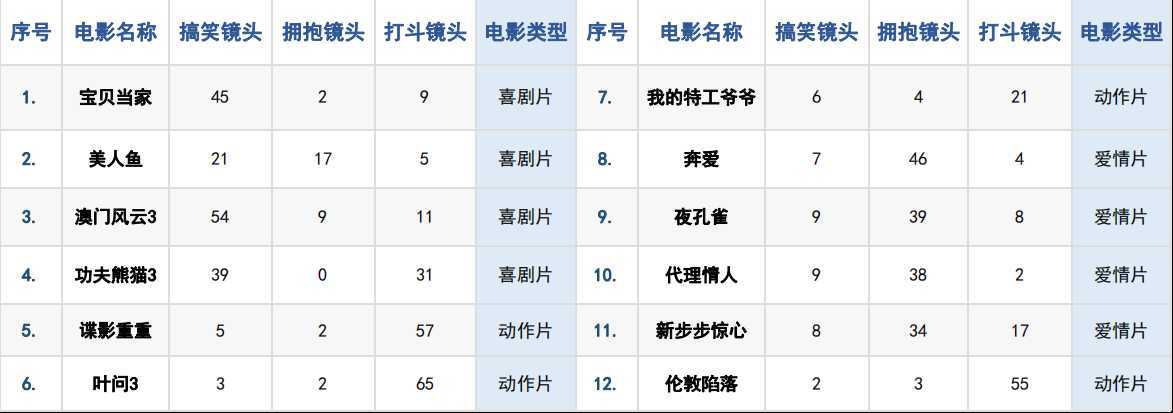
代码实现如下
import pandas as pd import numpy as np def distance(v1, v2): """ 距离计算 :param v1:点1 :param v2: 点2 :return: 距离 """ dist = np.sqrt(np.sum(np.power((v1 - v2), 2))) return dist # 加载数据 data = pd.read_excel("./电影分类数据.xlsx") print("data: ", data) print("*" * 80) # 获取训练集 train = data.iloc[:, :6] print("train: ", train) # 获取训练集的特征值 与目标值 train_x = train.iloc[:, :-1] train_y = train.iloc[:, -1] # 获取测试集 print("*" * 80) test = data.columns[-4:] print("test: ", test) # 进行计算距离 # 循环计算训练集每一个样本与测试集的距离 for i in range(train.shape[0]): # 计算距离 dist = distance(train_x.iloc[i,2:5],test[1:]) train.loc[i,‘dist‘] = dist print(train) # 对距离按照升序进行排序 train.sort_values(by=‘dist‘,inplace=True) print("*" * 80) print("排序后的train: ",train) # 确定K 值 k值不同结果不同 k =5 res = train.loc[:,‘电影类型‘][:k].mode()[0] print("*" * 80) print(res)
以上是关于knn原理及借助电影分类实现knn算法的主要内容,如果未能解决你的问题,请参考以下文章