爬取动态加载的数据
Posted zzsy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬取动态加载的数据相关的知识,希望对你有一定的参考价值。
动态加载的数据
例子1:爬取豆瓣电影中的电影详情数据
1.什么是动态加载的数据:
我们通过requests模块进行数据爬取无法每次都是可见即可得,有些数据是通过非浏览器地址栏中得url请求到的地址。而是其他请求请求到的数据,那么这些通过其他请求请求到的数据就是动态加载的数据。(猜测有可能是js代码当咱们访问此页面时就会发送得get请求,到其他url中获取数据)
2.如何检测网页中是否存在动态加载得数据
在当前页面中打开抓包工具,捕获到地址栏中的url对应的数据包,在该数据包的response选项卡搜索我们想要爬取的数据,如果搜索到了结果则表示数据不是动态加载的,否则表示数据为动态加载的
3.如果数据为动态加载,那么我们如何捕获到动态加载的数据?
基于抓包工具进行全局搜索。
?
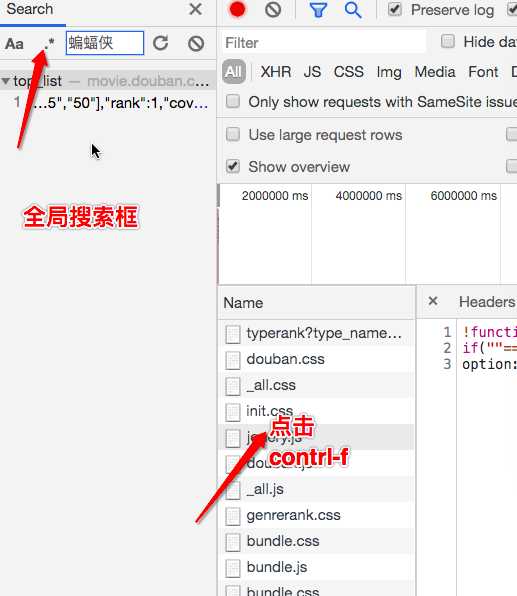
定位到动态加载数据对应的数据包,从该数据包中就可以提取出
- 请求的url
- 请求方式
- 请求携带的参数
- 看到响应数据
然后要分析参数跟url的关系。发现他有 ‘start‘: ‘0‘,‘limit‘: ‘20‘, 在url中有携带此参数,此参数start就是从哪个电影开始。limit就是从开始之后显示多少个。例如爬取前30个电影数据,就是start :0 到 limit :30 ,例如start :2 到 limit :12,就是从第二个电影,再往后获取12个电影
所以我们开始写代码:爬取从第10个开始后面的50个电影
url = ‘https://movie.douban.com/j/chart/top_list‘
params = {
‘type‘: ‘5‘,
‘interval_id‘: ‘100:90‘,
‘action‘: ‘‘,
‘start‘: ‘10‘,
‘limit‘: ‘50‘,
}
response = requests.get(url=url,params=params,headers=headers)
#.json()将获取的字符串形式的json数据序列化成字典或者列表对象
page_text = response.json()
#解析出电影的名称+评分
for movie in page_text:
name = movie[‘title‘]
score = movie[‘score‘]
print(name,score)
例子2:分页爬取肯德基餐厅位置数据
- 分页数据的爬取操作
- 爬取肯德基的餐厅位置数据
- 分析:
- 1.在录入关键字的文本框中录入关键字按下搜索按钮,发起的是一个ajax请求
- 当前页面刷新出来的位置信息一定是通过ajax请求请求到的数据
- 2.基于抓包工具定位到该ajax请求的数据包,从该数据包中捕获到:
- 请求的url
- 请求方式
- 请求携带的参数
- 看到响应数据
- 1.在录入关键字的文本框中录入关键字按下搜索按钮,发起的是一个ajax请求
#爬取的是第一页的数据
url = ‘http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword‘
data = {
‘cname‘: ‘‘,
‘pid‘: ‘‘,
‘keyword‘: ‘北京‘,
‘pageIndex‘: ‘1‘,
‘pageSize‘: ‘10‘,
}
#data参数是post方法中处理参数动态化的参数
get的参数用params,他会显示在url上。post用data!!!!
response = requests.post(url=url,headers=headers,data=data)
page_text = response.json()
for dic in page_text[‘Table1‘]:
title = dic[‘storeName‘]
addr = dic[‘addressDetail‘]
print(title,addr)
#爬取多页的话
分析之后处理data数据即可,pageIndex就是显示的页数。for循环,请求每一页的。
for page in range(1,9):
data = {
‘cname‘: ‘‘,
‘pid‘: ‘‘,
‘keyword‘: ‘北京‘,
‘pageIndex‘: str(page),
‘pageSize‘: ‘10‘,
}
response = requests.post(url=url,headers=headers,data=data)
page_text = response.json()
for dic in page_text[‘Table1‘]:
title = dic[‘storeName‘]
addr = dic[‘addressDetail‘]
print(title,addr)
例子3:药监总局每页的详情数据
url = http://125.35.6.84:81/xk/
我们get请求当前url,response选项卡中并未有各个企业的数据,通过抓包工具搜索,发现是post请求了其他网址获取的数据,所以我们通过这个post请求获取url发送请求
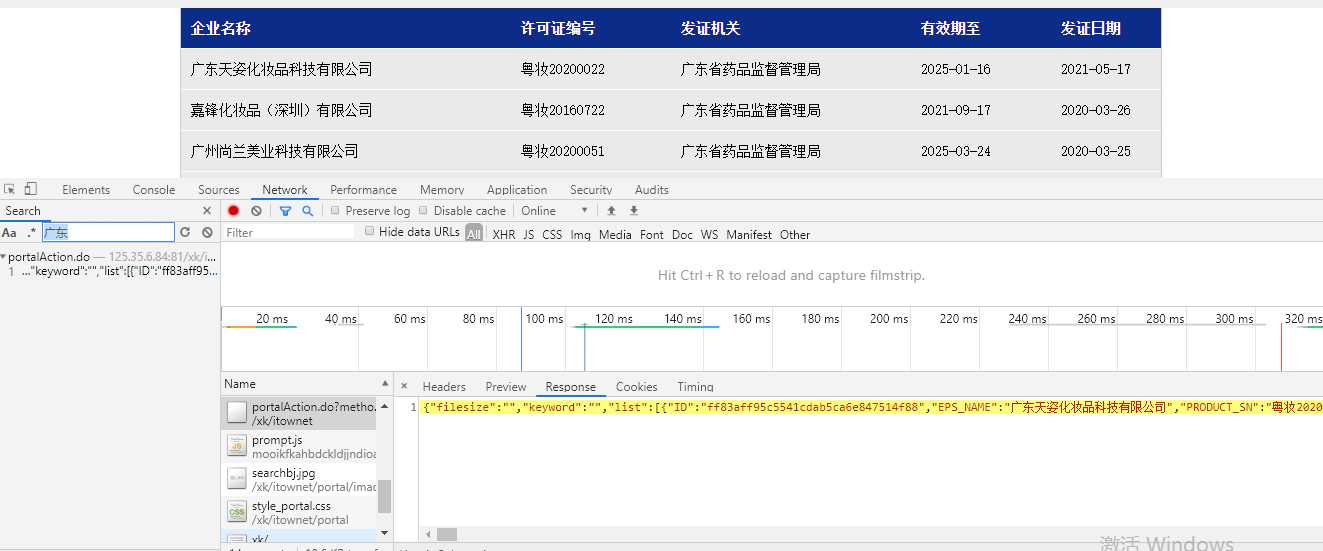
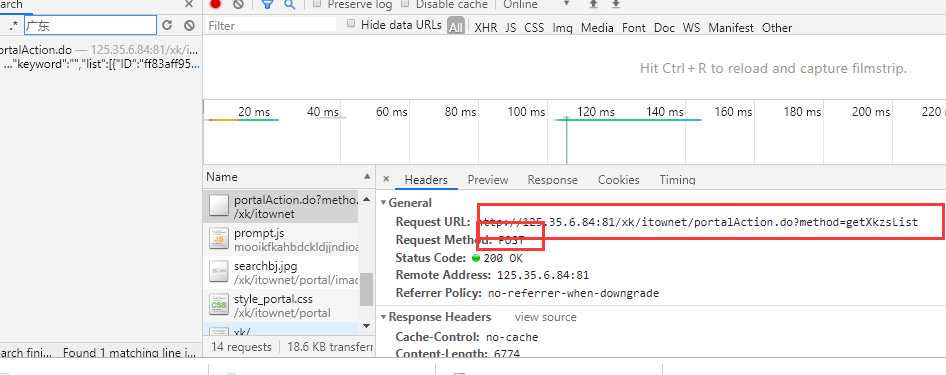
参数是:
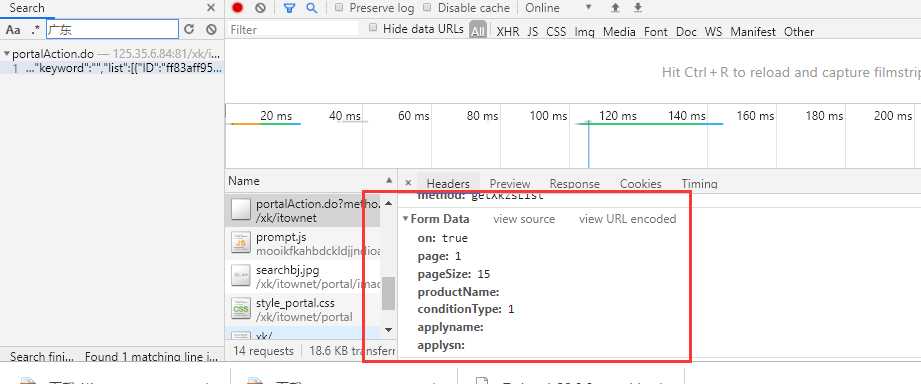
然后我们发请求获取到每页的数据。但是我们需要每页中每个企业的详情页内容
我们点开详情页,发现get请求此页面response选项卡中没有数据,后来我们发现此页面也是动态加载的数据。有个post请求发送获取数据
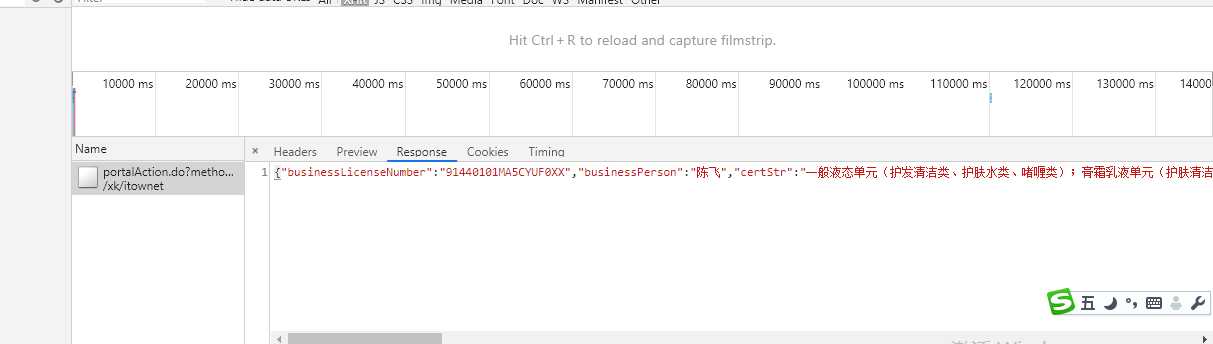
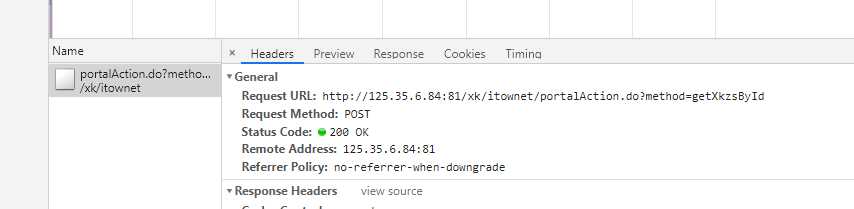
经过分析发现他是通过id来查询结果的,此ID在获取页面Json数据时每个企业都有
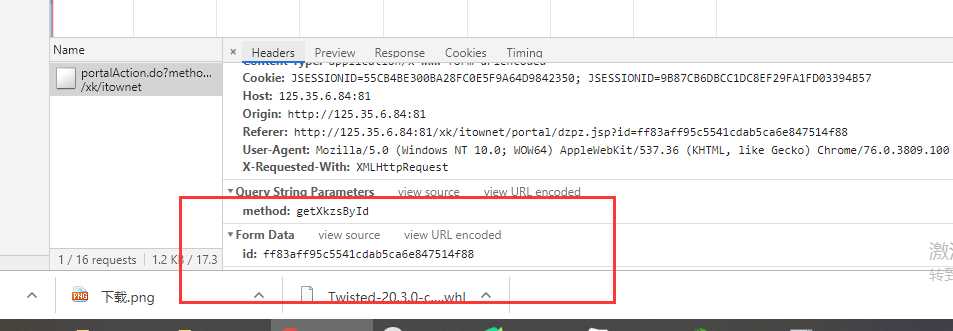
结果以上。我们写代码获取前3页所有企业的详情信息
url = "http://125.35.6.84:81/xk/itownet/portalAction.do?method=getXkzsList"
for i in range(3):
data={‘on‘: ‘true‘,
‘page‘: ‘1‘,
‘pageSize‘: ‘15‘,
‘productName‘: ‘‘,
‘conditionType‘: i,
‘applyname‘: ‘‘,
‘applysn‘: ‘‘,}
response = requests.post(url=url,data=data).json()
for w in response["list"]:
print(w)
data = {"id":w["ID"]}
url =‘ http://125.35.6.84:81/xk/itownet/portalAction.do?method=getXkzsById‘
response = requests.post(url=url,data=data).json()
print(response)
以上是关于爬取动态加载的数据的主要内容,如果未能解决你的问题,请参考以下文章