爬取动态网页:Selenium
Posted Michael2397
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬取动态网页:Selenium相关的知识,希望对你有一定的参考价值。
参考:http://blog.csdn.net/wgyscsf/article/details/53454910
概述
- 在爬虫过程中,一般情况下都是直接解析html源码进行分析解析即可。但是,有一种情况是比较特殊的:网页的数据采用异步加载的,比如ajax加载的数据,在我们“查看网页源代码”是查看不到的。采用常规的爬虫这一块是解析不到的。
-
第一种解决方案是采用一些第三方的工具,模拟浏览器的行为,去加载数据。比如:
Selenium、PhantomJs。- 优点:不必考虑动态页面的各种变化多端(无论动态数据如何变化,最终呈现在页面上的效果是固定的,我们只关心最终结果。),我们只用关心最终的现实结果即可。可以统一处理。
- 缺点:性能低下,比如使用
Selenium,每次我们都需要去启动一个浏览器进程;配置繁琐,不同的浏览器需要下载不同的驱动以及jar包,并且驱动和jar包之间有严格版本匹配关系,如果不匹配就不能使用(至少本人因为版本匹配的关系,花了很大的时间)。
-
第二种解决方案是分析页面,找到对应请求接口,直接获取数据。
- 优点:性能高,使用方便。我们直接获取原数据接口(换句话说就是直接拿取网页这一块动态数据的API接口),肯定会使用方便,并且改变的可能性也比较小。
- 缺点:缺点也是明显的,如何获取接口API?有些网站可能会考虑到数据的安全性,做各种限制、混淆等。这就需要看开发者个人的基本功了,进行各种分析了。
1、下载安装
谷歌和驱动版本匹配可以参考这篇文章:http://blog.csdn.net/huilan_same/article/details/51896672
chromedriver下载地址(不需要FQ):http://chromedriver.storage.googleapis.com/index.html
将下载的驱动放到谷歌浏览器的安装目录下,如下图
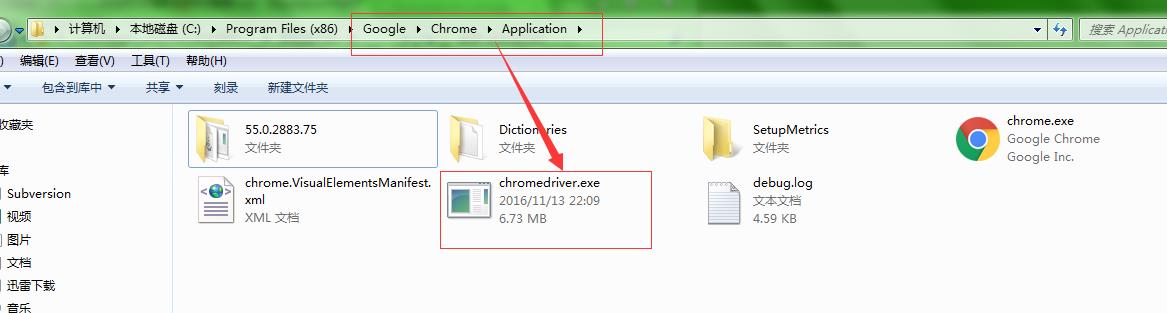
2、导包
3、编写测试代码
package Test; import org.openqa.selenium.WebDriver; import org.openqa.selenium.chrome.ChromeDriver; public class SeleniumTest { public static void main(String[] args) { // 第一步: 设置chromedriver地址。一定要指定驱动的位置。 System.setProperty("webdriver.chrome.driver", "C:\\\\Program Files (x86)\\\\Google\\\\Chrome\\\\Application\\\\chromedriver.exe"); // 第二步:初始化驱动 WebDriver driver = new ChromeDriver(); // 第三步:获取目标网页 driver.get("http://blog.csdn.net/wgyscsf/article/details/52835845"); // 第四步:解析。以下就可以进行解了。使用webMagic、jsoup等进行必要的解析。 System.out.println("Page title is: " + driver.getTitle()); //System.out.println("Page title is: " + driver.getPageSource()); } }

以上是关于爬取动态网页:Selenium的主要内容,如果未能解决你的问题,请参考以下文章