爬虫5 scrapy框架2 全站爬取cnblogs, scarpy请求传参, 提高爬取效率, 下载中间件, 集成selenium, fake-useragent, 去重源码分析, 布隆过滤器,
Posted ludingchao
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬虫5 scrapy框架2 全站爬取cnblogs, scarpy请求传参, 提高爬取效率, 下载中间件, 集成selenium, fake-useragent, 去重源码分析, 布隆过滤器, 相关的知识,希望对你有一定的参考价值。
# 1 scrapy startproject cnblogs_crawl # 2 scrapy genspider cnblogs www.cnblogs.com
示例:
# cnblogs_crawl/cnblogs_crawl/spiders/cnblogs.py import scrapy from cnblogs_crawl.items import CnblogsCrawlItem from scrapy.http import Request class CnblogsSpider(scrapy.Spider): name = ‘cnblogs‘ allowed_domains = [‘www.cnblogs.com‘] start_urls = [‘htteeep://www.cnblogs.com/‘] def parse(self, response): div_list = response.css(‘.post_item‘) for div in div_list: item = CnblogsCrawlItem() title = div.css(‘h3>a::text‘).extract_first() print(title) item[‘title‘] = title url = div.css(‘h3>a::attr(href)‘).extract_first() print(url) item[‘url‘] = url author = div.css(‘.post_item_foot a::text‘).extract_first() print(author) item[‘author‘] = author desc = div.css(‘.post_item_summary::text‘).extract()[-1] print(desc) item[‘desc‘] = desc # yield item # 写callback,爬完之后,就会执行parser_detail。如果不写,爬完url继续执行上面parse解析。meta可以传递额外的东西 yield Request(url,callback=self.parser_detail,meta={‘item‘:item})
# 继续爬下一页内容 next = response.css(‘div.pager a:last-child::attr(href)‘).extract_first() # print(‘https://www.cnblogs.com/‘+next) yield Request(‘https://www.cnblogs.com/‘+next) def parser_detail(self,response): # print(response) item = response.meta.get(‘item‘) # 获得传入参数 content = response.css(‘#cnblogs_post_body‘).extract_first() if not content: content = response.css(‘content‘).extract_first() item[‘content‘] = content yield item
# cnblogs_crawl/cnblogs_crawl/items.py import scrapy class CnblogsCrawlItem(scrapy.Item): title = scrapy.Field() url = scrapy.Field() author = scrapy.Field() desc = scrapy.Field() content = scrapy.Field() # 文章内容
# cnblogs_crawl/cnblogs_crawl/pipelines.py import pymysql class CnblogsCrawlPipeline(object): def open_spider(self, spider): # print(type(spider)) # print(spider.name) self.conn = pymysql.Connect(host=‘127.0.0.1‘, port=3306, db=‘cnblogs‘, user=‘root‘) def process_item(self, item, spider): cursor = self.conn.cursor() sql = ‘‘‘insert into article(title,url,`desc`,content,author) values (%s,%s,%s,%s,%s)‘‘‘ # print(sql) cursor.execute(sql,args=(item[‘title‘], item[‘url‘], item[‘desc‘], item[‘content‘], item[‘author‘])) self.conn.commit() # return item # 没有后续pipeline可以不加 def close_spider(self, spider): self.conn.close()
# cnblogs_crawl/cnblogs_crawl/settings.py ROBOTSTXT_OBEY = False LOG_LEVEL=‘ERROR‘ ITEM_PIPELINES = { ‘cnblogs_crawl.pipelines.CnblogsCrawlPipeline‘: 300, }
# cnblogs_crawl/main.py from scrapy.cmdline import execute execute([‘scrapy‘,‘crawl‘,‘cnblogs‘])
# 写callback,爬完之后,就会执行parser_detail。如果不写,爬完url继续执行上面parse解析。meta可以传递额外的东西 # 1 放 :yield Request(url,callback=self.parser_detail,meta={‘item‘:item}) # 2 取:response.meta.get(‘item‘)
示例参看上面爬虫类中传参方法
- 在配置文件中进行相关的配置即可:(默认还有一套setting) #1 增加并发: 默认scrapy开启的并发线程为32个,可以适当进行增加。在settings配置文件中修改CONCURRENT_REQUESTS = 100值为100,并发设置成了为100。 #2 提高日志级别: 在运行scrapy时,会有大量日志信息的输出,为了减少CPU的使用率。可以设置log输出信息为INFO或者ERROR即可。在配置文件中编写:LOG_LEVEL = ‘INFO’ # 3 禁止cookie: 如果不是真的需要cookie,则在scrapy爬取数据时可以禁止cookie从而减少CPU的使用率,提升爬取效率。在配置文件中编写:COOKIES_ENABLED = False # 4禁止重试: 对失败的HTTP进行重新请求(重试)会减慢爬取速度,因此可以禁止重试。在配置文件中编写:RETRY_ENABLED = False # 因为前一章博客scrapy架构图中,如果最右侧DOWNLOADER没有下载下来,还会返回requests,ENGINE会把它重新返回SCHEDULER中重新调度(一般情况下,下载不下来是地址不通,没必要重试) # 5 减少下载超时: 如果对一个非常慢的链接进行爬取,减少下载超时可以能让卡住的链接快速被放弃,从而提升效率。在配置文件中进行编写:DOWNLOAD_TIMEOUT = 10 超时时间为10s (settings.py里面没有,直接往上写)
# 2大中间件:下载中间件,爬虫中间件 # 1 写在middlewares.py中(名字随便命名) # 2 配置生效() SPIDER_MIDDLEWARES = { ‘cnblogs_crawl.middlewares.CnblogsCrawlSpiderMiddleware‘: 543, } DOWNLOADER_MIDDLEWARES = { ‘cnblogs_crawl.middlewares.CnblogsCrawlDownloaderMiddleware‘: 543, } # 2 下载中间件 -process_request:(请求去,走) # - return None: 继续处理当次请求,进入下一个中间件(中间件配了多个,数字越小,优先级越高) # - return Response: 当次请求结束,把Response丢给引擎处理(可以自己爬,包装成Response) # - return Request : 相当于把Request重新给了引擎,引擎再去做调度 # - 抛异常:执行process_exception -process_response:(请求回来,走) # - return a Response object :继续处理当次Response,继续走后续的中间件 # - return a Request object:重新给引擎做调度 # - or raise IgnoreRequest :process_exception -process_exception:(出异常,走) # - return None: continue processing this exception 不处理,把异常继续往后丢 # - return a Response object: stops process_exception() chain :停止异常处理链(可能有多个异常处理中间件),给引擎(给爬虫) # - return a Request object: stops process_exception() chain :停止异常处理链,给引擎(重新调度)
下载中间件异常处理process_exception示例:
# cnblogs_crawl/cnblogs_crawl/middlewares.py from scrapy import signals class CnblogsCrawlSpiderMiddleware(object):... class CnblogsCrawlDownloaderMiddleware(object): ... def process_exception(self, request, exception, spider): print(request.url) # request.url=‘http://www.cnblogs.com/‘ # 不能这样直接修改 from scrapy.http import Request return Request(‘http://www.cnblogs.com/‘,callback=spider.parser_detail) # 加入不用parse方法,要调用回调函数,这样写
下载中间件process_request(加cookie,加代理,修改ua)
# main.py from scrapy.cmdline import execute execute([‘scrapy‘,‘crawl‘,‘cnblogs2‘]) # spiders/cnblogs2.py import scrapy from scrapy.http import Request class CnblogsSpider(scrapy.Spider): name = ‘cnblogs2‘ start_urls = [‘https://www.baidu.com/‘] def parse(self,response): print(response) yield Request(‘https://www.baidu.com/?w=python‘) # middlewares.py class CnblogsCrawlDownloaderMiddleware(object): def get_proxy(self): # 代理池用之前proxy_pool项目,注意先把redis清空,再用proxy_pool爬取,否则会有很多无用代理 import requests ret = requests.get(‘http://127.0.0.1:5010/get‘).json()[‘proxy‘] print(ret) return ret def process_request(self, request, spider): # 1 加cookie(request.cookies就是访问该网站的cookie) # 从你的cookie池中取出来的,字典 # request.cookies = {‘name‘:‘lqz‘,‘age‘:18} # print(request.cookies) # 2 加代理 # print(request.meta) # {‘depth‘: 1, ‘download_timeout‘: 180.0} depth一开始没有,后面变为1,每次加1,是爬虫的优先级 request.meta[‘proxy‘] = self.get_proxy() print(request.meta[‘proxy‘]) # 3 修改ua 通常高层单例,放在类属性里 from fake_useragent import UserAgent ua = UserAgent(verify_ssl=False) request.headers[‘User-Agent‘] = ua.random print(request.headers) return None
# 在爬虫已启动,就打开一个chrom浏览器,以后都用这一个浏览器来爬数据 # 1 在爬虫中创建bro对象 bro = webdriver.Chrome(executable_path=‘/Users/liuqingzheng/Desktop/crawl/cnblogs_crawl/cnblogs_crawl/chromedriver‘) # 2 中间件中使用: spider.bro.get(request.url) text=spider.bro.page_source response=htmlResponse(url=request.url,status=200,body=text.encode(‘utf-8‘)) return response # 3 关闭,在爬虫中 def close(self, reason): self.bro.close() # 注意:参考前一篇博客scrapy框架图右侧下载中间件到DOWNLOADER,本来是异步下载,中间件使用selenium会降低效率变为同步操作 本来下载器下载,是一个异步操作,换成seleniun,这条线程就成了同步,会一直等待数据加载回来,才进行后续操作 下载器用的是twisted框架,io多路复用,也就是说本来一个线程可以监听假设100个请求,现在换成selenium,只能处理一个请求了 原来是请求发出去,不需要等着回应,还可以继续发出很多的请求,有回来才处理,换成selenium,就必须等着它回来,这样就没法干其他事了,性能就下来了
代码示例:(本身应该在process_request添加selenium,在这response加相当于返回再次调度请求。此处这样做只是验证)
# main.py from scrapy.cmdline import execute execute([‘scrapy‘,‘crawl‘,‘cnblogs2‘]) # spiders/cnblogs2.py import scrapy from scrapy.http import Request from selenium import webdriver class CnblogsSpider(scrapy.Spider): name = ‘cnblogs2‘ # 单例,保证每次中间件调用打开的是同一个浏览器对象 bro = webdriver.Chrome(executable_path=‘D:oldboy_edupython_codeday110cnblogs_crawlcnblogs_crawlchromedriver.exe‘) start_urls = [‘https://www.baidu.com/‘] def parse(self,response): print(response.text) yield Request(‘https://www.baidu.com/?w=python‘) def close(self,reason): # 爬虫全部结束运行 self.bro.close() # 关闭selenium对象 # middlewares.py class CnblogsCrawlDownloaderMiddleware(object): # 本身应该在process_request添加selenium,在这response加相当于返回再次调度请求。此处这样做只是验证 def process_response(self, request, response, spider): # from selenium import webdriver from scrapy.http import HtmlResponse # bro = webdriver.Chrome(executable_path=‘D:oldboy_edupython_codeday110cnblogs_crawlcnblogs_crawlchromedriver.exe‘) spider.bro.get(request.url) # 每次使用同一个selenium对象爬取 # spider.bro.get(‘https://www.jd.com‘) text = spider.bro.page_source response=HtmlResponse(url=request.url,body=text.encode(‘utf-8‘)) # 源码body要写成二进制 return response
用于更换请求头头中的user-agent,相当于从已有列表中取
# 请求头中的user-agent list=[‘‘,‘‘] # pip3 install fake-useragent # https://github.com/hellysmile/fake-useragent 参考官网 from fake_useragent import UserAgent ua=UserAgent(verify_ssl=False) print(ua.random)
# 去重源码分析 # from scrapy.core.scheduler import Scheduler # Scheduler下:def enqueue_request(self, request)方法判断是否去重 if not request.dont_filter and self.df.request_seen(request): Requests对象,RFPDupeFilter对象 # 如果要自己写一个去重类 -写一个类,继承BaseDupeFilter类 -重写def request_seen(self, request): -在setting中配置:DUPEFILTER_CLASS = ‘项目名.dup.UrlFilter‘ # scrapy起始爬取的地址 def start_requests(self): #真正的入口,可以重写 for url in self.start_urls: yield Request(url) # 重写去重类的目的有以下两个 -增量爬取(100链接,150个链接) -已经爬过的,放到某个位置(mysql,redis中:集合) -如果用默认的,爬过的地址,放在内存中,只要项目一重启,就没了,它也不知道我爬过那个了,所以要自己重写去重方案 -你写的去重方案,占得内存空间更小 -bitmap方案 -BloomFilter布隆过滤器 from scrapy.http import Request from scrapy.utils.request import request_fingerprint # 这种网址是一个 requests1=Request(url=‘https://www.baidu.com?name=lqz&age=19‘) requests2=Request(url=‘https://www.baidu.com?age=18&name=lqz‘) ret1=request_fingerprint(requests1) ret2=request_fingerprint(requests2) print(ret1) print(ret2) # bitmap去重 一个小格表示一个连接地址 32个连接,一个比特位来存一个地址 # https://www.baidu.com?age=18&name=lqz ---》44 # https://www.baidu.com?age=19&name=lqz ---》89 # c2c73dfccf73bf175b903c82b06a31bc7831b545假设它占4个bytes,4*8=32个比特位 # 存一个地址,占32个比特位 # 10个地址,占320个比特位 #计算机计量单位 # 比特位:只能存0和1 # 8个比特位是一个bytes # 1024bytes=1kb # 1024kb=1m # 1024m=1g # 布隆过滤器:原理和python中如何使用 def request_seen(self, request): # 把request对象传入request_fingerprint得到一个值:aefasdfeasd # 把request对象,唯一生成一个字符串 fp = self.request_fingerprint(request) #判断fp,是否在集合中,在集合中,表示已经爬过,return True,他就不会再爬了 if fp in self.fingerprints: return True # 如果不在集合中,放到集合中 self.fingerprints.add(fp) if self.file: self.file.write(fp + os.linesep)
布隆过滤器
# 布隆过滤器:原理和python中如何使用 存在内存中,可以存到redis里。 # 原本scarpy是在内存用set去重,一旦数据量大,set会很大,吃内存。使用布隆过滤器,减小内存容量 # 参考:https://www.cnblogs.com/xiaoyuanqujing/protected/articles/11969224.html
简介

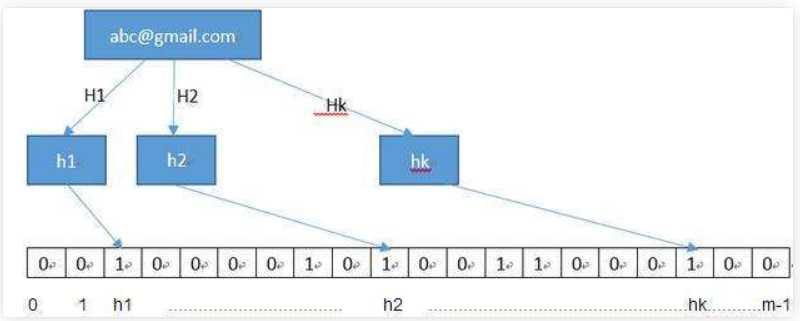

python中使用布隆过滤器
#python3.6 安装 #需要先安装bitarray pip3 install bitarray-0.8.1-cp36-cp36m-win_amd64.whl(pybloom_live依赖这个包,需要先安装) #下载地址:https://www.lfd.uci.edu/~gohlke/pythonlibs/ pip3 install pybloom_live
示例一
#ScalableBloomFilter 可以自动扩容 from pybloom_live import ScalableBloomFilter bloom = ScalableBloomFilter(initial_capacity=100, error_rate=0.001, mode=ScalableBloomFilter.LARGE_SET_GROWTH) url = "www.cnblogs.com" url2 = "www.liuqingzheng.top" bloom.add(url) print(url in bloom) print(url2 in bloom)
示例二
#BloomFilter 是定长的 from pybloom_live import BloomFilter bf = BloomFilter(capacity=1000) url=‘www.baidu.com‘ bf.add(url) print(url in bf) print("www.liuqingzheng.top" in bf)
# 1 安装pip3 install scrapy-redis # 源码部分,不到1000行, # 1 原来的爬虫继承 from scrapy_redis.spiders import RedisSpider class CnblogsSpider(RedisSpider): #start_urls = [‘http://www.cnblogs.com/‘] redis_key = ‘myspider:start_urls‘ # 2 在setting中配置 SCHEDULER = "scrapy_redis.scheduler.Scheduler" DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter" ITEM_PIPELINES = { ‘scrapy_redis.pipelines.RedisPipeline‘: 300 # 这里也可以用自己的保存在本地 } # 设置redis(如果是默认的,可以不配置) REDIS_HOST = ‘...‘ REDIS_PORT = 6379 REDIS_PARAMS={ ‘password‘:‘admin123‘, } # 3 多台机器上启动scrapy # 4 向reids中发送起始url,然后scrapy开始抢 lpush myspider:start_urls https://www.cnblogs.com # myspider:start_urls对应爬虫类中的redis_key 注:控制台redis操作 >redis-cli #进入redis >auth 密码 #如果有密码就输入密码 >lpush myspider:start_urls https://www.cnblogs.com
# 编译型语言和解释型语言 # python,js,php 解释型: 一定要有个解释器 (全都夸平台,在不同平台装不通平台的解释器即可) # 编译型语言:c,c++ java(有人说是编译型,有人说是解释型) -java:jdk,jre,jvm(三个分别是啥) -jdk:java开发环境(开发人员要装) -jre:java运行环境(要运行java程序,必须装) -jvm:java虚拟机,所有的java程序必须运行在虚拟机之上 -java对外发布:跨平台,一处编码,处处运行(1990年) -java编译----》字节码文件(.class文件)----》字节码文件在jvm上运行---》在不同平台装不通java虚拟---》实现了跨平台 -java:1.5---》古老 1.6 1.7 ---》java 8(用的还比较多)---》java9 ---》java13 -c语言:写完了,想在windwos下运行----》跑到windows机器下编译成可执行文件 -想在linux下运行----》跑到linux机器下编译成可执行文件 -linux上装python环境(源码安装,make,make install) -go编译型:跨平台编译(在windows上可以编译出linux下可执行文件)---》2009年--》微服务 -所有代码都编译成一个可执行文件(web项目---》编译之后---》可执行文件---》丢到服务器就能执行,不需要安装任何依赖) -java要运行---》最低最低要跑在java虚拟机之上(光jvm要跑起来,就占好几百m内存)---》 -安卓手机app--java开发的---》你的安卓手机在上面跑了个jvm -go:就是个可执行文件(go的性能比java高,他俩不相上下),阿里:自己写了jvm -安卓:谷歌,---->当时那个年代,java程序员多---》java可以快速转过去---》 -谷歌:Kotlin:---》用来取代java---》写安卓---》在国际上排名比go高 -同年ios/mac软件:object-c-----》swift(苹果的一个工程师,没事的时候,写的一个语言)---》过了没几年,跳槽去了facebook----》 -java:sun公司出的,后来被甲骨文收购了,开始恶心人---》把java做成收费---》一门收费 -c#:微软的:一开始收费,比java要好,没人用,免费,开源了,也没人用 -java se java ee java me -python写的代码,用打包工具,打包成exe----》把代码和解释器统统打包到exe中了 -垃圾回收机制:挺高端
# 1 代码发布系统 +cmdb+监控+日志---》devops平台、自动化运维平台 # 2 go挺高级(并发)前端,mysql,redis,mongodb,es 缺了个go的web框架,orm -beego:中国人写的(跟django很像。orm,中间件。。。。。)https://beego.me/docs/intro/ -gin:老外写的(flask,没有orm ),gorm https://github.com/gin-gonic/gin -Iris:
bilibili爬视频参考
https://www.cnblogs.com/xiaoyuanqujing/articles/12014416.html
注意:bilibili视频爬取分为音频和视频两种文件,因为bilibili要做到视频可以根据不同清晰度进行切换
‘‘‘ 通过该程序下载的视频和音频是分成连个文件的,没有合成, 视频为:视频名_video.mp4 音频为:视频名_audio.mp4 修改url的值,换成自己想下载的页面节课 ‘‘‘ # 导入requests模块,模拟发送请求 import requests # 导入json import json # 导入re import re # 定义请求头 headers = { ‘Accept‘: ‘*/*‘, ‘Accept-Language‘: ‘en-US,en;q=0.5‘, ‘User-Agent‘: ‘Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36‘ } # 正则表达式,根据条件匹配出值 def my_match(text, pattern): match = re.search(pattern, text) print(match.group(1)) print() return json.loads(match.group(1)) def download_video(old_video_url, video_url, audio_url, video_name): headers.update({"Referer": old_video_url}) print("开始下载视频:%s" % video_name) video_content = requests.get(video_url, headers=headers) print(‘%s视频大小:‘ % video_name, video_content.headers[‘content-length‘]) audio_content = requests.get(audio_url, headers=headers) print(‘%s音频大小:‘ % video_name, audio_content.headers[‘content-length‘]) # 下载视频开始 received_video = 0 with open(‘%s_video.mp4‘ % video_name, ‘ab‘) as output: while int(video_content.headers[‘content-length‘]) > received_video: headers[‘Range‘] = ‘bytes=‘ + str(received_video) + ‘-‘ response = requests.get(video_url, headers=headers) output.write(response.content) received_video += len(response.content) # 下载视频结束 # 下载音频开始 audio_content = requests.get(audio_url, headers=headers) received_audio = 0 with open(‘%s_audio.mp4‘ % video_name, ‘ab‘) as output: while int(audio_content.headers[‘content-length‘]) > received_audio: # 视频分片下载 headers[‘Range‘] = ‘bytes=‘ + str(received_audio) + ‘-‘ response = requests.get(audio_url, headers=headers) output.write(response.content) received_audio += len(response.content) # 下载音频结束 return video_name if __name__ == ‘__main__‘: # 换成你要爬取的视频地址 url = ‘https://www.bilibili.com/video/BV1g7411273a‘ # 发送请求,拿回数据 res = requests.get(url, headers=headers) # 视频详情json playinfo = my_match(res.text, ‘__playinfo__=(.*?)</script><script>‘) # 视频内容json initial_state = my_match(res.text, r‘__INITIAL_STATE__=(.*?);(function()‘) # 视频分多种格式,直接取分辨率最高的视频 1080p video_url = playinfo[‘data‘][‘dash‘][‘video‘][0][‘baseUrl‘] # 取出音频地址 audio_url = playinfo[‘data‘][‘dash‘][‘audio‘][0][‘baseUrl‘] video_name = initial_state[‘videoData‘][‘title‘] print(‘视频名字为:video_name‘) print(‘视频地址为:‘, video_url) print(‘音频地址为:‘, audio_url) download_video(url, video_url, audio_url, video_name)
以上是关于爬虫5 scrapy框架2 全站爬取cnblogs, scarpy请求传参, 提高爬取效率, 下载中间件, 集成selenium, fake-useragent, 去重源码分析, 布隆过滤器, 的主要内容,如果未能解决你的问题,请参考以下文章
Python使用Scrapy爬虫框架全站爬取图片并保存本地(妹子图)
(Scrapy框架)爬虫2021年CSDN全站综合热榜标题热词 | 爬虫案例