Python使用Scrapy爬虫框架全站爬取图片并保存本地(妹子图)
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python使用Scrapy爬虫框架全站爬取图片并保存本地(妹子图)相关的知识,希望对你有一定的参考价值。
大家可以在Github上clone全部源码。
Github:https://github.com/williamzxl/Scrapy_CrawlMeiziTu
Scrapy官方文档:http://scrapy-chs.readthedocs.io/zh_CN/latest/index.html
基本上按照文档的流程走一遍就基本会用了。
Step1:
在开始爬取之前,必须创建一个新的Scrapy项目。 进入打算存储代码的目录中,运行下列命令:
scrapy startproject CrawlMeiziTu
该命令将会创建包含下列内容的 tutorial 目录:
CrawlMeiziTu/
scrapy.cfg
CrawlMeiziTu/
__init__.py
items.py
pipelines.py
settings.py
middlewares.py
spiders/
__init__.py
...
cd CrawlMeiziTu
scrapy genspider Meizitu http://www.meizitu.com/a/list_1_1.html
该命令将会创建包含下列内容的 tutorial 目录:
CrawlMeiziTu/
scrapy.cfg
CrawlMeiziTu/
__init__.py
items.py
pipelines.py
settings.py
middlewares.py
spiders/
Meizitu.py
__init__.py
...
我们主要编辑的就如下图箭头所示:
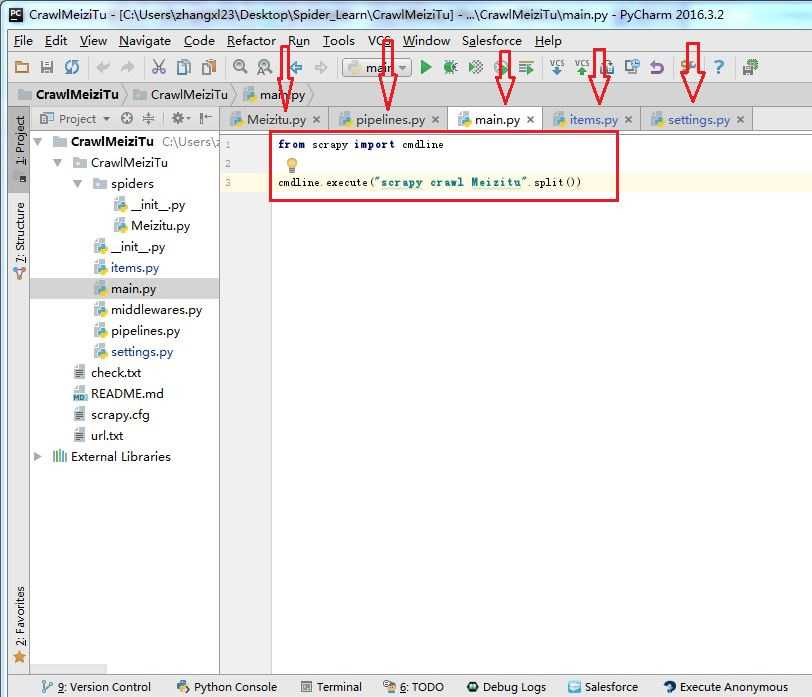
main.py是后来加上的,加了两条命令,主要为了方便运行。
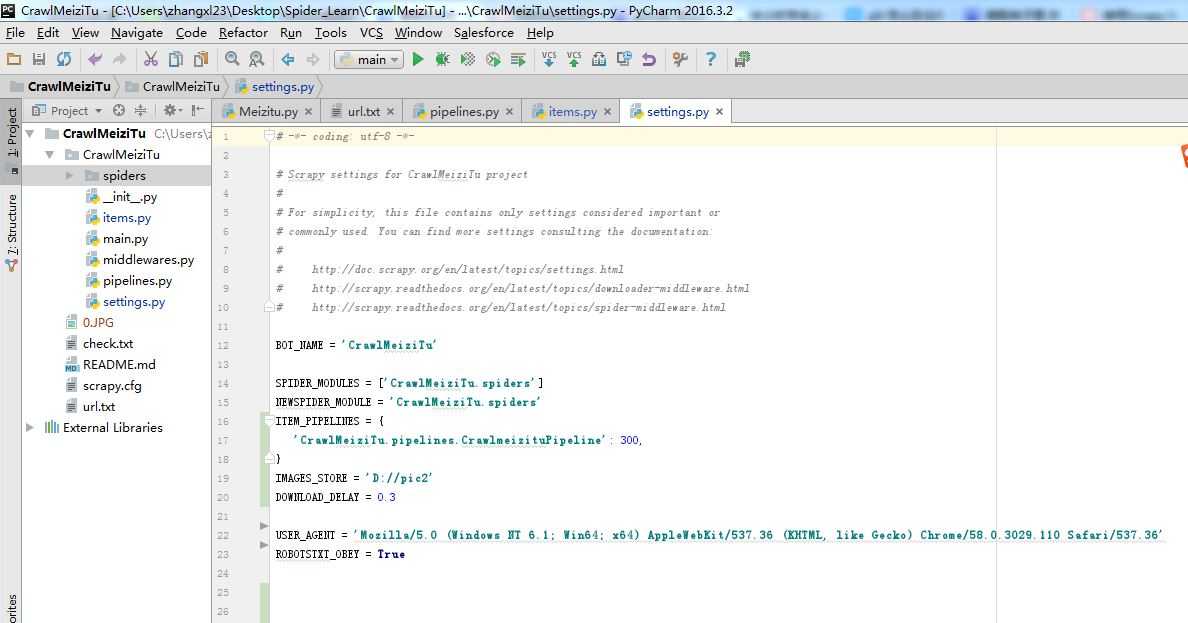
Step2:编辑Settings,如下图所示
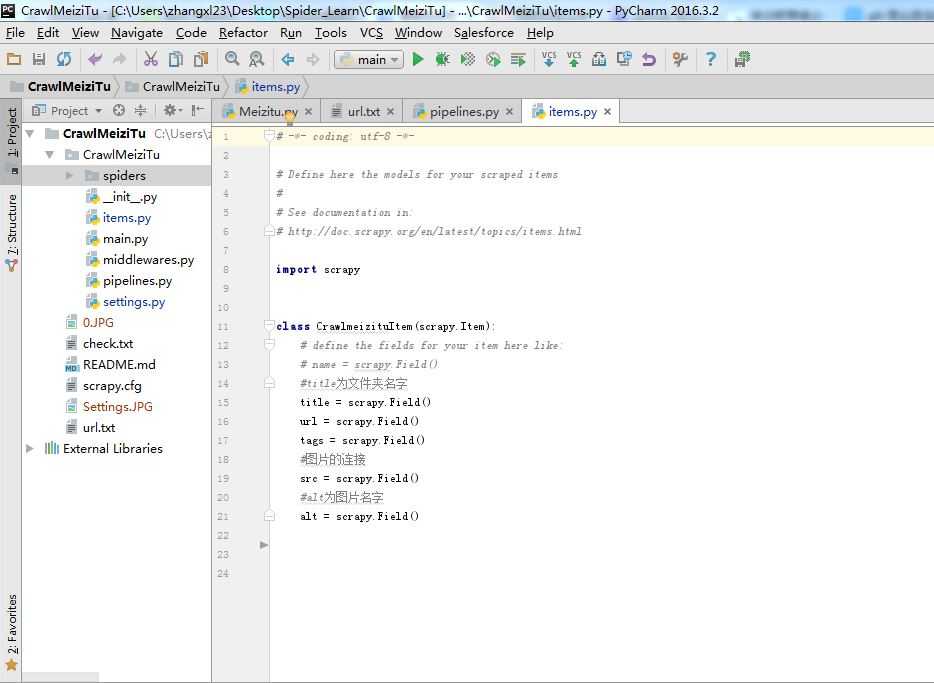
Step3:编辑Items.
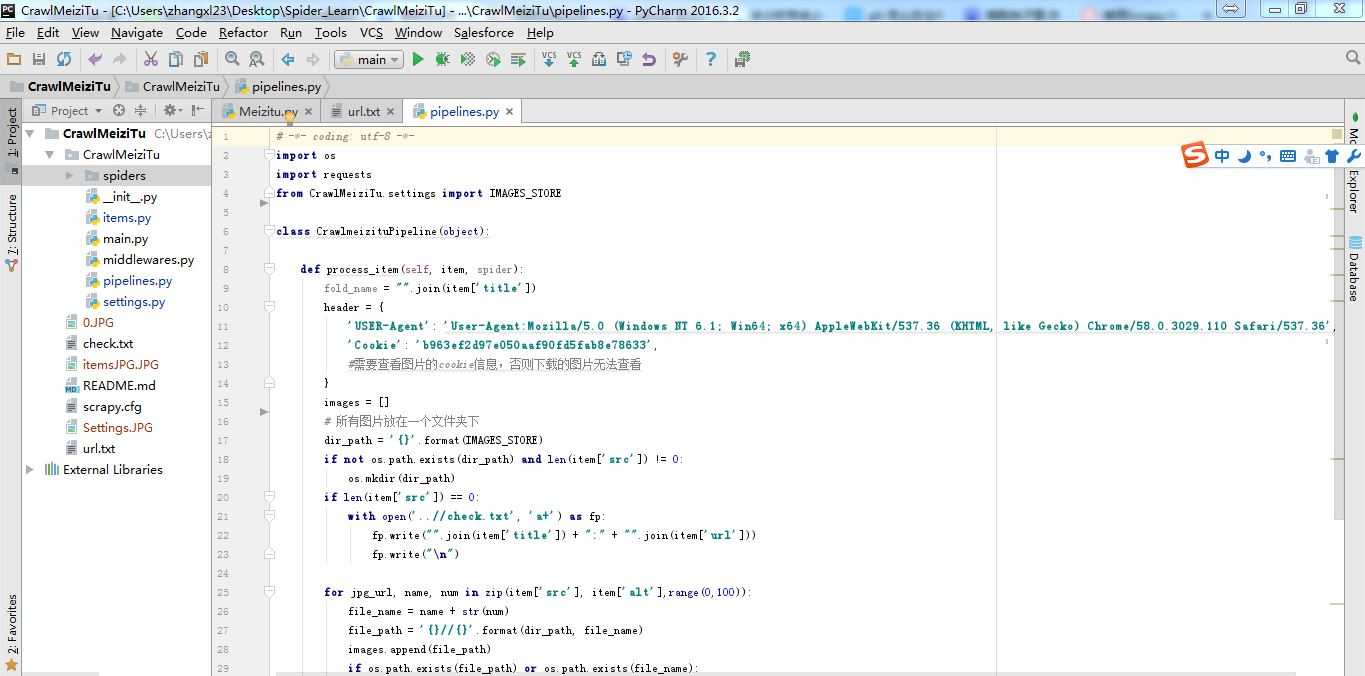
Step4:编辑Pipelines
Step5:编辑Meizitu的主程序。
以上是关于Python使用Scrapy爬虫框架全站爬取图片并保存本地(妹子图)的主要内容,如果未能解决你的问题,请参考以下文章
Python网络爬虫之Scrapy框架(CrawlSpider)
爬虫学习 16.Python网络爬虫之Scrapy框架(CrawlSpider)
Python爬虫入门21: 知乎网全站用户爬虫 scrapy