哈希表(散列表)
Posted zzsy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了哈希表(散列表)相关的知识,希望对你有一定的参考价值。
哈希表(散列表)
一、概述
根据设定的哈希函数H(key)和处理冲突的方法将一组关键字影像到一个有限的连续的地址集(区间)上,并以关键字在地址集中的“像”作为记录在表中的存储位置,这种表便成为哈希表,这一映像过程称为哈希造表或散列,所得存储位置称哈希地址或散列地址。
上面所提到的哈希函数是指:有一个对应关系 f ,使得每个关键字和结构中一个唯一的存储位置相对应,这样在查找时,我们不需要像传统的查找算法那样进行比较,而是根据这个对应关系 f 找到给定值K的像f(K)。
哈希函数也可叫哈希算法,它可以用于检验信息是否相同(文件校验),或者检验信息的拥有者是否真实(数字签名)。
哈希表是一种与数组、链表等不同的数据结构,与他们需要不断的遍历比较来查找的办法,哈希表设计了一个映射关系hash(key)= address,根据key来计算存储地址address,这样可以1次查找,hash既是存储数据过程中用来指引数据存储到什么位置的函数,也是将来查找这个位置的算法,叫做哈希算法。
这就是Hash表,首先Ta是一种数据结构,是一种效率极高的查找方式,哈希表的核心在于哈希函数的设计,哈希冲突了不要紧,我们要增加随机性以及对冲突进行适当的有损化的处理。
- python中字典就是哈希数据类型,在这里我就不用代码实现哈希数据结构了
- 这里总结一下,散列表适合用于:
模拟映射关系;
防止重复;
缓存/记住数据,以免服务器再通过处理来生成它们。
二、哈希函数构造方法
构造哈希函数的方法有很多。在介绍各种方法前,首先需要明确什么是“好” 的哈希算法。若对于关键字集合中的任一个关键字,经哈希函数映像到地址集合中任何一个地址的概率是相等的,则称此类哈希函数是均匀的(Uniform)哈希函数。换句话说,就是使关键字经过哈希函数得到一个“随机的地址”,以便使一组关键字的哈希地址均匀分布在整个地址区间中,从而减少冲突。(这里我就不详细介绍哈希函数构造方法了)
- 哈希函数构造方法:直接定址法、数字分析法、折叠法、平方取中法、除留余数法、随机数法。
- 处理冲突方法:开放定址法、再哈希法、链地址法。
三、哈希函数的用处
-
比较文件
-
另一种散列函数是安全散列算法(secure hash algorithm,SHA)函数。给定一个字符串,SHA返回其散列值。
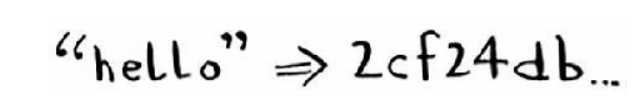
这里的术语有点令人迷惑。SHA是一个散列函数,它生成一个散列值 — 一个较短的字符串。用于创建散列表的散列函数根据字符串生成数组索引,而SHA根据字符串生成另一个字符串。对于每个不同的字符串,SHA生成的散列值都不同。
?

-
? SHA 生成的散列值很长,这里截短了。
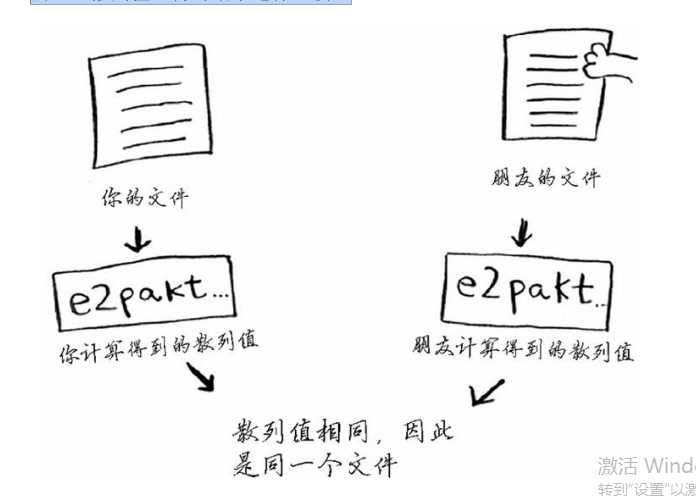
- 你可使用SHA来判断两个文件是否相同,这在比较超大型文件时很有用。假设你有一个4 GB的文件,并要检查朋友是否也有这个大型文件。为此,你不用通过电子邮件将这个大型文件发送给朋友,而可计算它们的SHA散列值,再对结果进行比较。
- 检查密码
SHA还让你能在不知道原始字符串的情况下对其进行比较。例如,假设Gmail遭到攻击,攻击者窃取了所有的密码!你的密码暴露了吗?没有,因为Google存储的并非密码,而是密码的SHA散列值!(MD5算法就是SHA散列值)你输入密码时,Google计算其散列值,并将结果同其数据库中的散列值进行比较。
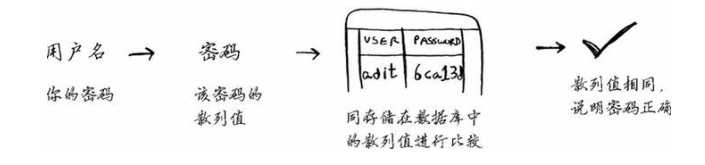
Google只是比较散列值,因此不必存储你的密码!SHA被广泛用于计算密码的散列值。这种散列算法是单向的。你可根据字符串计算出散列值。但你无法根据散列值推断出原始字符串。这意味着计算攻击者窃取了Gmail的SHA散列值,也无法据此推断出原始密码!你可将密码转换为散列值,但反过来不行。SHA实际上是一系列算法:SHA-0、SHA-1、SHA-2和SHA-3。本书编写期间,SHA-0和SHA-1已被发现存在一些缺陷。如果你要使用SHA算
法来计算密码的散列值,请使用SHA-2或SHA-3。当前,最安全的密码散列函数是bcrypt,但没有任何东西是万无一失的。
以上是关于哈希表(散列表)的主要内容,如果未能解决你的问题,请参考以下文章