数据库表的拆分
Posted tina-zhu
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据库表的拆分相关的知识,希望对你有一定的参考价值。
将存放在同一个数据库中的数据分散存放到多个数据库上,实现分布存储,通过路由规则路由访问特定的数据库
这样一来每次访问面对的就不是单台服务器了,而是N台服务器,这样就可以降低单台机器的负载压力。
sqlserver 2005版本之后,可以友好的支持“表分区”。
垂直(纵向)拆分:是指按功能模块拆分,比如分为订单库、商品库、用户库…这种方式多个数据库之间的表结构不同。
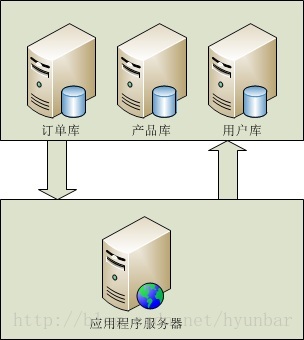
优点:
1. 拆分后业务清晰,拆分规则明确。
2. 系统之间整合或扩展容易。
3. 数据维护简单。
缺点:
1. 部分业务表无法join,只能通过接口方式解决,提高了系统复杂度。
2. 受每种业务不同的限制存在单库性能瓶颈,不易数据扩展跟性能提高。
3. 事务处理复杂。
水平(横向)拆分:将同一个表的数据进行分块保存到不同的数据库中,这些数据库中的表结构完全相同。
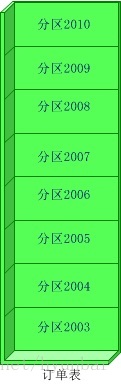
优点:
1. 不存在单库大数据,高并发的性能瓶颈。
2. 对应用透明,应用端改造较少。
3. 按照合理拆分规则拆分,join操作基本避免跨库。
4. 提高了系统的稳定性跟负载能力。
缺点:
1. 拆分规则难以抽象。
2. 分片事务一致性难以解决。
3. 数据多次扩展难度跟维护量极大。
4. 跨库join性能较差。
拆分的处理难点
(1)两种方式共同缺点
- 引入分布式事务的问题。
- 跨节点Join 的问题。
- 跨节点合并排序分页问题。
(2)针对数据源管理,目前主要有两种思路:
A. 客户端模式,在每个应用程序模块中配置管理自己需要的一个(或者多个)数据源,直接访问各个 数据库,在模块内完成数据的整合。
优点:相对简单,无性能损耗。
缺点:不够通用,数据库连接的处理复杂,对业务不够透明,处理复杂。
B. 通过中间代理层来统一管理所有的数据源,后端数据库集群对前端应用程序透明;
优点:通用,对应用透明,改造少。
缺点:实现难度大,有二次转发性能损失。
(3)拆分原则
- 尽量不拆分,架构是进化而来,不是一蹴而就。(SOA)
- 最大可能的找到最合适的切分维度。
- 由于数据库中间件对数据Join 实现的优劣难以把握,而且实现高性能难度极大,业务读取 尽量少使用多表Join -尽量通过数据冗余,分组避免数据垮库多表join。
- 尽量避免分布式事务。
- 单表拆分到数据1000万以内。
(4)拆分方案
范围、枚举、时间、取模、哈希、指定等
(5)案例分析
场景一
建立一个历史his系统,将公司的一些历史个人游戏数据保存到这个his系统中,主要是写入,还有部分查询,读写比约为1:4;由于是所有数据的历史存取,所以并发要求比较高;
分析:
历史数据
写多都少
越近日期查询越频繁?
什么业务数据?用户游戏数据
有没有大规模分析查询?
数据量多大?
保留多久?
机器资源有多少?
方案1:按照日期每月一个分片
带来的问题:1.数据热点问题(压力不均匀)
方案2:按照用户取模, –by Jerome 就这个比较合适了
带来的问题:后续扩容困难
方案3:按用户ID范围分片(1-1000万=分片1,xxx)
带来的问题:用户活跃度无法掌握,可能存在热点问题
场景二
建立一个商城订单系统,保存用户订单信息。
分析:
电商系统
一号店或京东类?淘宝或天猫?
实时性要求高
存在瞬时压力
基本不存在大规模分析
数据规模?
机器资源有多少?
维度?商品?用户?商户?
方案1:按照用户取模,
带来的问题:后续扩容困难
方案2:按用户ID范围分片(1-1000万=分片1,xxx)
带来的问题:用户活跃度无法掌握,可能存在热点问题
方案3:按省份地区或者商户取模
数据分配不一定均匀
场景三
上海公积金,养老金,社保系统
分析:
社保系统
实时性要求不高
不存在瞬时压力
大规模分析?
数据规模大
数据重要不可丢失
偏于查询?
方案1:按照用户取模,
带来的问题:后续扩容困难
方案2:按用户ID范围分片(1-1000万=分片1,xxx)
带来的问题:用户活跃度无法掌握,可能存在热点问题
方案3:按省份区县地区枚举
数据分配不一定均匀
以上是关于数据库表的拆分的主要内容,如果未能解决你的问题,请参考以下文章