多目标跟踪:CVPR2019论文阅读
Posted wujianming-110117
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了多目标跟踪:CVPR2019论文阅读相关的知识,希望对你有一定的参考价值。
多目标跟踪:CVPR2019论文阅读
Robust Multi-Modality Multi-Object Tracking
论文链接:https://arxiv.org/abs/1909.03850
代码链接:https://github.com/ZwwWayne/mmMOT
摘要
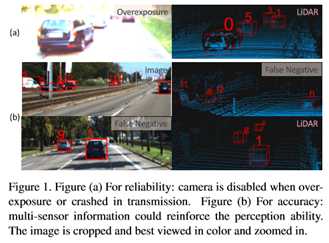
在自主驾驶系统中,多传感器感知是保证系统可靠性和准确性的关键,而多目标跟踪(MOT)则是通过跟踪动态目标的序列运动来提高系统的可靠性和准确性。目前大多数的多传感器多目标跟踪方法要么依赖于单一的输入源(如中心摄像机)而缺乏可靠性,要么在后处理过程中融合多个传感器的结果而不充分利用固有信息而不够精确。在本研究中,本文设计了一个通用的传感器不可知多模态MOT框架(mmMOT),其中每个模态(即传感器)能够独立地执行其角色以保持可靠性,并通过一个新的多模态融合模块进一步提高其精度。本文的mmMOT可以以端到端的方式进行训练,能够联合优化每个模态的基本特征提取器和交叉模态的邻接估计器。本文的mmMOT还首次尝试在MOT的数据关联过程中对点云的深度表示进行编码。本文进行了广泛的实验,以评估提出的框架对具有挑战性的基蒂基准的有效性,并报告最新的表现。
1. Introduction
本文在融合模块上进行了广泛的实验,并在KITTI跟踪数据集上评估了本文的框架[13]。在没有铃声和口哨声的情况下,本文在在线设置下,纯粹依靠图像和点云,在KITTI跟踪基准[13]上取得了最新的结果,本文在单一模态(传感器故障条件下)下,通过相同模型得到的结果也具有竞争力(仅差0.28%)。
总之,本文的贡献如下:
1) 本文提出了一个多模态MOT框架,其中包含一个稳健的融合模块,利用多模态信息来提高可靠性和准确性。
2) 本文提出了一种新的端到端训练方法,使连接能够优化跨模态推理。
3) 本文首次尝试应用pointcloud的深层特征进行跟踪,并获得具有竞争力的结果。
2. Related Work
多目标跟踪框架
最近对MOT的研究主要遵循检测跟踪范式[6,11,38,50],其中感兴趣的对象首先由对象检测器获得,然后通过数据关联连接到轨迹。数据关联问题可以从不同的角度来解决,例如最小代价流[11,20,37]、马尔可夫决策过程(MDP)[48]、部分滤波[6]、匈牙利赋值[38]和图割[44,49]。然而,这些方法大多不是以端到端的方式训练的,因此许多参数是启发式的(例如,成本权重),并且容易受到局部最优的影响。在最小成本流动框架内实现端到端学习,Schulteretal。[37]通过平滑线性规划应用双层优化,深度结构模型(DSM)[11]利用铰链损耗。然而,它们的框架并不是为跨模态而设计的。本文通过邻接矩阵学习来解决这个问题。除了不同的数据关联范式外,相关特征也被广泛地用来确定检测之间的关系。目前以图像为中心的方法[11,35,38,50]主要使用图像的深特征块。手工制作的特征偶尔用作辅助输入,包括但不限于边界框[15]、几何信息[27]、形状信息[38]和时间信息[45]。三维信息也有好处,因此可以通过三维检测预测[11]或使用神经网络[36]或几何先验[38]从RGB图像估计来利用。Osep等人[25]融合了来自RGB图像、立体声、视觉里程表和可选场景流量的信息,但它不能以端到端的方式进行调节。所有上述方法必须与相机配合,缺乏可靠性。相比之下,本文的mmMOT独立地从每个传感器中提取特征(包括深度图像特征和点云的深度表示),并且每个传感器都扮演着同样重要的角色,它们可以被分离。提出的注意引导融合机制进一步提高了融合精度。
点云的深度表示
传统的点云跟踪方法是测量距离[31],提供2.5D网格表示[2,10]或派生一些手工制作的特征[42]。它们都没有充分利用点云的固有信息来解决数据关联问题。最近的研究[3,7,24]已经证明了在自动驾驶中使用3D点云作为感知特征的价值。为了学习点云的良好深度表示,PointNet[29]和PointNet++[30]使用对称函数处理原始的非结构化点云。本文在框架中采用了这种有效的方法。其他研究,如point SIFT[17]提出了一种方向编码单元来学习点云的SIFT样特征,而3dsmouthNet[14]则学习了体素化的平滑密度值表示。还有一些方法[46,47]将点云投影到球体上,因此2D CNN可以应用于分割任务。
目标检测
目标检测器也是逐点跟踪的重要组成部分。自R-CNN的快速发展以来,用于2D目标检测的深度学习方法有了很大的改进[23,32,43]。三维目标检测近年来受到越来越多的关注。为了同时利用图像和点云,一些方法[8,18]从不同的角度聚集点云和图像特征,而F-PointNet[28]从图像中获取截头体建议,然后应用PointNet[29]对点云进行三维目标定位。有一些最先进的方法[19,39,51]只使用点云。一级检测器[19,51]通常将CNN应用于体素化表示,两级检测器如PointRCNN[39]首先通过分割生成建议,在第二级重新定义。本文的mmMOT很容易适应二维和三维物体探测器。
3. Multi-Modality Multi-Object Tracking
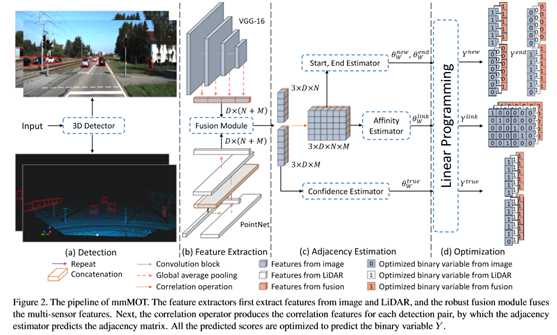
提出了一种多模态MOT(mmMOT)框架,该框架通过独立的多传感器特征提取来保持可靠性,通过模态融合来提高精度。它通常遵循从最小成本流角度广泛采用的检测跟踪范式。具体来说,本文的框架包含四个模块,包括目标检测器、特征提取、邻接估计和最小代价流优化器,分别如图2(a),(b),(c),(d)所示。
首先,使用任意目标检测器定位感兴趣的目标。为了方便起见,本文使用PointPillar[19]。
第二,特征提取器为每次检测独立地从每个传感器中提取特征,然后应用融合模块对单模态特征进行融合并将其传递给邻接估计器。邻接估计是模态不可知的。它推断出最小成本流量图计算所需的分数。文中给出了邻接估计的结构和相应的端到端学习方法。最小成本流优化器是一个线性规划求解器,它根据预测得分确定最优解。
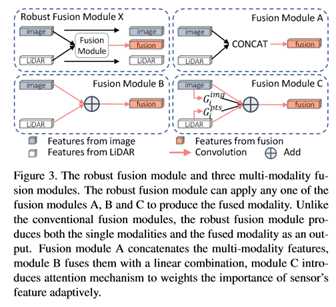
为了利用不同级别的特性,本文修改了池化层[4],以便将不同级别的特性传递到顶部,如图2所示的VGG网络所示。健壮的融合模块可以使用任意的融合模块,本文研究了三个融合模块,如图3所示。以两个传感器的设置为例,融合模块A天真地将多个模式的特征串联起来;模块B将这些特征相加;模块C引入注意机制。
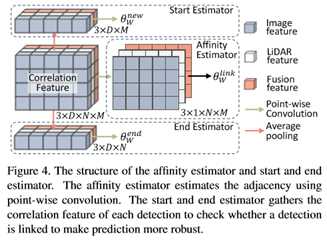
由于相关操作在批处理维度中处理多模态,并且在两帧之间的每个检测对上执行,因此相关特征映射的大小为3×D×N×M。本文使用二维逐点卷积,如图4所示。
4. Experiments
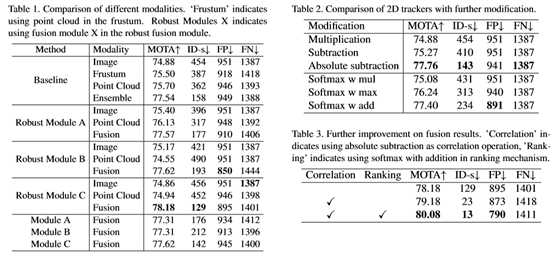
本文设置了一个二维跟踪器作为基线,该跟踪器只使用二维图像块作为线索,在数据关联时使用乘法作为相关算子,没有排序机制。本文首先比较了图像点云和激光雷达点云的有效性,并评估了两种使用点云的方法:在椎体中使用点云或在边界框中使用点云。从表1中的基线行可以看出,在截头台中使用点云会产生与在边界框中使用点云相同的竞争结果。
如表1所示,尽管所有融合方法都超过了单传感器基线,但只有具有注意机制的鲁棒融合模块C显著优于集成结果。结果表明,对于多传感器输入,找到一个鲁棒的融合模块是非常重要的。由于每个具有鲁棒融合模块的方法也提供了单个传感器的预测,因此本文在表1中比较了每个鲁棒融合模块的单个传感器结果。可以观察到,虽然所提出的鲁棒模块能够有效地融合多模态,但与基线(其中进行了单模态的专门训练)相比,它可以在单模态上保持竞争性能。这种融合的可靠性在文献中是新的。
本文进一步比较了常规融合模块的结果,后者只输出融合模态到邻接估计器,因此跟踪器在多模态设置下不能进行单模态跟踪。表1最后一行的结果表明,所提出的鲁棒模块在处理单一模态的额外能力方面,始终优于基线模块A、B和C。结果表明,在保证可靠性的前提下,mmMOT得到了更多的有利的监测信号,从而进一步提高了精度。
进一步改进了融合模型的结果。根据表2中的结论,本文使用绝对减法进行相关操作,使用加法激活softmax进行排名机制。本文比较了表3中每个修改的效果。绝对相减相关使融合模型的MOTA提高了1,而带加法的softmax激活进一步提高了MOTA,使ID开关的数目减少到13,这是一个显著的改进。
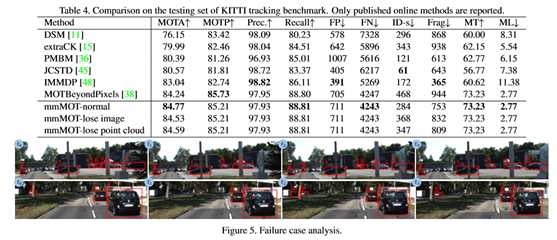
本文使用MOT提供的超过像素的RRC网[32]的2D检测来获得最新的和有竞争力的结果[38]。本文使用PointNet[30]来处理截锥中的点云,使用VGG-16[40]来处理图像块。更多细节见补充材料。表4将本文的方法与其他已发布的最新在线方法进行了比较。本文首先使用所有的方式测试mmMOT,即mmMOT正常。然后通过将单一模态传递到同一模型,即mmMOT丢失图像/点云,模拟传感器失效情况。在这两种情况下,本文的mmMOT超过了MOTA上所有其他已发布的最新在线方法。
本文使用MOT提供的超过像素的RRC网[32]的2D检测来获得最新的和有竞争力的结果[38]。本文使用PointNet[30]来处理截锥中的点云,使用VGG-16[40]来处理图像块。本文观察到几种可能导致本文的mmmot失败的情况。统计结果在补充材料中提供,示例如图5所示,其中每行包括视频中的四个连续帧。首先,对于远处的物体,2D检测器引起的早期错误将导致假阴性检测,如第一排ID9的汽车所示。
5. Conclusion
提出了一种多模态多目标跟踪框架mmMOT。本文首次尝试通过深度端到端网络来避免单一传感器的不稳定性,从而保持多模态的有效性。这样一种功能在社区中被忽视了。本文的框架通过邻接矩阵学习以端到端的方式获得,因此可以在一段时间内获得更大的误差。此外,该框架首次将激光雷达点云的深度表示引入到数据关联问题中,增强了多流框架对传感器故障的鲁棒性。
以上是关于多目标跟踪:CVPR2019论文阅读的主要内容,如果未能解决你的问题,请参考以下文章
论文速递CVPR2022 : 用于对象跟踪的统一transformer跟踪器