百度热搜数据爬取及分析
Posted l1234
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了百度热搜数据爬取及分析相关的知识,希望对你有一定的参考价值。
一、网络爬虫设计方案
1、爬虫名称:百度汽车热搜
2、内容:爬取百度不同汽车的热搜指数
3、概述:首先查找源代码,分析请求方式和url地址,再使用requests模块获取网页源代码,再使用BeautifulSoup解析得到所需要的数据,然后使用matplotlib实现数据可视化分析,最后进行小结。
难点:回归直线
二、主题页面的结构特征分析
1.主题页面的结构与特征分析
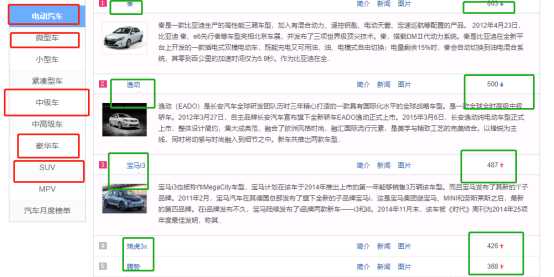
获取电动汽车、小型汽车、中级车、豪华车、SUV这五类汽车每一类的前五名的热搜车型和其对应的指数。
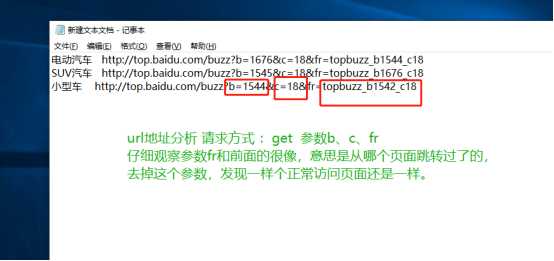
2.htmls页面解析
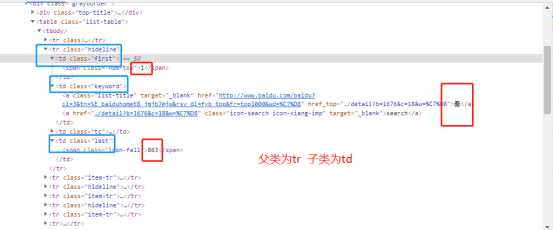
三、网络爬虫程序设计
1.数据爬取与采集
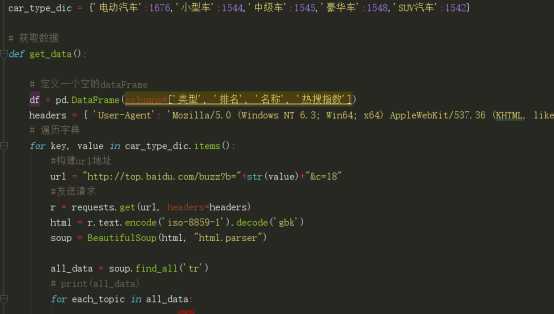
对数据进行清洗和处理
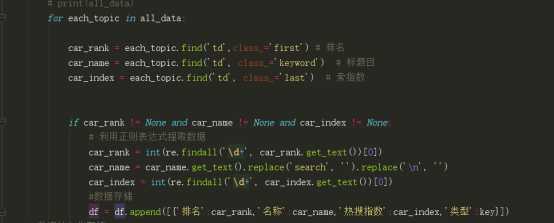
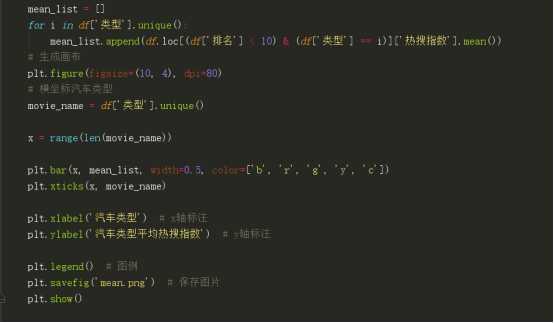
.数据分析与可视化(例如:数据柱形图、直方图、散点图、盒图、分布图)
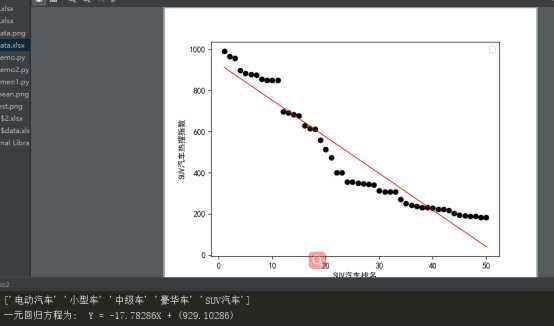
.根据数据之间的关系,分析两个变量之间的相关系数,画出散点图,并建立变量之间的回归方程(一元或多元)
数据持久化
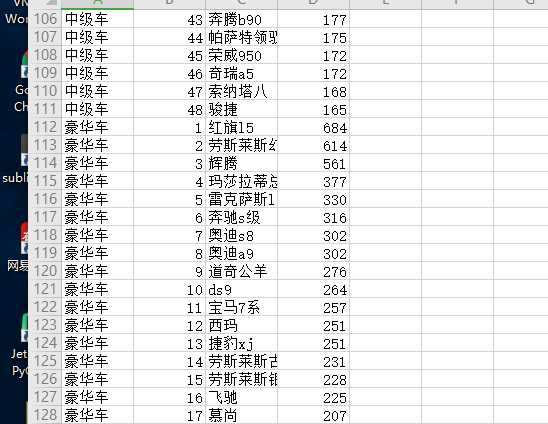
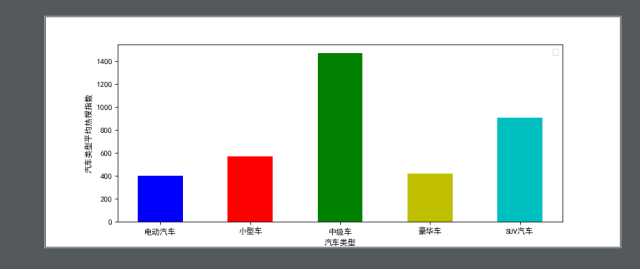
四、结论:人们对大多喜欢中级车,且SUV类型较多。
小结:经过爬虫学习后,加强了自己requests、matplot的掌握,和对sklearn的了解。
源代码:
‘‘‘ 获取百度汽车热搜数据 ‘‘‘ import requests from bs4 import BeautifulSoup import pandas as pd import matplotlib import matplotlib.pyplot as plt import re import numpy as np from sklearn.linear_model import LinearRegression # 设置matplotlib正常显示中文和负号 matplotlib.rcParams[‘font.sans-serif‘] = [‘SimHei‘] matplotlib.rcParams[‘axes.unicode_minus‘] = False # 定义一个字典方便构造url地址 car_type_dic = {‘电动汽车‘:1676,‘小型车‘:1544,‘中级车‘:1545,‘豪华车‘:1548,‘SUV汽车‘:1542} # 获取数据 def get_data(): # 定义一个空的dataFrame df = pd.DataFrame(columns=[‘类型‘, ‘排名‘, ‘名称‘, ‘热搜指数‘]) # 设置请求头 headers = { ‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)Chrome/69.0.3497.100 Safari/537.36‘} # 伪装爬虫 # 遍历字典,循环发送请求 for key, value in car_type_dic.items(): #构建url地址 url = "http://top.baidu.com/buzz?b="+str(value)+"&c=18" #发送请求 r = requests.get(url, headers=headers) #获取网页源代码 html = r.text #对代码进行编码解码,才能正常显示中文 html = html.encode(‘iso-8859-1‘).decode(‘gbk‘) #调用bs4解析代码 soup = BeautifulSoup(html, "html.parser") all_data = soup.find_all(‘tr‘) # print(all_data) for each_topic in all_data: # 排名 car_rank = each_topic.find(‘td‘,class_=‘first‘) # 标题目 car_name = each_topic.find(‘td‘, class_=‘keyword‘) # 索指数 car_index = each_topic.find(‘td‘, class_=‘last‘) # print(car_name,car_rank,car_index) #判断不能为空数据 if car_rank != None and car_name != None and car_index != None: # 利用正则表达式提取数据 # 排名 car_rank = int(re.findall(‘d+‘, car_rank.get_text())[0]) #汽车名 car_name = car_name.get_text().replace(‘search‘, ‘‘).replace(‘ ‘, ‘‘) # 热搜 car_index = int(re.findall(‘d+‘, car_index.get_text())[0]) #数据存储 df = df.append([{‘排名‘:car_rank,‘名称‘:car_name,‘热搜指数‘:car_index,‘类型‘:key}]) # 数据持久化存储 df.to_excel(‘data.xlsx‘,index=False) return df #画出每个类型前十名热搜平均值的柱状图 def mean_plt(df): #平均值列表 mean_list = [] type_list = df[‘类型‘].unique() for i in type_list: # 取出每个类型前十名的热搜指数 top_ten_data = df.loc[(df[‘排名‘] < 10) & (df[‘类型‘] == i)][‘热搜指数‘] #求平均值 mean_data = top_ten_data.mean() mean_list.append(mean_data) # 生成画布 plt.figure(figsize=(10, 4), dpi=80) # 横坐标汽车类型 type_name = type_list x = range(len(type_name)) plt.bar(x, mean_list, width=0.5, color=[‘b‘, ‘r‘, ‘g‘, ‘y‘, ‘c‘]) # 设置行对应的汽车类型 plt.xticks(x, type_name) # x轴标注 plt.xlabel(‘汽车类型‘) # y轴标注 plt.ylabel(‘汽车类型平均热搜指数‘) # 图例 plt.legend() # 保存图片 plt.savefig(‘mean.png‘) #显示 plt.show() # 画出电动汽车的折线图 def data_plt(df): #构造行 x = [i for i in range(9)] # 列数据 y = df.loc[(df[‘排名‘] < 10) & (df[‘类型‘] == ‘电动汽车‘)][‘热搜指数‘] # print(x) # print(y) plt.plot(x, y, lw=1, c=‘red‘, marker=‘s‘, ms=4, label=‘电动汽车折线图‘) # x轴的刻度 plt.xticks(x) # x轴标注 plt.xlabel(‘电动汽车排名‘) # y轴标注 plt.ylabel(‘电动汽车热搜指数‘) # 图例 plt.legend() # 保存图片 plt.savefig(‘data.png‘) #显示 plt.show() # 回归方程 def reg_plt(df): # x 为排名 x = np.asarray(df.loc[df[‘类型‘] == ‘SUV汽车‘][‘排名‘].values).reshape(-1, 1) # y为 热搜数据 y = np.asarray(df.loc[df[‘类型‘] == ‘SUV汽车‘][‘热搜指数‘].values).reshape(-1, 1) # 调用函数进行训练 reg = LinearRegression() reg = reg.fit(x, y) # 打印方程 print("一元回归方程为: Y = %.5fX + (%.5f)" % (reg.coef_[0][0], reg.intercept_[0])) plt.scatter(x, y, color=‘black‘) # 画图 plt.plot(x, reg.predict(x), color=‘red‘, linewidth=1) # x轴标注 plt.xlabel(‘SUV汽车排名‘) # y轴标注 plt.ylabel(‘SUV汽车热搜指数‘) # 图例 plt.legend() plt.show() # 函数入口 def main(): # 获取数据 df = get_data() # 折线图 data_plt(df) # 柱状图 mean_plt(df) # 散点图 和 一元线性回归方程 reg_plt(df) main()
以上是关于百度热搜数据爬取及分析的主要内容,如果未能解决你的问题,请参考以下文章