Python爬虫应用实战-网站数据爬取及数据分析
Posted 文宇肃然
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python爬虫应用实战-网站数据爬取及数据分析相关的知识,希望对你有一定的参考价值。
实战一:中国大学排名
前言
由于上一篇文章中教会了大家如何存储数据,但是由于篇幅过大,就没有加入实战篇。想必大家也等着急了吧,所以今天就为大家带来两篇实战内容,希望可以帮助到各位更好的认识到爬虫与mysql数据库结合的知识。
每年的6月都是高考的大日子,所有的学子都为自己的目标大学努力着,拼搏着,所以今天的第一篇实战就是为你们带来2020中国大学的排名情况,让各位小伙伴知道你自己的大学排名大概是多少。
需求分析与功能实现
爬取的网址如下:
https://www.shanghairanking.cn/rankings/bcur/202011
打开网站之后,你会看到映入眼帘的就是中国大学的排名情况,让我们看看我们需要的信息有哪些吧。
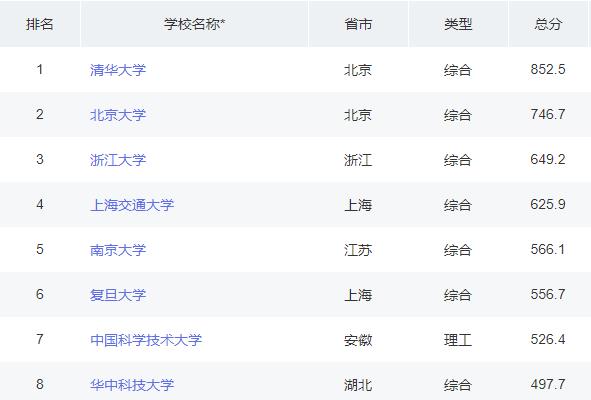
如上图所示,我们需要获取到学校的排名、学校的名称、学校所在的省份、该学校所属的类型以及大学的总分。
这些数据都保存在表格当中,因此我选用xpath提取表格数据。
具体代码如下所示:
# 解析网页提取信息
def parse_html(self, html):
rank_ids = []
university_names = []
provices = []
types = []
all_sorces = []
html = etree.HTML(html)
tr以上是关于Python爬虫应用实战-网站数据爬取及数据分析的主要内容,如果未能解决你的问题,请参考以下文章