Python网络爬虫课程设计
Posted 欧阳睿
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python网络爬虫课程设计相关的知识,希望对你有一定的参考价值。
一、选题的背景
为什么要选择此选题?要达到的数据分析的预期目标是什么?(10 分)
为了通过爬取网站获取的信息来分析现在网络上社会、经济、技术等各种信息网站的影响力排行,以此了解人们对哪种信息网站更青睐,访问的更加频繁。
二、主题式网络爬虫设计方案(10 分)
1.主题式网络爬虫名称
《Python爬虫对站长之家网站分类信息网站排行榜的爬取及分析》
2.主题式网络爬虫爬取的内容与数据特征分析
爬取内容:各类网站的网站名称,网址,Alexa周排名,反链数。
数据特征分析:Alexa周排名,反链数等数据可通过后续绘制直方图、散点图等观察数据的变化情况。
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
实现思路:本次设计方案主要使用request库爬取网页信息和beautifulSoup库来提取分类信息网站排行榜的信息。
三、主题页面的结构特征分析(10 分)
1.主题页面的结构特征

2. 通过F12,对页面进行检查,查看我们所需要爬取内容的相关代码
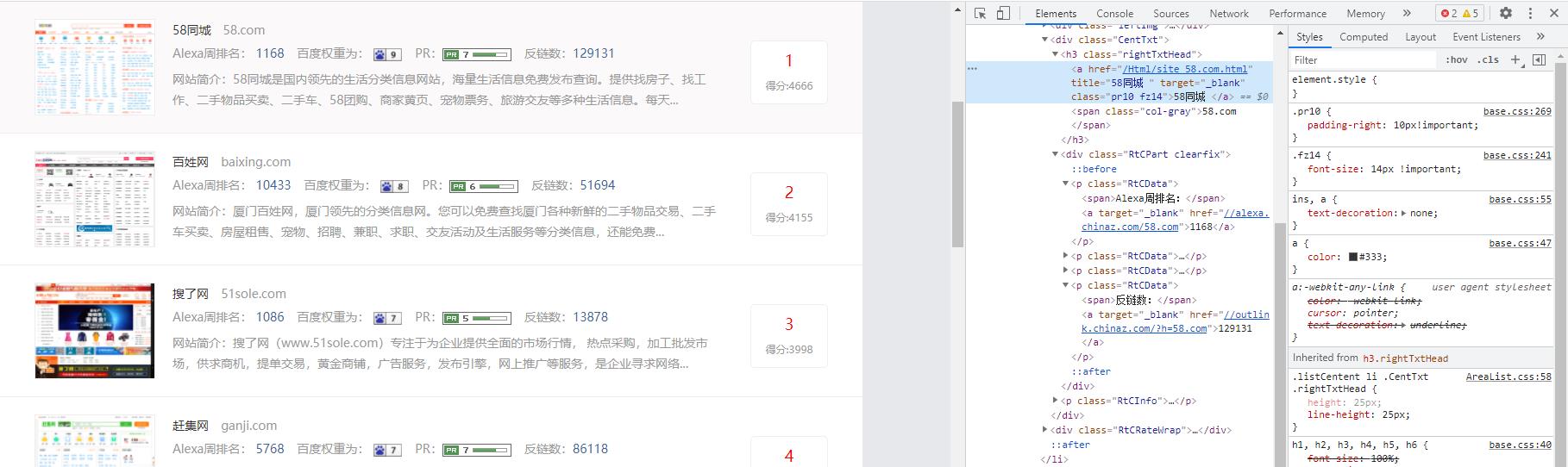
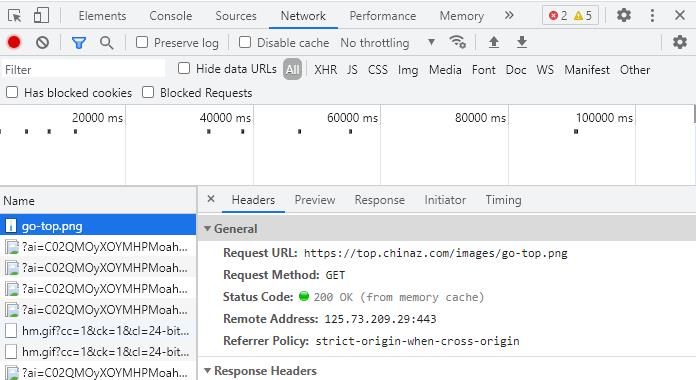
3.节点(标签)查找方法与遍历方法
查找方法:find
四、网络爬虫程序设计(60 分)
爬虫程序主体要包括以下各部分,要附源代码及较详细注释,并在每部分程序后面提供输出结果的截图。
1.数据爬取与采集
1 #导入库 2 import requests 3 from lxml import etree 4 import pandas as pd 5 6 #初始列表 7 sitename_oyr,websites_oyr, Alexa_oyr, Antichain_oyr = [], [], [], [] 8 for a in range(15): 9 10 #爬取网站的网址并且循环爬取前15页的内容 11 url = "https://top.chinaz.com/hangye/index_shenghuo_fenlei_{}.html".format(a*15) 12 13 #设置请求头 14 headers = { 15 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.106 Safari/537.36" 16 } 17 18 #requests请求链接 19 rq = requests.get(url,headers=headers).text 20 21 #使用lxml模块中的etree方法讲字符串转化为html标签 22 html = etree.HTML(rq) 23 24 #用xpath定位标签位置 25 html = html.xpath("/html/body/div[4]/div[3]/div[2]/ul/li") 26 27 #获取要爬取内容的详情链接 28 for yr in html: 29 #爬取网站名称 30 sitename = yr.xpath("./div[2]/h3/a/text()")[0] 31 #爬取网址 32 websites = yr.xpath("./div[2]/h3/span/text()")[0] 33 #爬取Alexa周排名 34 Alexa = yr.xpath("./div[2]/div/p[1]/a/text()")[0] 35 #爬取反链数 36 Antichain = yr.xpath("./div[2]/div/p[4]/a/text()")[0] 37 38 #输出 39 print(sitename) 40 print(websites) 41 print(Alexa) 42 print(Antichain) 43 44 #将字段存入初始化的列表中 45 sitename_oyr.append(sitename) 46 websites_oyr.append(websites) 47 Alexa_oyr.append(Alexa) 48 Antichain_oyr.append(Antichain) 49 50 #pandas中的模块将数据存入 51 df = pd.DataFrame({ 52 "网站名称" : sitename_oyr, 53 "网址" : websites_oyr, 54 "Alexa周排名" : Alexa_oyr, 55 "反链数" : Antichain_oyr, 56 }) 57 58 #储存为csv文件 59 df.to_csv("paiming.csv" , encoding=\'utf_8_sig\', index=False)
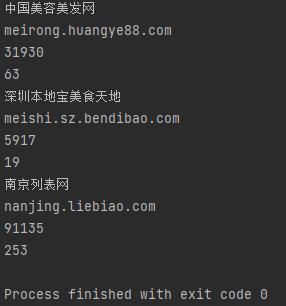
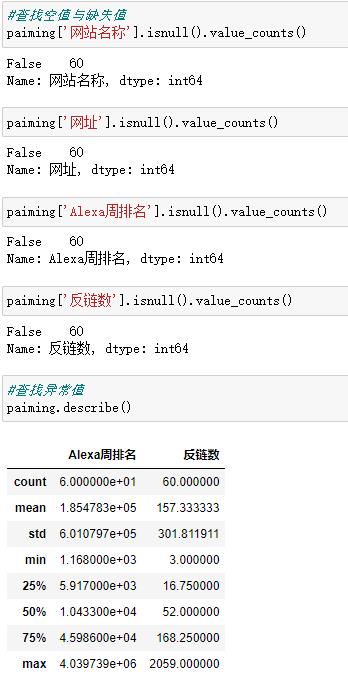
2.对数据进行清洗和处理
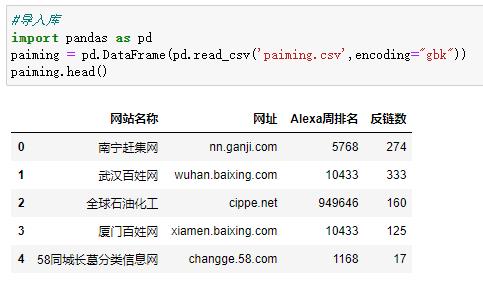
3.文本分析(可选):jieba 分词、wordcloud 的分词可视化
4.数据分析与可视化(例如:数据柱形图、直方图、散点图、盒图、分布图)
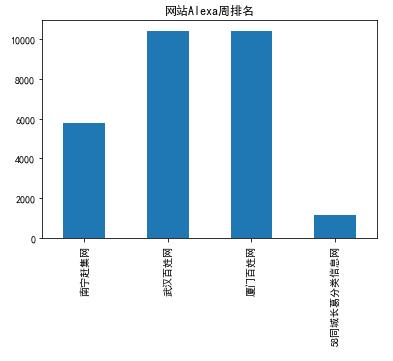
1 #直方图 2 import pandas as pd 3 import numpy as np 4 import matplotlib.pyplot as plt 5 plt.rcParams[\'font.family\'] = [\'SimHei\'] 6 s = pd.Series([5768,10433,10433,1168],[\'南宁赶集网\',\'武汉百姓网\',\'厦门百姓网\',\'58同城长葛分类信息网\']) 7 s.plot(kind = \'bar\',title = \'网站Alexa周排名\') 8 plt.show()
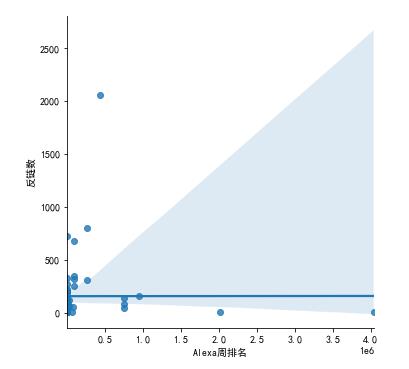
5.根据数据之间的关系,分析两个变量之间的相关系数,画出散点图,并建立变
量之间的回归方程(一元或多元)。
1 #散点图 2 sns.lmplot(x=\'Alexa周排名\',y=\'反链数\',data=paiming)
1 #回归方程 2 import pandas as pd 3 import numpy as np 4 import matplotlib.pyplot as plt 5 from scipy.optimize import leastsq 6 X=paiming.loc[:,\'反链数\'] 7 Y=paiming.loc[:,\'Alexa周排名\'] 8 def func(params,x): 9 a,b,c=params 10 return a*x*x+b*x+c 11 def error_func(params,x,y): 12 return func(params,x)-y 13 P0=[1,9.0] 14 def main(): 15 plt.figure(figsize=(8,6)) 16 P0=[1,9.0,1] 17 Para=leastsq(error_func,P0,args=(X,Y)) 18 a,b,c=Para[0] 19 print("a=",a, "b=",b, "c=",c) 20 plt.scatter(X,Y,color="green",label="样本数据",linewidth=2) 21 x=np.linspace(1,2500,10) 22 y=a*x*x+b*x+c 23 plt.plot(x,y,color="red",label="拟合曲线",linewidth=2) 24 plt.xlabel(\'反链数\') 25 plt.ylabel(\'Alexa周排名\') 26 plt.title("Alexa周排名与反链数回归方程") 27 plt.grid() 28 plt.legend() 29 plt.show() 30 main()
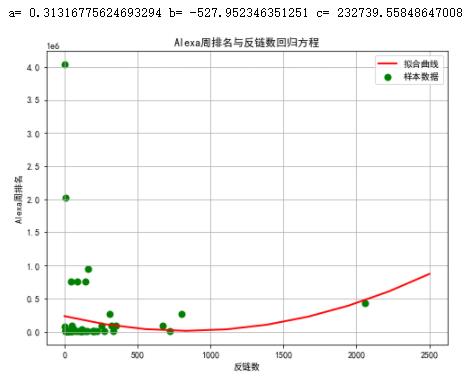
6.数据持久化
1 #储存为csv文件 2 df.to_csv("paiming.csv" , encoding=\'utf_8_sig\', index=False)
7.将以上各部分的代码汇总,附上完整程序代码
1 #导入库 2 import requests 3 from lxml import etree 4 import pandas as pd 5 6 #初始列表 7 sitename_oyr,websites_oyr, Alexa_oyr, Antichain_oyr = [], [], [], [] 8 for a in range(15): 9 10 #爬取网站的网址并且循环爬取前15页的内容 11 url = "https://top.chinaz.com/hangye/index_shenghuo_fenlei_{}.html".format(a*15) 12 13 #设置请求头 14 headers = { 15 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.106 Safari/537.36" 16 } 17 18 #requests请求链接 19 rq = requests.get(url,headers=headers).text 20 21 #使用lxml模块中的etree方法讲字符串转化为html标签 22 html = etree.HTML(rq) 23 24 #用xpath定位标签位置 25 html = html.xpath("/html/body/div[4]/div[3]/div[2]/ul/li") 26 27 #获取要爬取内容的详情链接 28 for yr in html: 29 #爬取网站名称 30 sitename = yr.xpath("./div[2]/h3/a/text()")[0] 31 #爬取网址 32 websites = yr.xpath("./div[2]/h3/span/text()")[0] 33 #爬取Alexa周排名 34 Alexa = yr.xpath("./div[2]/div/p[1]/a/text()")[0] 35 #爬取反链数 36 Antichain = yr.xpath("./div[2]/div/p[4]/a/text()")[0] 37 38 #输出 39 print(sitename) 40 print(websites) 41 print(Alexa) 42 print(Antichain) 43 44 #将字段存入初始化的列表中 45 sitename_oyr.append(sitename) 46 websites_oyr.append(websites) 47 Alexa_oyr.append(Alexa) 48 Antichain_oyr.append(Antichain) 49 50 #pandas中的模块将数据存入 51 df = pd.DataFrame({ 52 "网站名称" : sitename_oyr, 53 "网址" : websites_oyr, 54 "Alexa周排名" : Alexa_oyr, 55 "反链数" : Antichain_oyr, 56 }) 57 58 #储存为csv文件 59 df.to_csv("paiming.csv" , encoding=\'utf_8_sig\', index=False) 60 61 62 63 64 65 #导入库 66 import pandas as pd 67 paiming = pd.DataFrame(pd.read_csv(\'paiming.csv\',encoding="gbk")) 68 paiming.head() 69 70 #查找重复值 71 paiming.duplicated() 72 73 #查找空值与缺失值 74 paiming[\'网站名称\'].isnull().value_counts() 75 76 paiming[\'网址\'].isnull().value_counts() 77 78 paiming[\'Alexa周排名\'].isnull().value_counts() 79 80 paiming[\'反链数\'].isnull().value_counts() 81 82 #查找异常值 83 paiming.describe() 84 85 #直方图 86 import pandas as pd 87 import numpy as np 88 import matplotlib.pyplot as plt 89 plt.rcParams[\'font.family\'] = [\'SimHei\'] 90 s = pd.Series([5768,10433,10433,1168],[\'南宁赶集网\',\'武汉百姓网\',\'厦门百姓网\',\'58同城长葛分类信息网\']) 91 s.plot(kind = \'bar\',title = \'网站Alexa周排名\') 92 plt.show() 93 94 #散点图 95 sns.lmplot(x=\'Alexa周排名\',y=\'反链数\',data=paiming) 96 97 #回归方程 98 #回归方程 99 import pandas as pd 100 import numpy as np 101 import matplotlib.pyplot as plt 102 from scipy.optimize import leastsq 103 X=paiming.loc[:,\'反链数\'] 104 Y=paiming.loc[:,\'Alexa周排名\'] 105 def func(params,x): 106 a,b,c=params 107 return a*x*x+b*x+c 108 def error_func(params,x,y): 109 return func(params,x)-y 110 P0=[1,9.0] 111 def main(): 112 plt.figure(figsize=(8,6)) 113 P0=[1,9.0,1] 114 Para=leastsq(error_func,P0,args=(X,Y)) 115 a,b,c=Para[0] 116 print("a=",a, "b=",b, "c=",c) 117 plt.scatter(X,Y,color="green",label="样本数据",linewidth=2) 118 x=np.linspace(1,2500,10) 119 y=a*x*x+b*x+c 120 plt.plot(x,y,color="red",label="拟合曲线",linewidth=2) 121 plt.xlabel(\'反链数\') 122 plt.ylabel(\'Alexa周排名\') 123 plt.title("Alexa周排名与反链数回归方程") 124 plt.grid() 125 plt.legend() 126 plt.show() 127 main()
五、总结(10 分)
1.经过对主题数据的分析与可视化,可以得到哪些结论?是否达到预期的目标?
通过将爬取到的各个网站的Alexa周排名还有反链数,加以分析与可视化后由此可知:
通常情况下反链数越大,Alexa周排名越高,反链数越小,Alexa周排名越不确切。
2.在完成此设计过程中,得到哪些收获?以及要改进的建议?
本次网络爬虫课程设计的各个部分都已完成,先是用requests库获取到目标网页的内容;再将所爬取的目标数据存储到本地的csv文件,实现数据的持久化,可为未来使用和研究减少代码量的修改;再将完整的数据进行清洗,最后通过库对研究对象绘图分析。从一个大框架再不断细分完成每一部分的内容,使自己在实践时有了更明确的思路,本次完成课程设计更是一种对自我的肯定。虽然有一些没有完全实现出来,还存在在一些问题,但是发现了问题也就能及时查缺补漏,让我对Python这门语言有了更深的理解,推动自己更好地进步。
以上是关于Python网络爬虫课程设计的主要内容,如果未能解决你的问题,请参考以下文章