Python课程设计大作业:利用爬虫获取NBA比赛数据并进行机器学习预测NBA比赛结果
Posted 洲的学习笔记
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python课程设计大作业:利用爬虫获取NBA比赛数据并进行机器学习预测NBA比赛结果相关的知识,希望对你有一定的参考价值。
前言
该篇是之前遗漏的大三上的Python课程设计。刚好今天有空就补发了一篇文章。全部的代码在最后附录中。爬虫类的代码直接全部放到一起了,读者可以自行研究。
百度网盘链接链接:https://pan.baidu.com/s/1sQPMbO-sy2_QqQHyMtTmUg 提取码:mx10
一、课程设计项目说明
该课程设计项目“利用爬虫获取NBA数据信息并进行机器学习预测NBA比赛结果”的原型是基于网上一个教程网站“实验楼”中的项目“使用 Python 进行 NBA 比赛数据分析”。原项目是利用Python进行对NBA的数据机器学习进行预测。在原项目之上,我对项目做出了如下更新:
1、使用Python爬虫爬取NBA官网中的每一年的季后赛常规赛等部分项目中需要的比赛统计数据并输出成csv格式的文件,避免像原项目一样,全部比赛数据需要自己从NBA网站中复制黏贴到txt文本上然后更改后缀名为csv得到数据,能够减轻获取数据的繁琐工作量。
(注:原项目网站链接:https://www.lanqiao.cn/courses/782/learning/?id=2647)
2、对原项目代码结合了网上资料进行自主学习,并对原项目代码进行了改进优化。
二、课程设计项目功能
首先可通过Python爬虫获取来自NBA官网的任意年度的球队数据,保存在本地文件夹后,更改名为“NBA-nwz”的代码中的路径folder为数据文件路径,即可导入球队各类数据而后进行特征向量、逻辑回归、球队的EloScore计算等机器学习,最终将预测的比赛结果输出到特定路径下的格式为.csv的文件查看比赛预测结果。
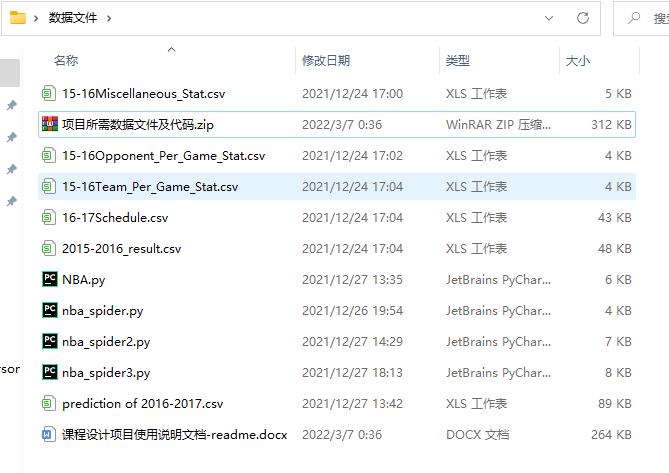
三、项目所需数据文件
本项目中一共需要5张数据表,分别是Team Per Ganme Stats(各球队每场比赛数据统计)、Opponent Per Game Stats(对手平均平常比赛的数据统计)、Miscellaneous Stats(各球队综合统计数据表)、2015-2016 NBA Schedule and Results(2015-16赛季比赛安排与结果)、2016-2017 NBA Schedule and Results(2016-2015赛季比赛安排)。
四、项目原理介绍
1、比赛数据介绍
本项目中,采用来自与NBA网站的数据。在该网站中,可以获取到任意球队、任意球员的各类比赛统计数据,如得分、投篮次数、犯规次数等等。
(注:NBA网站链接https://www.basketball-reference.com/)
在本网站中,主要使用2015-16赛季中的数据,分别是:
Team Per Ganme Stats表格:每支队伍平均每场比赛的表现统计;
Opponent Per Game Stats表格:所遇到的对手平均每场比赛的统计信息,所包含的统计数据与 Team Per Game Stats 中的一致,只是代表的是该球队对应的对手的统计信息;
Miscellaneous Stats:综合统计数据。(在网站中名为Advanced Stats。)
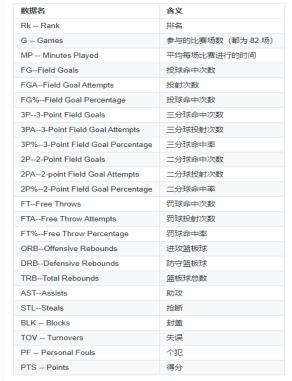
Team Per Game Stats表格、Opponent Per Game Stats表格、Miscellaneous Stats表格(在NBA网站中叫做“Advanced Stats”)中的数据字段含义如下图所示。
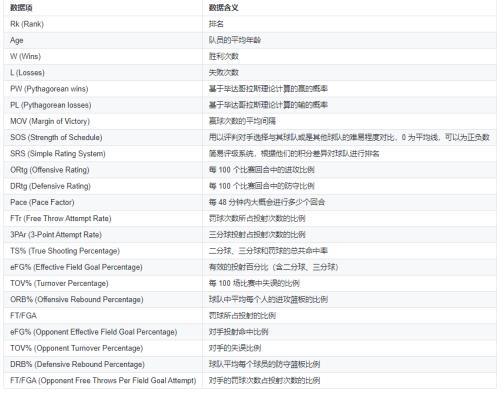
除了上述的三张表外,还需要另外两张表数据,分别是:
2015-2016 NBA Schedule and Results:2015-2016 年的 NBA 常规赛及季后赛的每场比赛的比赛数据;2016-2017 NBA Schedule and Results 中 2016-2017 年的 NBA 的常规赛比赛安排数据。
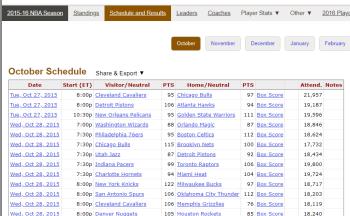
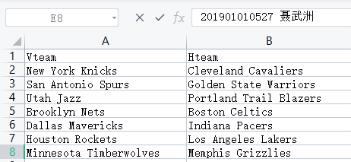
在获取到数据之后,需要对表格的字段做出更改如下图所示。
表格数据字段含义说明:Vteam: 客场作战队伍。Hteam: 主场作战队伍
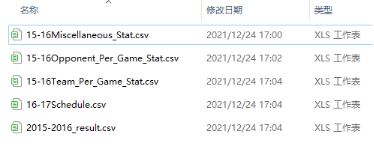
故综上所述一共需要5张NBA数据表。如下图所示。
2、数据分析原理
在获取到五个表格数据之后,将利用每支队伍过去的比赛情况和 Elo 等级分来分析每支比赛队伍的胜利概率。
分析与评价每支队伍过去的比赛表现时,将使用到上述五张表中的三张表,分别是 Team Per Game Stats、Opponent Per Game Stats 和 Miscellaneous Stats(后文中将简称为 T、O 和 M 表)。
这三个表格的数据,作为代表比赛中某支队伍的比赛特征。代码将实现针对每场比赛,预测哪支队伍最终获胜,但这并不是给出绝对的胜败情况,而是预判胜利的队伍有多大的获胜概率。
因此将建立一个代表比赛的特征向量。由两支队伍的以往比赛统计情况(T、O 和M表)和两个队伍各自的 Elo 等级分构成。
3、Elo Score等级分制度
Elo 机制现在广泛运用于网络游戏或竞技类运动中,根据Elo等级分制度对各个选手(玩家)进行登记划分。如王者荣耀、篮球、足球比赛等等。Elo Score等级分制度本身是国际象棋中基于统计学的一个评估棋手水平能力的方法。
通过Elo制度来计算选手(玩家)的胜率期望值的原理过程如下:
假设A与B当前的等级制度分为与,那么A对B的胜率期望值为:
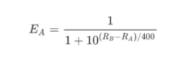
B对A的胜率期望值为:
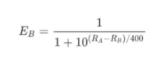
如果A在比赛中真实得分与他的胜率期望值不同,那么A的等级分要根据以下公式进行调整:
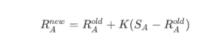
另外在国际象棋中,根据等级分的不同 K 值也会做相应的调整:大于等于2400,K=16,2100-2400 分,K=24,小于等于2100,K=32。
在项目中,将会用以表示某场比赛数据的特征向量为:
[A队 Elo score,A队的 T,O和M 表统计数据,B队 Elo score, B队的 T,O和M 表统计数据]。
4、机器学习
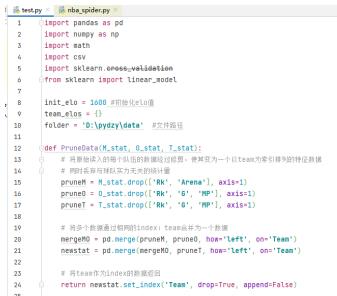
对于全部队伍,在最开始没有Elo分数时,赋予初始值init_elo=1600。然后根据数据计算每支球队Elo等级分。代码如下图所示:

而后根据数据表中的数据,及每支队伍的Elo计算结果,建立对应的2015-2016年常规赛和季后赛中每场比赛的数据集。因为NBA中有主客场制度,所以在比赛时,认为主场作战的队伍更加有优势,因此会在代码中加上100的等级分。

而后在main函数调用上述函数方法,且使用sklearn的Logistic Regression方法建立回归模型。
Logistic Regression(逻辑回归)方法:
逻辑回归:一种用于解决二分类(0 or 1)问题的机器学习方法,用于估计某种事物的可能性。比如某用户购买某商品的可能性等。简单的来说,就是学习我们设计好的向量数据,从中得到一个概率模型,然后输入其他数据,就能根据训练出来的模型得到其结果。
接着使用通过10折交叉验证计算训练正确率。
10折交叉验证(10-fold cross validation):
常用的测试方法。将数据集分成十分,轮流将其中9份作为训练数据,1份作为测试数据,进行试验。每次试验都会得出相应的正确率(或差错率)。10次的结果的正确率(或差错率)的平均值作为对算法精度的估计,一般还需要进行多次10折交叉验证(例如10次10折交叉验证),再求其均值,作为对算法准确性的估计。
最后使用训练好的模型在2016-2017年的常规赛数据中进行预测。导入16-17数据,就可以利用模型对一场新的比赛进行胜负的判断,并且返回胜率的概率。
五、项目实施
在原网站的教程中,需要将网页的数据复制下来到txt文本上然后更改后缀名为.csv格式,比较繁琐。
在课程设计中,我更新为以爬虫获取数据,这里以爬取Team Per Game表代码为例,更改爬虫代码中的url代码部分,运行即可爬取对应赛季的Team Per Ganme Stats(各球队每场比赛数据统计)、Opponent Per Game Stats(对手平均平常比赛的数据统计)表格。而后将会自动将爬取的表格输出为.csv文件在爬虫代码的同路径下。
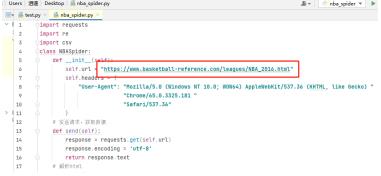
在“NBA-nwz.py”代码中,设置好全部数据文件的folder路径。如下图所示。(图片中的py文件名为test.py)然后运行代码,即可获得预测结果导出了。
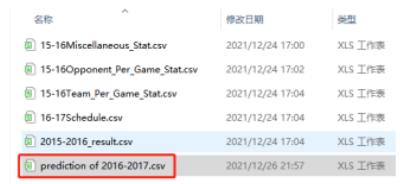
在导出的文件prediction of 2016-2017中可以看到如下预测数据。
六、项目总结
1、实验过程问题总结
在写代码的时候,有一个包一直下载不了,各种报错,根据网上的方法找了一个小时左右,试了很多种方法才解决掉。在这里记录一下。起因就是这个parsel包import不了,一直会报同一个错误: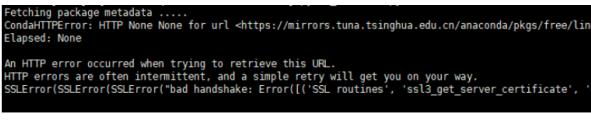
CondaHTTPError:HTTP 000 CONNECTION FAILED for url
https://mirrors.tuna.tsinghua.edu.cn/anaconda/.
应该是最开始自己安装python环境的时候使用的anaconda没有配置好,或者说这个源不起作用了,于是首先尝试了第一种方法找到.condarc文件,更改里面的channels通道地址。但是当我根据网上的指导教程换国科大、阿里等信号源后依然出现错误。
后面找到了一篇文章,说是需要将https://改为 http即可,刚看到的时候以为不是这个问题,后面实在是没办法了,被这个问题搞得头大,一个多小时了卡着,只好死马当活马医,更改了一下https为http,并配入了清华源的最新配置channels,没想到解决了!
可以通过cmd命令 conda info查看自己的channels路径配置。
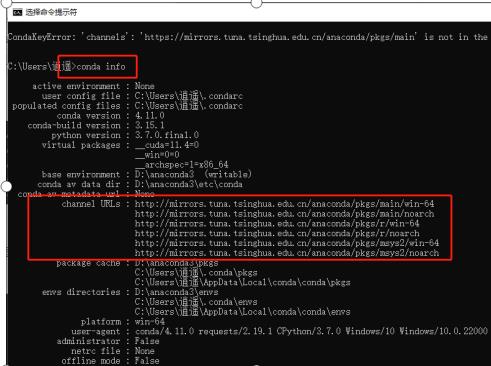
也可以通过在.condarc文件直接更改即可。进行如下配置即可轻松拥有速度较快的安装包速度了!
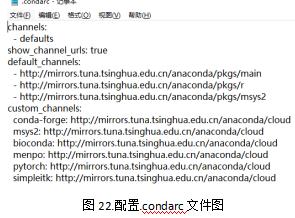
2、项目展望
总的来说,项目还是有一些小不足和继续优化的,例如在5张表中,爬下来就可以立即使用的只有三张表,分别是 Team Per Game Stats、Opponent Per Game Stats 和 Miscellaneous Stats。另外爬下来的表格需要进行字段处理,去掉不需要的字段,并且更改字段名等才能使用。而Python中是可以做到自动化处理数据字段的。这一点没有较好的实现。
除此之外,还可以使用Python可视化来做到更好的展示出比赛中两个队哪个胜率更高,
这一点我曾尝试过,但是由于效果并不是很完美,就没有放到设计项目中来。
以及在10折交叉验证中,可以看出正确率接近70%左右,感觉还可以在机器学习及数据处理(选用数据)方面再下一些功夫,达到更高的正确率。
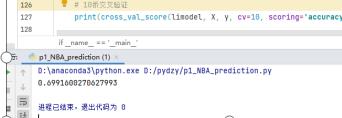
因为机器学习是我自己课余时间学习过一点点的小教程,所以了解接触并不是很深,做的并不是特别完善,有机会可以多更改,进一步完善优化。
附录:全部代码
进行预测的代码:
import pandas as pd
import math
import numpy as np
import csv
from sklearn import linear_model
from sklearn.model_selection import cross_val_score
init_elo = 1600 # 初始化elo值
team_elos =
folder = 'D:\\pydzy\\py-n' # 文件路径
def PruneData(M_stat, O_stat, T_stat):
#这个函数要完成的任务在于将原始读入的诸多队伍的数据经过修剪,使其变为一个以team为索引的排列的特征数据
#丢弃与球队实力无关的统计量
pruneM = M_stat.drop(['Rk', 'Arena'],axis = 1)
pruneO = O_stat.drop(['Rk','G','MP'],axis = 1)
pruneT = T_stat.drop(['Rk','G','MP'],axis = 1)
#将多个数据通过相同的index:team合并为一个数据
mergeMO = pd.merge(pruneM, pruneO, how = 'left', on = 'Team')
newstat = pd.merge(mergeMO, pruneT, how = 'left', on = 'Team')
#将team作为index的数据返回
return newstat.set_index('Team', drop = True, append = False)
def GetElo(team):
# 初始化每个球队的elo等级分
try:
return team_elos[team]
except:
team_elos[team] = init_elo
return team_elos[team]
def CalcElo(winteam, loseteam):
# winteam, loseteam的输入应为字符串
# 给出当前两个队伍的elo分数
R1 = GetElo(winteam)
R2 = GetElo(loseteam)
# 计算比赛后的等级分,参考elo计算公式
E1 = 1/(1 + math.pow(10,(R2 - R1)/400))
E2 = 1/(1 + math.pow(10,(R1 - R2)/400))
if R1>=2400:
K=16
elif R1<=2100:
K=32
else:
K=24
R1new = round(R1 + K*(1 - E1))
R2new = round(R2 + K*(0 - E2))
return R1new, R2new
def GenerateTrainData(stat, trainresult):
#将输入构造为[[team1特征,team2特征],...[]...]
X = []
y = []
for index, rows in trainresult.iterrows():
winteam = rows['WTeam']
loseteam = rows['LTeam']
#获取最初的elo或是每个队伍最初的elo值
winelo = GetElo(winteam)
loseelo = GetElo(loseteam)
# 给主场比赛的队伍加上100的elo值
if rows['WLoc'] == 'H':
winelo = winelo+100
else:
loseelo = loseelo+100
# 把elo当为评价每个队伍的第一个特征值
fea_win = [winelo]
fea_lose = [loseelo]
# 添加我们从basketball reference.com获得的每个队伍的统计信息
for key, value in stat.loc[winteam].iteritems():
fea_win.append(value)
for key, value in stat.loc[loseteam].iteritems():
fea_lose.append(value)
# 将两支队伍的特征值随机的分配在每场比赛数据的左右两侧
# 并将对应的0/1赋给y值
if np.random.random() > 0.5:
X.append(fea_win+fea_lose)
y.append(0)
else:
X.append(fea_lose+fea_win)
y.append(1)
# 更新team elo分数
win_new_score, lose_new_score = CalcElo(winteam, loseteam)
team_elos[winteam] = win_new_score
team_elos[loseteam] = lose_new_score
# nan_to_num(x)是使用0代替数组x中的nan元素,使用有限的数字代替inf元素
return np.nan_to_num(X),y
def GeneratePredictData(stat,info):
X=[]
#遍历所有的待预测数据,将数据变换为特征形式
for index, rows in stat.iterrows():
#首先将elo作为第一个特征
team1 = rows['Vteam']
team2 = rows['Hteam']
elo_team1 = GetElo(team1)
elo_team2 = GetElo(team2)
fea1 = [elo_team1]
fea2 = [elo_team2+100]
#球队统计信息作为剩余特征
for key, value in info.loc[team1].iteritems():
fea1.append(value)
for key, value in info.loc[team2].iteritems():
fea2.append(value)
#两队特征拼接
X.append(fea1 + fea2)
#nan_to_num的作用:1将列表变换为array,2.去除X中的非数字,保证训练器读入不出问题
return np.nan_to_num(X)
if __name__ == '__main__':
# 设置导入数据表格文件的地址并读入数据
M_stat = pd.read_csv(folder + '/15-16Miscellaneous_Stat.csv')
O_stat = pd.read_csv(folder + '/15-16Opponent_Per_Game_Stat.csv')
T_stat = pd.read_csv(folder + '/15-16Team_Per_Game_Stat.csv')
team_result = pd.read_csv(folder + '/2015-2016_result.csv')
teamstat = PruneData(M_stat, O_stat, T_stat)
X,y = GenerateTrainData(teamstat, team_result)
# 训练网格模型
limodel = linear_model.LogisticRegression()
limodel.fit(X,y)
# 10折交叉验证
print(cross_val_score(model, X, y, cv=10, scoring='accuracy', n_jobs=-1).mean())
# 预测
pre_data = pd.read_csv(folder + '/16-17Schedule.csv')
pre_X = GeneratePredictData(pre_data, teamstat)
pre_y = limodel.predict_proba(pre_X)
predictlist = []
for index, rows in pre_data.iterrows():
reslt = [rows['Vteam'], pre_y[index][0], rows['Hteam'], pre_y[index][1]]
predictlist.append(reslt)
# 将预测结果输出保存为csv文件
with open(folder+'/prediction of 2016-2017.csv', 'w',newline='') as f:
writers = csv.writer(f)
writers.writerow(['Visit Team', 'corresponding probability of winning', 'Home Team', 'corresponding probability of winning'])
writers.writerows(predictlist)
爬虫代码:
import requests
import re
import csv
from parsel import Selector
class NBASpider:
def __init__(self):
self.url = "https://www.basketball-reference.com/leagues/NBA_2021.html"
self.schedule_url = "https://www.basketball-reference.com/leagues/NBA_2016_games-.html"
self.advanced_team_url = "https://www.basketball-reference.com/leagues/NBA_2016.html"
self.headers =
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 "
"Safari/537.36"
# 发送请求,获取数据
def send(self, url):
response = requests.get(url, headers=self.headers, timeout=30)
response.encoding = 'utf-8'
return response.text
# 解析html
def parse(self, html):
team_heads, team_datas = self.get_team_info(html)
opponent_heads, opponent_datas = self.get_opponent_info(html)
return team_heads, team_datas, opponent_heads, opponent_datas
def get_team_info(self, html):
"""
通过正则从获取到的html页面数据中team表的表头和各行数据
:param html 爬取到的页面数据
:return: team_heads表头
team_datas 列表内容
"""
# 1. 正则匹配数据所在的table
team_table = re.search('<table.*?id="per_game-team".*?>(.*?)</table>', html, re.S).group(1)
# 2. 正则从table中匹配出表头
team_head = re.search('<thead>(.*?)</thead>', team_table, re.S).group(1)
team_heads = re.findall('<th.*?>(.*?)</th>', team_head, re.S)
# 3. 正则从table中匹配出表的各行数据
team_datas = self.get_datas(team_table)
return team_heads, team_datas
# 解析opponent数据
def get_opponent_info(self, html):
"""
通过正则从获取到的html页面数据中opponent表的表头和各行数据
:param html 爬取到的页面数据
:return:
"""
# 1. 正则匹配数据所在的table
opponent_table = re.search('<table.*?id="per_game-opponent".*?>(.*?)</table>', html, re.S).group(1)
# 2. 正则从table中匹配出表头
opponent_head = re.search('<thead>(.*?)</thead>', opponent_table, re.S).group(1)
opponent_heads = re.findall('<th.*?>(.*?)</th>', opponent_head, re.S)
# 3. 正则从table中匹配出表的各行数据
opponent_datas = self.get_datas(opponent_table)
return opponent_heads, opponent_datas
# 获取表格body数据
def get_datas(self, table_html):
"""
从tboday数据中解析出实际数据(去掉页面标签)
:param table_html 解析出来的table数据
:return:
"""
tboday = re.search('<tbody>(.*?)</tbody>', table_html, re.S).group(1)
contents = re.findall('<tr.*?>(.*?)</tr>', tboday, re.S)
for oc in contents:
rk = re.findall('<th.*?>(.*?)</th>', oc)
datas = re.findall('<td.*?>(.*?)</td>', oc, re.S)
datas[0] = re.search('<a.*?>(.*?)</a>', datas[0]).group(1)
datas.insert(0, rk[0])
# yield 声明这个方法是一个生成器, 返回的值是datas
yield datas
def get_schedule_datas(self, table_html):
"""
从tboday数据中解析出实际数据(去掉页面标签)
:param table_html 解析出来的table数据
:return:
"""
tboday = re.search('<tbody>(.*?)</tbody>', table_html, re.S).group(1)
contents = re.findall('<tr.*?>(.*?)</tr>', tboday, re.S)
for oc in contents:
rk = re.findall('<th.*?><a.*?>(.*?)</a></th>', oc)
datas = re.findall('<td.*?>(.*?)</td>', oc, re.S)
if datas and len(datas) > 0:
datas[1] = re.search('<a.*?>(.*?)</a>', datas[1]).group(1)
datas[3] = re.search('<a.*?>(.*?)</a>', datas[3]).group(1)
datas[5] = re.search('<a.*?>(.*?)</a>', datas[5]).group(1)
datas.insert(0, rk[0])
# yield 声明这个方法是一个生成器, 返回的值是datas
yield datas
def get_advanced_team_datas(self, table):
trs = table.xpath('./tbody/tr')
for tr in trs:
rk = tr.xpath('./th/text()').get()
datas = tr.xpath('./td[@data-stat!="DUMMY"]/text()').getall()
datas[0] = tr.xpath('./td/a/text()').get()
datas.insert(0, rk)
yield datas
def parse_schedule_info(self, html):
"""
通过正则从获取到的html页面数据中的表头和各行数据
:param html 爬取到的页面数据
:return: heads表头
datas 列表内容
"""
# 1. 正则匹配数据所在的table
table = re.search('<table.*?id="schedule" data-cols-to-freeze=",1">(.*?)</table>', html, re.S).group(1)
table = table + "</tbody>"
# 2. 正则从table中匹配出表头
head = re.search('<thead>(.*?)</thead>', table, re.S).group(1)
hea以上是关于Python课程设计大作业:利用爬虫获取NBA比赛数据并进行机器学习预测NBA比赛结果的主要内容,如果未能解决你的问题,请参考以下文章