数据治理中的数据血缘关系是什么?用来解决什么问题
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据治理中的数据血缘关系是什么?用来解决什么问题相关的知识,希望对你有一定的参考价值。
前言:数据血缘属于数据治理中的一个概念,是在数据溯源的过程中找到相关数据之间的联系,它是一个逻辑概念。
数据治理里经常提到的一个词就是血缘分析,血缘分析是保证数据融合的一个手段,通过血缘分析实现数据融合处理的可追溯。大数据数据血缘是指数据产生的链路,直白点说,就是我们这个数据是怎么来的,经过了哪些过程和阶段。
数据血缘关系的应用场景是什么:
在数据的处理过程中,从数据源头到最终的数据生成,每个环节都可能会导致我们出现数据质量的问题。比如我们数据源本身数据质量不高,在后续的处理环节中如果没有进行数据质量的检测和处理,那么这个数据信息最终流转到我们的目标表,它的数据质量也是不高的。也有可能在某个环节的数据处理中,我们对数据进行了一些不恰当的处理,导致后续环节的数据质量变得糟糕。因此,对于数据的血缘关系,我们要确保每个环节都要注意数据质量的检测和处理,那么我们后续数据才会有优良的基因,即有很高的数据质量。
举例说明:
现在假设你是一只数据开发工程师,为了满足一次业务需求,,然后为了生成这张表,可能是处于程序逻辑清晰或者性能优化的考虑,你会使用很多份数据表,也会通过 MR、Spark 或者 Hive 来生产很多中间表。
如下图,是你将花费时间来实现的整个数据流。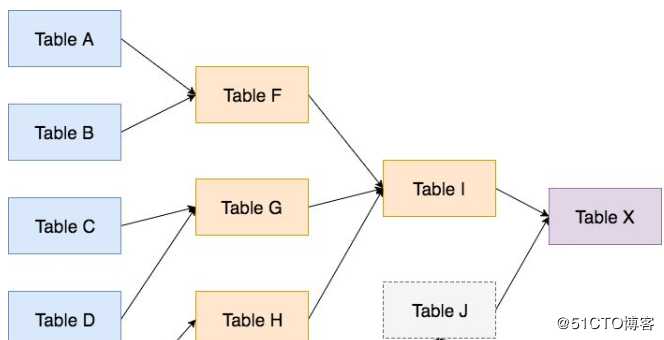
其中 Table X 是最终给到业务侧的表。
蓝色的 Table A-E,是原始数据。
黄色的 Table F-I 是你计算出来的中间表。这些表都是你自己写程序要处理的表。
然后你为了懒省事,嗯,应该说本着不重复开发的原则,你还要用到同事小伙伴处理的表,Table J 就是别人处理过的结果表。
过了一段时间后,业务侧的感觉你提供的数据中有个字段总是不太对劲,其实就是怀疑你的数据出问题!需要你来追踪一下这个字段的来源。
首先你从 Table X 中找到了异常的字段,然后定位到了它来源于 Table I,再从 Table I 定位到了它来源于 Table G, 再从 Table G 追溯到了 Table D,最终发现是某几天的来源数据有异常。
或者说,你从 Table X 定位到了异常的字段原来来自于其它小伙伴处理的表 Table J,然后继续向前回溯,找到了这张表在处理过程中的某一个步出现了问题。
我们如何将数据血缘关系进行可视化呢:
在NBI大数据可视化平台中我们可以通过桑基图方式来对数据关系链路来分析:
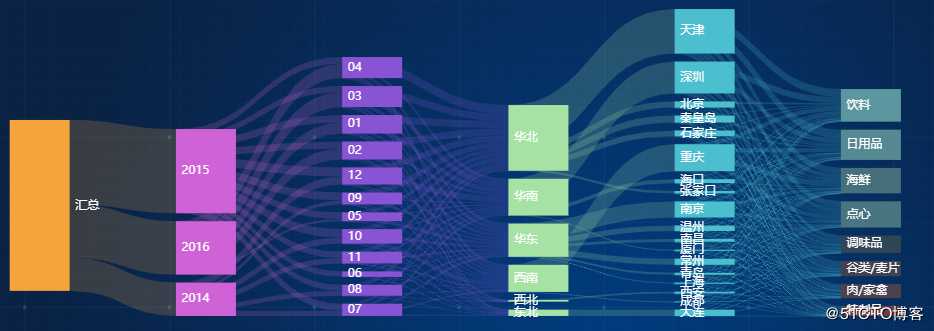
在NBI大数据可视化平台中只需通过拖拽组件和字段即可快速生成桑基图
(1)从组件库中拖入桑基图组件到编辑器中: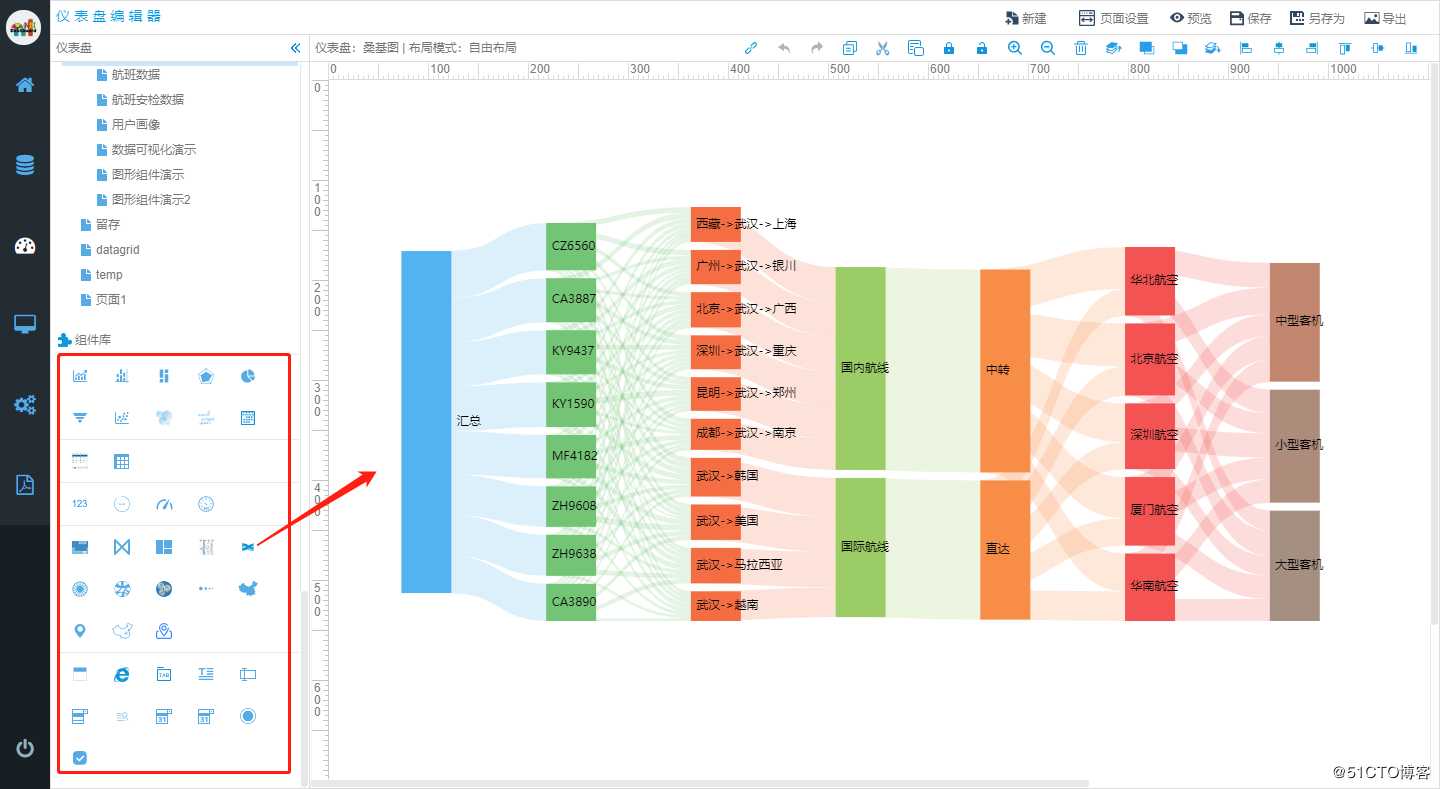
(2)组件右键,设置数据数据和样式,即可完成数据的呈现: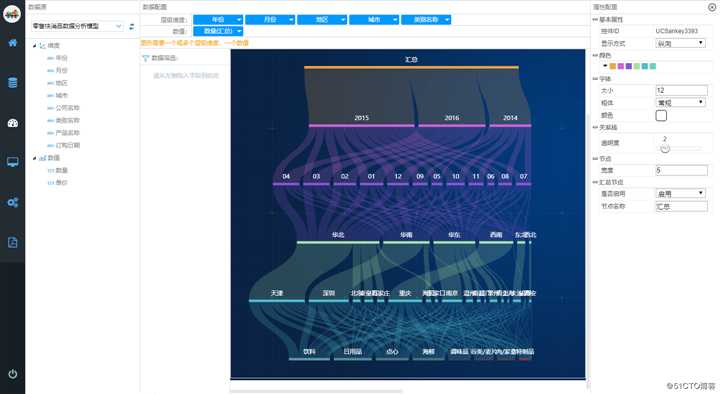
更多信息请参考(http://nbi.easydatavis.com:8033)

标签: 工具软件, 大数据, NBI大数据, BI, 可视化分析, 敏捷BI, 数据治理, 数据中台, 数据血缘管理, 数据仓库
以上是关于数据治理中的数据血缘关系是什么?用来解决什么问题的主要内容,如果未能解决你的问题,请参考以下文章