数据治理:元数据管理 数据血缘(补充学习)
Posted 浊酒南街
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据治理:元数据管理 数据血缘(补充学习)相关的知识,希望对你有一定的参考价值。
一、什么是元数据管理?
为什么企业对自身内部的数据资产总是混沌不清?其实是缺少一种有效的工具来进行数据资产的梳理和盘点。而元数据管理工具就是一种有有效的盘点工具或手段。
元数据是企业中用来描述数据的数据。它可理解为比一般意义的数据范畴更加广泛的数据,不再仅仅表示数据的类型、名称、值等信息,它可以进一步提供数据的上下文描述信息,比如数据的所属域、取值范围、数据间的关系、业务规则,甚至是数据的来源。在数据分析中,元数据可以帮助DW管理员和DW开发人员非常方便地找到他们所关心的数据。
元数据相当于企业数据的DNA,它可以告诉你,有用的数据在哪里,能提供一份数据结构定义和元素的详细示意图,数据来龙去脉、关系,使应用开发过程更有效,提供数据的参照性、引用性、血缘分析、影响分析、变化分析……
简单地说,元数据管理是为了对数据资产进行有效的组织。它使用元数据来帮助管理他们的数据。它还可以帮助数据专业人员收集、组织、访问和丰富元数据,以支持数据治理。
三十年前,数据资产可能是 Oracle 数据库中的一张表。然而,在现代企业中,我们拥有一系列令人眼花缭乱的不同类型的数据资产。可能是关系数据库或 NoSQL 存储中的表、实时流数据、 AI 系统中的功能、指标平台中的指标,数据可视化工具中的仪表板。
现代元数据管理应包含所有这些类型的数据资产,并使数据工作者能够更高效地使用这些资产完成工作。所以,元数据管理应具备的功能如下:
搜索和发现:数据表、字段、标签、使用信息
访问控制:访问控制组、用户、策略
数据血缘:管道执行、查询
合规性:数据隐私/合规性注释类型的分类
数据管理:数据源配置、摄取配置、保留配置、数据清除策略
AI 可解释性、再现性:特征定义、模型定义、训练运行执行、问题陈述
数据操作:管道执行、处理的数据分区、数据统计
数据质量:数据质量规则定义、规则执行结果、数据统计
元数据管理,记录数据仓库中模型的定义,各层级间的映射关系,监控数据仓库的数据状态及ETL的任务运行状态。一般会通过元数据资料库(Metadata Repository)来统一地存储和管理元数据,其主要目的是使数据仓库的设计、部署、操作和管理能达成协同和一致。淘宝的元数据架构:
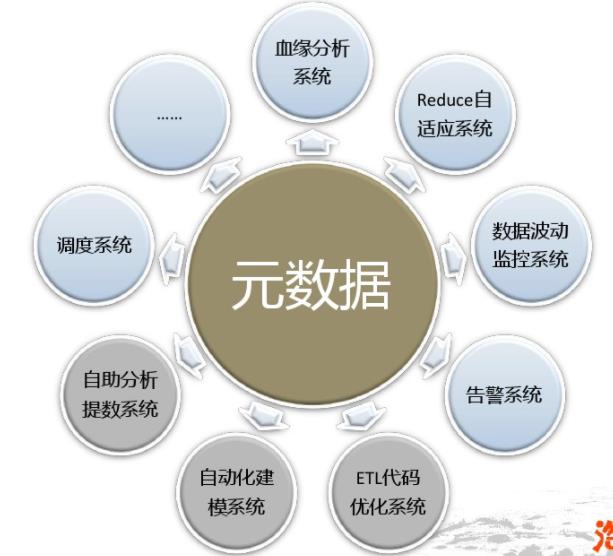
二、元数据管理价值:字段血缘分析的意义
通过元数据以企业全局视角对企业各业务域的数据资产进行盘点,实现企业数据资源的统一梳理和盘查,有助于发现分布在不同系统、位置或个人电脑的数据,让隐匿的数据显性化。数据地图包括了数据资源的基本信息,存储位置信息、数据结构信息、各数据之间关系信息,数据和人之间的关系信息,数据使用情况信息等,使数据资源信息详细、统一、透明,降低“找数据”的沟通成本,为数据的使用和大数据挖掘提供支撑。
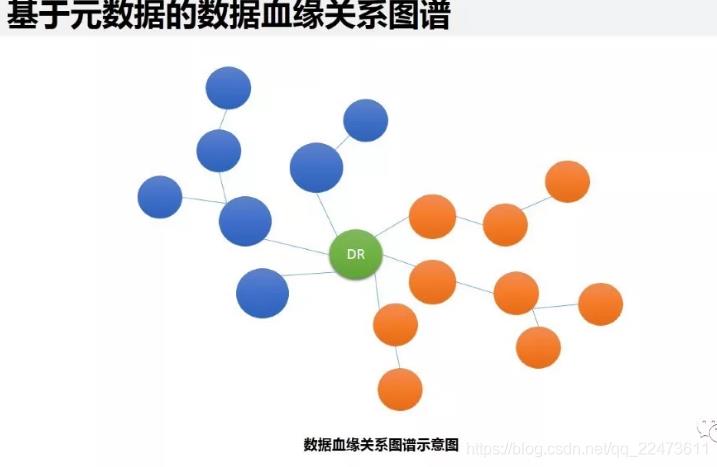
数仓经常会碰到的两类问题:
1、两个数据报表进行对比,结果差异很大,需要人工核对分析指标的维度信息,比如从头分析数据指标从哪里来,处理条件是什么,最后才能分析出问题原因 ——数据回溯问题
2、基础数据表因某种原因需要修改字段,需要评估其对数仓的影响,费时费力,然后在做方案 —— 影响分析问题
追根溯源,发现数据问题本质
企业在做数据分析的时候,数据分析结果不正确,原因可能是数据分析过程出现数据问题,也可能是数据源本身就有问题,还可能是数据在加工处理过程中出现了数据问题……。通过元数据血缘分析,能够快速定位数据来源和加工处理过程,能够帮助数据分析人员快速定位数据问题。另外,通过元数据血缘关系分析,可以理解不同数据指标间的关系,分析产生指标的数据源头波动情况带来的影响。
模型驱动,敏捷开发
基于元数据模型的数据应用规划、设计和开发是企业数据应用的一个高级阶段。当企业元数据管理达到一定水平(实现自动化管理的时候),企业中各类数据实体模型、数据关系模型、数据服务模型、数据应用模型的元数据统一在元数据平台进行管理,并自动更新数据间的关联关系。基于元数据、可扩展的MDA,才是快速满足企业数据应用个性化定制需求的最好解决方案。通过将大量的业务进行模型抽象,使用元数据进行业务描述,并通过相应的模型驱动引擎在运行时驱动,使用高度抽象的领域业务模型作为构件,完成代码转换,动态生成相关代码,降低开发成本,应对复杂需求变更。
这两类问题都属于数据血缘分析问题,数据血缘分析还有其它的积极意义,比如:
问题定位分析
类似于影响分析,当程序运行出错时,可以方便找到问题的节点,并判断出问题的原因以及后续的影响
指标波动分析
当某个指标出现较大的波动时,可进行溯源分析,判断是由哪条数据发生变化所导致的
数据体检
判定系统和数据的健康情况,是否存在大量的冗余数据、无效数据、无来源数据、重复计算、系统资源浪费等问题
数据评估
通过血缘分析和元数据,可以从数据的集中度、分布、冗余度、数据热度、重要性等多角度进行评估分析,从而初步判断数据的价值
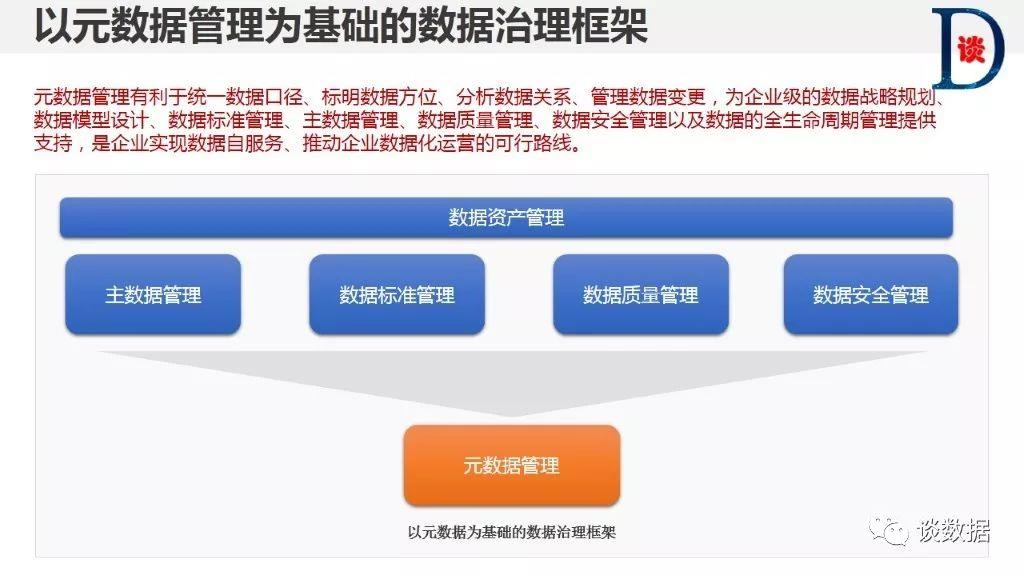
三、元数据分类:业务元数据、技术元数据和管理元数据。
技术元数据包括:英文字段,字段名称、字段长度、数据库表结构等。
业务元数据包括:中文意思,业务名称、业务定义、业务描述等。
技术元数据为开发和管理数据仓库的IT 人员使用,它描述了与数据仓库开发、管理和维护相关的数据,包括数据源信息、数据转换描述、数据仓库模型、数据清洗与更新规则、数据映射和访问权限等。
业务元数据为管理层和业务分析人员服务,从业务角度描述数据,包括商务术语、数据仓库中有什么数据、数据的位置和数据的可用性等,帮助业务人员更好地理解数据仓库中哪些数据是可用的以及如何使用。
1、业务元数据
业务元数据主要描述 ”数据”背后的业务含义;从业务角度描述业务领域的相关概念、关系——包括业务术语和业务规则。
业务人员更多关注的是与“客户”、“结算日期”、“销售金额”等相关的内容,这些内容很难从技术元数据中体现出来。
业务元数据使用业务名称、定义、描述等信息表示企业环境中的各种属性和概念,从一定程度上讲,所有数据背后的业务上下文都可以看成是业务元数据。
业务元数据能让用户更好地理解和使用企业环境中的数据,比如用户通过查看业务元数据就可以清晰地理解各指标的含义,指标的计算方法等信息。
业务元数据广泛存在于企业环境中,业务元数据的来源主要有:
ERP企业ERP系统中存储着大量的业务元数据,比如说财务计算公式、过程逻辑、业务规则等。
报表报表的表头也是一种业务元数据,特别是那些包含合计、平均数等带有总结性质的列,报表中的一些计算公式等。
表格与报表类似,EXCEL的表头和公式也是很重要的业务元数据。与报表不同的是,大多数表格中会有单独一列“描述”,有些表格中还会有一列代码和代码描述,这些都是很有用的业务元数据。
文件文件中到处都是业务元数据,比如标题、作者、修改时间等,文件内容中的业务元数据的获取相对比较困难,涉及到机器学习等技术。
BI工具BI中经常会用到的操作就是“钻取”操作,向上和向下钻取中通常定义了企业的各种分类结构,例如产品等级和组织结构等级等,这些都是很重要的业务元数据。
数据仓库数据仓库中也有业务元数据存在,比如说,构建数据仓库之前通常需要做大量调研来研究如何集成多个数据源,这些如数据仓库构建过程相关的文件中存在着大量的业务元数据。
下图是两个具体的例子:
某建筑公司的一张报表,我们可以看到,报表中包含了报表名称、填报时间、制表人和报表表头名称等,这些都是高价值的业务元数据;某公司新员工入职申请表,和报表类似,申请表名称、姓名、性别等申请表各栏名称都是业务元数据。
目前,大部分企业只关注到了技术元数据,忽略了对业务元数据的管理。技术元数据缺少业务含义,很难被技术人员之外的人所理解,比如可能用“rec_temp_fld_a”表示某个字段,用“236IN_TAB”表示数据库中的某张表,在不被理解的情况下很难给企业业务带来收益。业务元数据能代表数据背后的业务含义,企业在对技术元数据管理的同时需要注重业务元数据的管理。
主题定义:每段 ETL、表背后的归属业务主题。
业务描述:每段代码实现的具体业务逻辑。
标准指标:类似于 BI 中的语义层、数仓中的一致性事实;将分析中的指标进行规范化。
标准维度:同标准指标,对分析的各维度定义实现规范化、标准化。
业务元数据,在实际业务中,需要不断的进行维护且与业务方进行沟通确认。
2、技术元数据
指技术细节相关的概念、关系和规则,包括对数据结构、数据处理方面的描述。以及数据仓库、ETL、前端展现等技术细节的信息。
数据仓库中的技术元数据一般包含以下 4 大系统:数据源元数据;ETL 元数据;数据仓库元数据;BI 元数据。
数据源元数据
例如:数据源的 IP、端口、数据库类型;数据获取的方式;数据存储的结构;原数据各列的定义及 key 指对应的值。
ETL 元数据
根据 ETL 目的的不同,可以分为两类:数据清洗元数据;数据处理元数据。
数据清洗元数据
数据清洗,主要目的是为了解决掉脏数据及规范数据格式;
因此此处元数据主要为:各表各列的"正确"数据规则;默认数据类型的"正确"规则。
数据处理元数据
数据处理,例如常见的表输入表输出;非结构化数据结构化;特殊字段的拆分等。
源数据到数仓、数据集市层的各类规则。比如内容、清理、数据刷新规则。
数据仓库元数据
数据仓库结构的描述,包括仓库模式、视图、维、层次结构及数据集市的位置和内容;
业务系统、数据仓库和数据集市的体系结构和模式等。
BI 元数据
汇总用的算法、包括各类度量和维度定义算法。数据粒度、主题领域、聚集、汇总、预定义的查询与报告。
3、元数据管理
1.元数据自动采集、动态感知,版本差异标记
2.元数据血缘、影响、全链路关系自动探索,图形化展现

4、Hive元数据库介绍及信息查看
1、Hive中有两类数据:表数据和元数据。和关系型数据库一样,元数据可以看做是描述数据的数据,包括1.hive表的数据库名、表名、字段名称与类型、分区字段与类型 2.表及分区的属性、存放位置等
元数据存储路径和內表一样,分为本地和远程,可通过hive-site.xml文件设置
有关hive的配置都在hive-site.xml文件中。
属性 描述 默认值
hive.metastore.warehouse.dir 指定hive表在hdfs上的存储路径 /user/hive/warehouse
javax.jdo.option.ConnectionURL 配置元数据的连接URL
javax.jdo.option.ConnectionUserName 元数据库连接用户名
javax.jdo.option.ConnectionPassword 元数据库连接密码
比如如下的配置:
Local方式
<configuration>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive_remote/warehouse</value>
</property>
<property>
<name>hive.metastore.local</name>
<value>true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost/hive_remote?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>password</value>
</property>
</configuration>
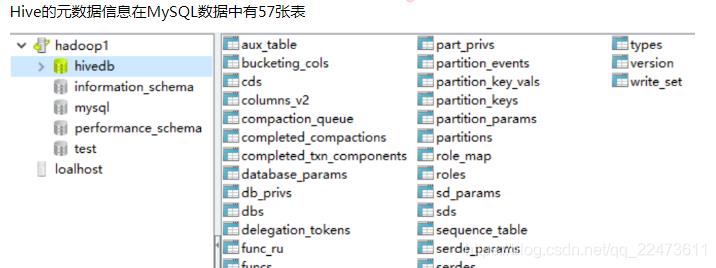
Hive 的元数据信息通常存储在关系型数据库中,常用MySQL数据库作为元数据库管理。
内嵌Derby方式
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:derby:;databaseName=metastore_db;create=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>org.apache.derby.jdbc.EmbeddedDriver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>APP</value>
<description>username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>mine</value>
<description>password to use against metastore database</description>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>file:///Users/micmiu/tmp/hive/warehouse</value>
<description>unit test data goes in here on your local filesystem</description>
</property>
元数据库中存在以下这些表:

5、表,字段信息管理
各种类型的数据库都会有各自的元数据信息,比如hive,我们可以通过show create table xxx,来查看一张表的建表语句
因此我们如果自己管理整条链路上的所有表的元数据,也可以通过类似的方式收集,关于如何保存这些元数据,可以参考hive的元数据库的做法!
Hive元数据信息对应MySQL数据库表:Hive学习之路 (三)Hive元数据信息对应MySQL数据库表 - 扎心了,老铁 - 博客园
举个例子,甚至可以记录每张表的count(定时count下,看表的膨胀率,可以是全量count也可以是新增分区的count,看日趋势)
可以根据不同的数据库不同的功能去新增一些字段记录更多的信息,比如greenplum中,每张表都会有distributed by(xxx),也需要记录,又比如mysql里表有引擎的,是InnoDB还是MyISAM等等,所以也是需要根据实际用的不同数据库去微调自己的元数据记录的方式
当有新建表的需求的时候,如果可以做出一个平台,直接在平台上建表,那么元数据就可以实时更新的,但是如果是直接连接数据库操作的话,就应该定时去show tables,然后查询所有表的建表信息,然后解析之后保存到正确的表中,并且如果有已存在的非临时表的信息查询出来和上次不一样的话,应该有适当的报警!
额外说几点:
1、表或者业务线的负责人
2、记录该表的生成规则!(比如该表存了活跃的人的行为,那么如何定义这个活跃的人,应该有适当的说明甚至有样例sql)
2、字段一定要有注释,甚至有时候字段的生成规则也需要记录!(因为有些字段涉及到了计算,为了验证数据或者口径统一,就需要计算的方法,给出样例sql,并且要标明中文含义,避免同一个字段,大家的叫法不同),当然也可以不在这里记录,在专门的指标库中记录也可以
3、记录下该表数据保存周期,比如存近一年,或者近6个月这样,让大家有个概念
4、修改相关信息造成的影响(通知或者告警):向下追溯元数据对象改变对下游的影响,是不是要发通知或者邮件给下游所有负责人
四、元数据管理平台架构
元数据管理平台从应用层面,可以分类:元数据采集服务,应用开发支持服务,元数据访问服务、元数据管理服务和元数据分析服务。

1、元数据采集服务
在数据治理项目中,通常涉及到的元数据还包括:数据源的元数据,数据加工处理过程的元数据,数据仓库或数据主题库的元数据,数据应用层的元数据,数据接口服务的元数据等等。元数据采集服务提供各类适配器满足以上各类元数据的采集,并将元数据整合处理后统一存储于中央元数据仓库,实现元数据的统一管理。这个过程中,数据采集适配器十分重要,元数据采集要能够适配各种DB、各类ETL、各类DW和Report产品,同时还需要适配各类结构化或半结构化数据源。目前市场上的主流元数据产品还没有哪一家能做到“万能适配”,都需要在实际应用过程中做或多或少的定制化开发。
2、元模型驱动的设计与开发
通过元数据管理平台实现对应用的逻辑模型、物理模型、UI模型等各类元模型管理,支撑应用的设计和开发。应用开发的元模型有三个状态,分别是:设计态的元数据模型,通常由ERWin、PowerDesigner的等设计工具产生。测试态的元数据模型,通常是关系型数据:Oracle、DB2、Mysql、Teradata等,或非关系型数据库:MongDB、HBase、Hive、Hadoop等。生产态的元模型,本质上与测试态元数据差异不大。通过元数据平台对应用开发三种状态的统一管理和对比分析,能够有效降低元数据变更带来的风险,为下游ODS、DW的数据应用提供支撑。另外,基于元数据的MDD(代码生成服务),可以通过模型(元数据)完成业务对象元数据到UI元数据的关联和转换,自动生成相关代码,表单界面,减少了开发人员的设计和编码量,提升应用和服务的开发效率。

3、元数据管理服务
市场上主流的元数据管理产品,基本都包括:元数据查询、元模型管理、元数据维护、元数据版本管理、元数据对比分析、元数据适配器、元数据同步管理、元数据生命周期管理等功能。此类功能,各家产品大同小异
4、元数据访问服务
元数据访问服务是元数据管理软件提供的元数据访问的接口服务,一般支持REST或Webservice等接口协议。通过元数据访问服务支持企业元数据的共享,是企业数据治理的基础。
5、元数据分析服务,即元数据管理的意义

1、血缘分析:是告诉你数据来自哪里,都经过了哪些加工。其价值在于当发现数据问题时可以通过数据的血缘关系,追根溯源,快速地定位到问题数据的来源和加工过程,减少数据问题排查分析的时间和难度。这个功能常用于数据分析发现数据问题时,快速定位和找到数据问题的原因。
血缘分析是一种技术手段,用于对数据处理过程的全面追踪,从而找到某个数据对象为起点的所有相关元数据对象以及这些元数据对象之间的关系。元数据对象之间的关系特指表示这些元数据对象的数据流输入输出关系。
在元数据管理系统成型后,我们便可以通过血缘分析来对数据仓库中的数据健康、数据分布、集中度、数据热度等进行分析。
2、影响分析:是告诉你数据都去了哪里,经过了哪些加工。其价值在于当发现数据问题时可以通过数据的关联关系,向下追踪,快速找到都哪些应用或数据库使用了这个数据,从而避免或降低数据问题带来的更大的影响。这个功能常用于数据源的元数据变更对下游ETL、ODS、DW等应用应用的影响分析。
在开发中,我们经常会遇到以下问题:如果我要改动某个表、ETL,会造成怎样的影响?
如果没有元数据,那我们可能需要遍历所有的脚本、数据。才能得到想要的答案;而如果有成熟的元数据管理,那我们就可以直接得到答案,节省大量时间。
3、冷热度分析:是告诉你哪些数据是企业常用数据,哪些数据属于“僵死数据”。其价值在于让数据活跃程度可视化,让企业中的业务人员、管理人员都能够清晰的看到数据的活跃程度,以便更好的驾驭数据,激活或处置“僵死数据”,从而为实现数据的自助式分析提供支撑。
4、关联度分析:是告诉你数据和其他数据的关系以及它们的关系是怎样建立的。关联度分析是从某一实体关联的其它实体和其参与的处理过程两个角度来查看具体数据的使用情况,形成一张实体和所参与处理过程的网络,从而进一步了解该实体的重要程度,如:表与ETL 程序、表与分析应用、表与其他表的关联情况等。本功能可以用来支撑需求变更的影响评估。
5、数据资产地图:是告诉你有哪些数据,在哪里可以找到这些数据,能用这些数据干什么。通过元数据可以对企业数据进行完整的梳理、采集和整合,从而形成企业完整的数据资产地图。数据资产地图支持以拓扑图的形式进行可视化展示各类元数据和数据处理过程,通过不同层次的图形展现粒度控制,满足业务上不同应用场景的数据查询和辅助分析需要。
6、ETL 自动化管理
在数仓中,很大一部分 ETL 都是枯燥重复的步骤。
例如源系统-ODS 层的:表输入——表输出。
又比如 ODS-DW:SQL 输入——数据清洗——数据处理——表输出。
以上的规则其实就属于一部分元数据。
那理论上完全可以实现,写好固定脚本,然后通过前端选择——或 api 接口。
进而对重复的 ETL 实现自动化管理,降低 ETL 开发的时间成本。
7、数据安全管理
在阿里推崇的数据中台中,一切数据接口指标,都会从数据仓库中出口。因此理论上,我们只需在此处的元数据中对管理元数据的权限进行配置,即可实现全公司的数据安全管理。
五、总结:
元数据是企业数据资源的应用字典和操作指南,元数据管理有利于统一数据口径、标明数据方位、分析数据关系、管理数据变更,为企业级的数据战略规划、数据模型设计、数据标准管理、主数据管理、数据质量管理、数据安全管理以及数据的全生命周期管理提供支持,是企业实现数据自服务、推动企业数据化运营的可行路线。企业以元数据为抓手进行数据治理,帮助企业更好地对数据资产进行管理,理清数据之间的关系,实现精准高效的分析和决策。
六、管理元数据:方案
亿信元数据管理系统(EsPowerMeta)
数仓的元数据管理 浅谈数仓的元数据管理 - 知乎
常见的元数据管理系统大数据平台-元数据管理系统解析_colorant的专栏-CSDN博客_元数据
开源的元数据管理系统方案:apache atlas:Atlas通过各种hook/bridge插件来采集几种数据源的元数据信息,通过一套自定义的Type 体系来定义元数据信息的格式,通过搜索引擎对元数据进行全文索引和条件检索,除了自带的UI控制台意外,Atlas还可以通过Rest API的形式对外提供服务、 Apache atlas使用说明(UI功能详解)_x_iaoa_o的博客-CSDN博客
Cloudera CDH发行版中主推的Navigator CDH5.14.2 的Navigator介绍与安装_flyfish的技术博客_51CTO博客
wherehows、
informatica
元数据管理其实就是解决,数据的哲学问题,我是谁,我从哪来,又要到哪去?
1、元数据管理:Atlas
Apache Atlas 是 Apache 基金会的孵化项目,是 Hadoop 生态圈的数据治理和元数据框架。Atlas 是一套核心基础治理服务的集合,有很好的伸缩性和可扩展性,能够满足企业对 Hadoop 生态系统的多样性需求,并能和企业的数据生态系统集成。
它为 Hadoop 集群提供了包括数据分类、集中策略引擎、数据血缘、安全和生命周期管理在内的元数据治理核心能力。
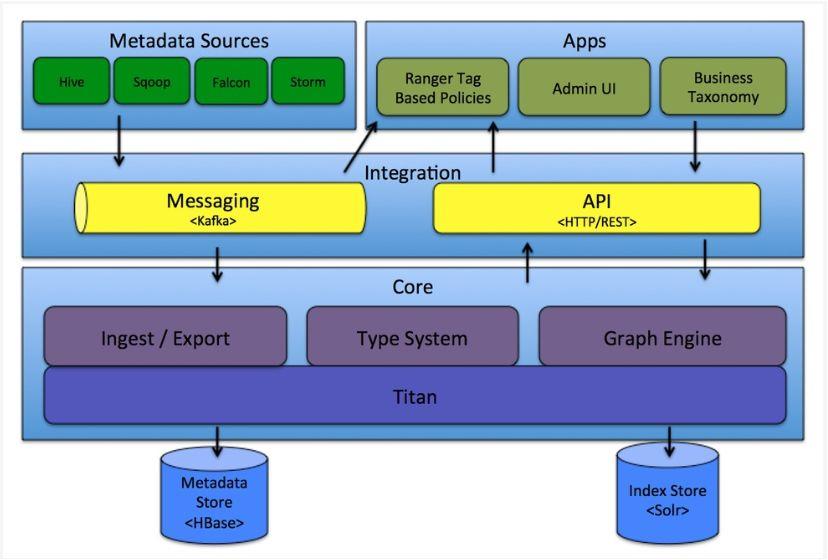
但 atlas 的缺点是:只能对 hadoop 的元数据进行管理(虽然也是连的 Mysql ),对传统数据库的支持力度非常小;同时血缘分析也只支持特定的数据库。
表的上下游依赖关系
4.2Hive的血缘追溯
在Atlas 创建以前的表是没有办法导入血缘关系内容的
用一个小表做一个演示
创建了一个小表,导入几条数据
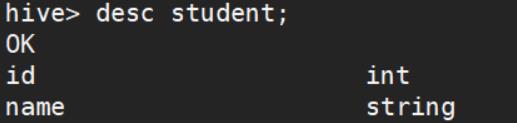
由student表 as 出stident1表

就能在这个表的lineage中看到这个表是怎么来的 自己->爸爸妈妈->爷爷奶奶->…
再根据 stident1 创建一个 stident2

我们常常会不知道这张表的前后关系,由哪些表生成这张表,这张表最后又去了哪里,然后就需要从各种sql,存储过程,代码,甚至kettle等ETL工具中来找到我们想要的信息,耗时又耗力
因此如果有可以在开发的过程中就把表的上下游依赖录入到元数据管理平台中,那会方便很多

数据库存的时候:
1、通过product_id或者topic_id来区分不同链路
2、通过label字段,来标识每张表的等级(属于ods还是dwd还是dws,临时表就写tmp,维表就写dim)
3、通过order字段来标识表的先后顺序,ods层order=0,dwd层order=10,dws层order=20,以此类推,比如dwd到dws中间临时表,order就可以使用11,多张临时表就12,13往后,如果dim指向tmp表,那order就和tmp表一样,否则就和tmp叫一样order往后排就行了
4、如果存在join,需要记录是哪种join(可以用实线,虚线和箭头的方向来表示inner还是leftjoin),通过什么字段join(单独做一张表来记录如何关联,当然实在不想记录。。。也行吧)
备注:上图的title是ods,dwd,dws,dm,这是数仓基础的分层,那么如果是一个数据产品的血缘关系的话,是不是可以自定义title,同一个层的表有没有先后依赖关系,这些可能都需要实际做的时候,加入人工的思考与判断
如何自动的收集:
如果是sql的话,其实做sql解析还是做得到的,可以百度到相关的东西,使用正则,或者一些sql解析工具包啊是ok的
如果是写成代码,或者存储过程,这就比较麻烦了,一般是需要手动去填写相关信息
如果是kettle或者其他框架写好了一串流程,那么也不太好收集这部分信息,所以类似这个,是否可以自研一个调度框架来解决这个问题(大多数人使用kettle应该用的是shell,sql,写文件,发邮件等基础功能),要做一个自研的框架,并把流程写到里面应该是没什么太大问题,然后每天定时调度功能也写一下就好(当然肯定是需要版本迭代更新,提供新的功能,仁者见仁智者见智了)
2、实现方案:hive hooks
经过调研,目前业界有一些优秀的框架,比如druid ,内部已经实现了大部分的解析功能,可以用来解析sql,但是它的缺点是支持mysql天衣无缝,但对hive sql却是有心无力,不能照顾到所有的语法,会导致有一部分sql不能很好的解析。
也有一些同学选择自己解析asttree来实现,但sql的语法千变万化,自己去解析难度还是很大的,尤其是一旦hive版本升级了,就得去关注新版本又更新了哪些语法,然后自己的代码也得跟进,很辛苦呀~~
我的想法是:利用hive内部解析的方法来解析sql,这样,凡是能在hive中执行的sql,都能够全面解析到字段依赖。
这个方法就要求我们 要对hive的解析过程非常了解,没关系呀,这个我完全擅长,通过对hive编译模块源码的透析,早已熟悉了各个模块在哪个数据结构里,掘地三尺,也是能把这些给挖出来的。
这个方法的主要难点就是该从什么地方切入呢,毕竟源码相关的,都是hive内部的结构,最好不要对源码做侵入性的修改。
在看源码时,发现hive 有个很牛逼的彩蛋:hive hooks 。hive hooks绑定了hive内部的工作机制,提供了使用hive扩展和集成外部功能的能力,可用于在查询处理的各个步骤中注入一些代码,而无需重新编译hive。
接下来就看该在哪个阶段注入代码了,根据钩子的类型,它可以在查询处理期间的不同点调用:
Pre-semantic-analyzer hooks:在Hive在查询字符串上运行语义分析器之前调用。
Post-semantic-analyzer hooks:在Hive在查询字符串上运行语义分析器之后调用。
Pre-driver-run hooks:在driver执行查询之前调用。
Post-driver-run hooks:在driver执行查询之后调用。
Pre-execution hooks:在执行引擎执行查询之前调用。
Post-execution hooks:在查询执行完成之后以及将结果返回给用户之前调用。
Failure-execution hooks:当查询执行失败时调用。
实现过程:
整个实现过程比较简单,是因为发现hive的api案例中已经实现了类似的功能,我们要做的就是把这个稍做改造。
研究hive hooks 的api时,发现hive已经实现了一个血缘关系的hook:
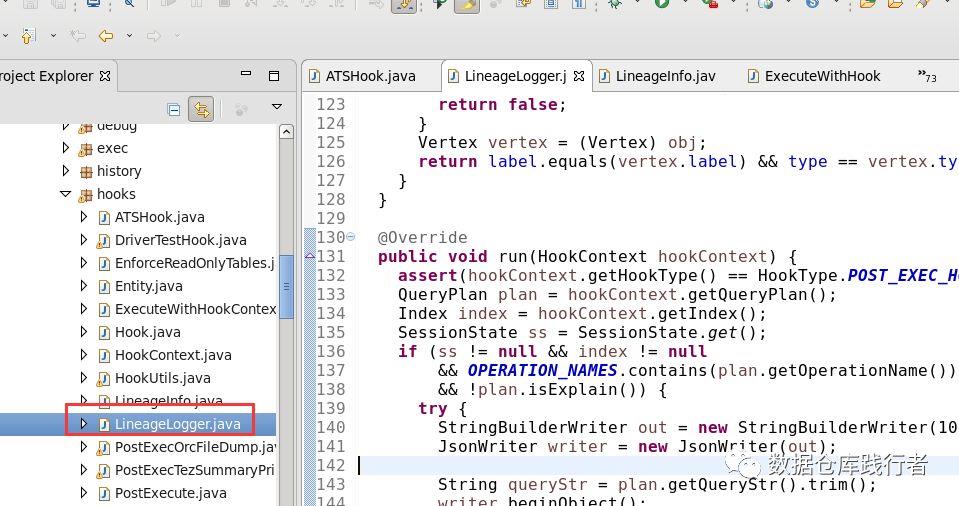
只是这个hook 是把相关的依赖写在了 log里:
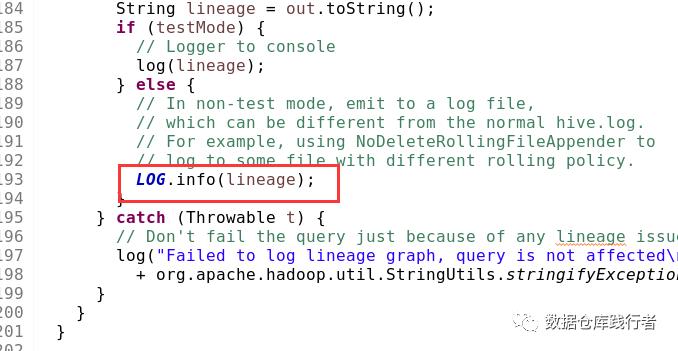
下面,我们需要做一些设计,比如设计一张mysql表t_table_column_dependency来存放字段依赖的关系:

如上,要有依赖关系的创建时间和更新时间,方便及时清理已经过期的依赖
部分写入代码如下 :
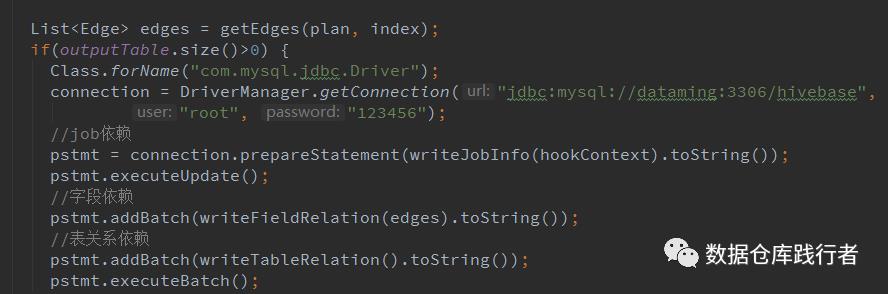
部署、添加参数
vim $HIVE_HOME/conf/hive-site.xml

创建auxlib
cd $HIVE_HOME/
mkdir auxlib ## 这个目录主要存放用户自定义jar包,将编译好的jar上传至该目录
这样部署就完成了,执行hive sql会自动调用该方法,将依赖关系写入数据库,前端页面从数据库中读取信息展示
测试案例:
–创建三张表
CREATE TABLE IF NOT EXISTS EXPOSURE (
session_id string COMMENT 'session_id',
kv map<string,string>
) PARTITIONED BY (day string );
create table tmp_test_a (s1 string, s2 int);
create table tmp_test_b (s1 string, s2 int);
--insert语句
insert into table tmp_test_a
select
tmp.s1,
tmpb.s2
from ( select session_id,kv['CC'] as ss from EXPOSURE where day=20190101 ) tmp
left join tmp_test_b tmpb on tmp.session_id=tmpb.s1
结果:
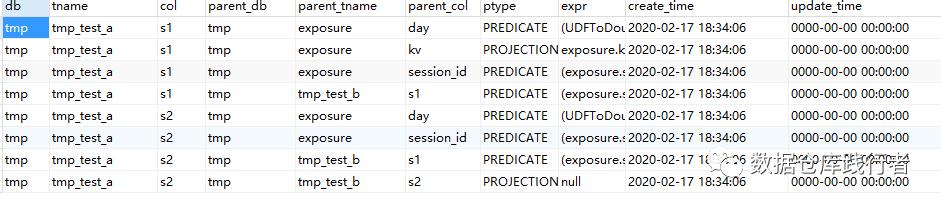
总结
利用hive hooks有以下优点:
1、sql执行完后自动更新依赖关系
2、写入依赖关系模块的执行状态不会影响线上的任务,即如果依赖关系由于一些原因写入失败,不会影响线上任务的正常运行
三、impala数据血缘与数据地图系列:
-
解析impala与hive的血缘日志
-
实时采集impala血缘日志推送到kafka
一、解析impala与hive血缘日志-
Impala血缘:
CDH官方文档impala数据血缘:https://docs.cloudera.com/documentation/enterprise/latest/topics/impala_lineage.html
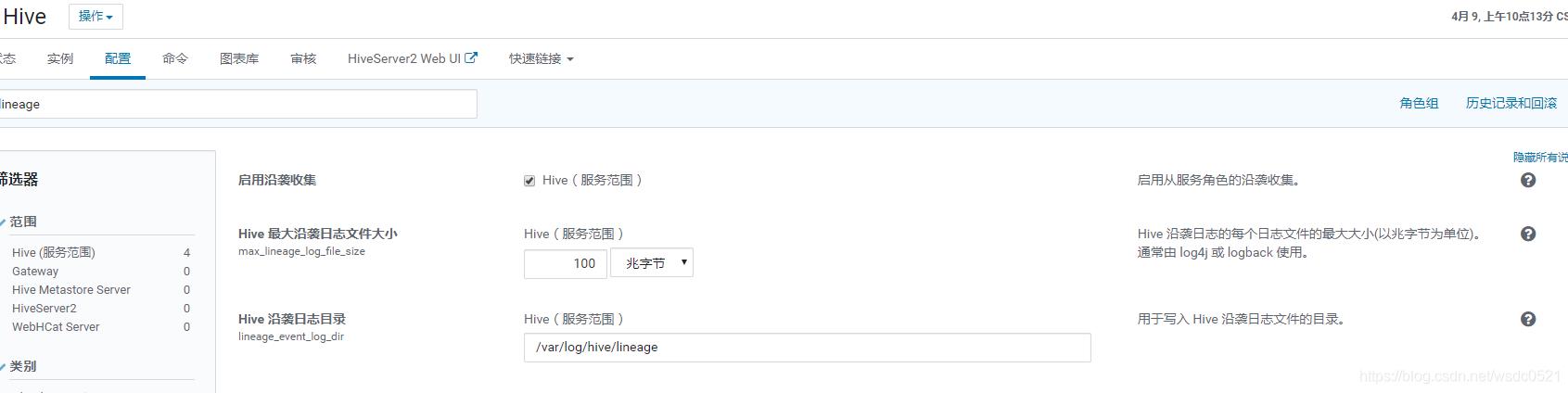
在CM中找到该参数:
开启impala血缘,以及配置血缘日志路径及文件最大限制。
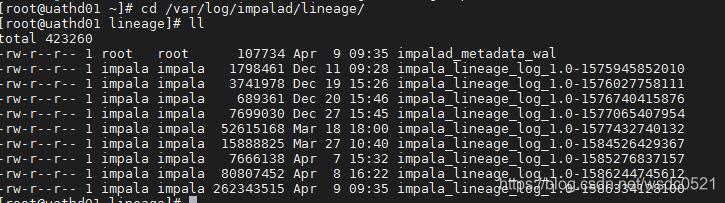
参数:lineage_event_log_dir
目录:每个impala daemon节点下 /var/log/impalad/lineage
需要注意的是这里只记录执行成功的脚本。
我这里使用的是CDH6.2版本,与CDH5的版本在日志记录的结构上有所区别,但区别不大。

测试:使用impala-shell 指定impala daemon节点启动命令行,执行SQL命令,然后查看该daemon节点最新日志。
impala-shell -i uathd01
这里我创建一个视图:
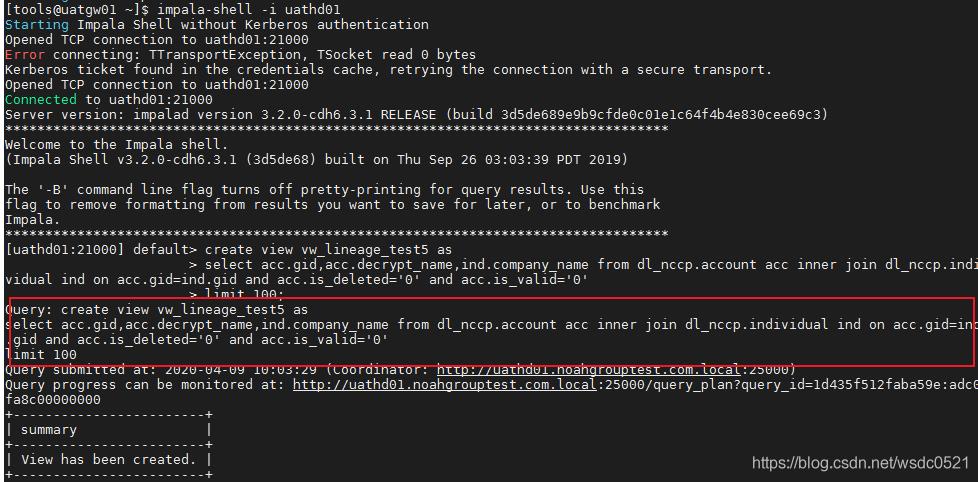
然后到uathd01的节点看最新血缘日志:
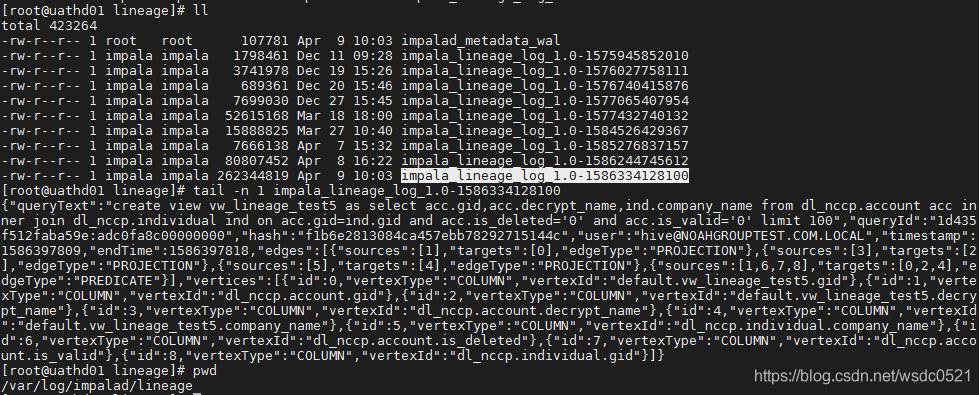
把这段json串拿出来格式化一下看看:
queryText:执行的命令
queryId : impala的执行ID
hash: sql的hash
user:执行该命令的用户
timestamp: 开始时间戳
endTime:结束时间戳
edges: 记录每个source到target的映射关系,edgeType为PREDICATE的部分是所有source字段到所有的target字段id的映射,edgeType为PROJECTION的是每个source字段到每个target字段的映射,这里是多对一的关系,即如果有一个目标字段是由两个源字段处理得来的话,这里的sourceid和targetid就是一个多对一的关系,但如果是一个源字段处理出了两个目标字段,在这里仍旧是两个代码块。
vertices: 该SQL内所有的源和目标字段,与edges中的id一一对应。
"queryText": "create view vw_lineage_test5 as
select acc.gid,acc.decrypt_name,ind.company_name
from dl_nccp.account acc inner join dl_nccp.individual ind on acc.gid=ind.gid and acc.is_deleted='0' and acc.is_valid='0' limit 100",
"queryId": "1d435f512faba59e:adc0fa8c00000000",
"hash": "f1b6e2813084ca457ebb78292715144c",
"user": "hive@NOAHGROUPTEST.COM.LOCAL",
"timestamp": 1586397809,
"endTime": 1586397818,
"edges": [
"sources": [
1
],
"targets": [
0
],
"edgeType": "PROJECTION"
,
"sources": [
3
],
"targets": [
2
],
"edgeType": "PROJECTION"
,
"sources": [
5
],
"targets": [
4
],
"edgeType": "PROJECTION"
,
"sources": [
1,
6,
7,
8
],
"targets": [
0,
2,
4
],
"edgeType": "PREDICATE"
],
"vertices": [
"id": 0,
"vertexType": "COLUMN",
"vertexId": "default.vw_lineage_test5.gid"
,
"id": 1,
"vertexType": "COLUMN",
"vertexId": "dl_nccp.account.gid"
,
"id": 2,
"vertexType": "COLUMN",
"vertexId": "default.vw_lineage_test5.decrypt_name"
,
"id": 3,
"vertexType": "COLUMN",
"vertexId": "dl_nccp.account.decrypt_name"
,
"id": 4,
"vertexType": "COLUMN",
"vertexId": "default.vw_lineage_test5.company_name"
,
"id": 5,
"vertexType": "COLUMN",
"vertexId": "dl_nccp.individual.company_name"
,
"id": 6,
"vertexType": "COLUMN",
"vertexId": "dl_nccp.account.is_deleted"
,
"id": 7,
"vertexType": "COLUMN",
"vertexId": "dl_nccp.account.is_valid"
,
"id": 8,
"vertexType": "COLUMN",
"vertexId": "dl_nccp.individual.gid"
]
Hive:
同impala类似,不再赘述,区别仅仅是日志的json格式以及记录的详细程度的区别。
应用:
接下来就是如何使用这些血缘的日志,我们已经分析了impala血缘日志的结构,接下来只要使用日志采集工具filebeat或flume,logstash等工具采集每个impala daemon节点上的日志,然后对每个json串进行解析即可,后面的文章会演示如何实时采集impala血缘到kafka,消费kafka里的血缘数据处理后写入neo4j数据库内进行数据血缘数据地图的展示。
原文链接:https://blog.csdn.net/wsdc0521/article/details/105403734
二、实时采集impala血缘日志推送到kafka
使用filebeat采集impala的血缘日志并推送到kafka
采用filebeat的主要原因是因为轻量,对impala的血缘日志采集不需要进行数据过滤和格式转换,因此不需要使用flume或logstash这样占用资源较大的工具。
filebeat的安装及使用请参考官方手册:
https://www.elastic.co/guide/en/beats/filebeat/current/filebeat-overview.html
参数配置:
vim conf/filebeat_impala_lineage.yml
#=========================== Filebeat inputs =============================
filebeat.inputs:
- type: log
# Change to true to enable this input configuration.
enabled: true
# Paths that should be crawled and fetched. Glob based paths.
paths:
#这里指定impala血缘目录,会读取该目录下所有日志
- /var/log/impalad/lineage/*
#============================= Filebeat modules ===============================
filebeat.config.modules:
# Glob pattern for configuration loading
path: $path.config/modules.d/*.yml
# Set to true to enable config reloading
reload.enabled: false
# Period on which files under path should be checked for changes
#reload.period: 10s
#===========kafka output===============
output.kafka:
#指定kafka的节点和topic
hosts: ["uatka01:9092","uatka02:9092","uatka03:9092"]
topic: wyk_filebeat_impala_lineage_new_demo
required_acks: 1
#output.console:
# pretty: true
DEMO:
启动filebeat,注意每个机器上只能启动一个filebeat进程,因此上面的读取日志不要指定文件名。
$FILEBEAT_HOME/filebeat --c $FILEBEAT_HOME/conf/filebeat_impala_lineage.yml -e
启动kafka consumer:
./kafka-console-consumer.sh --bootstrap-server uatka01:9092,uatka02:9092,uatka03:9092 --topic wyk_filebeat_impala_lineage_new_demo --zookeeper uatka01:2181,uatka02:2181,uatka03:2181
启动impala-shell:
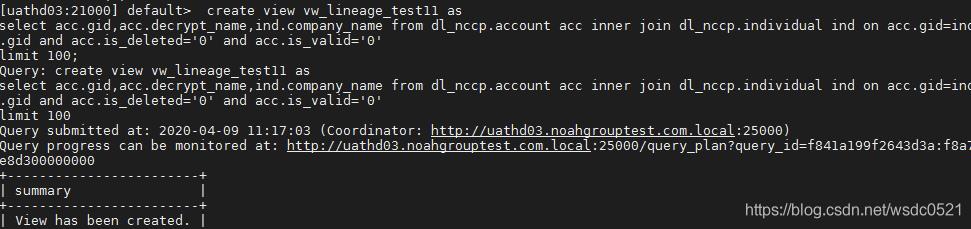
impala-shell -i uathd03
- 在impala-shell内建一个视图:vw_lineage_test11
2.查看impala lineage 日志文件,血缘已记录日志:

- 查看filebeat控制台,已监听日志文件并写入kafka topic内:
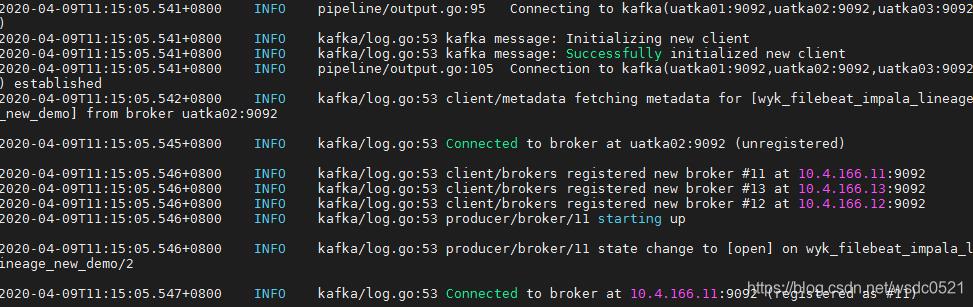
- 查看kafka consumer是否消费到该血缘记录:

流程结束:
impalaSQL–> impala血缘日志–>Filebeat–>Kafka
完成监控impala脚本并将血缘日志推送到kafka内。
后续只需要实时消费kafka里的信息即可。
————————————————
原文链接:https://blog.csdn.net/qq_22473611/article/details/105440946
以上是关于数据治理:元数据管理 数据血缘(补充学习)的主要内容,如果未能解决你的问题,请参考以下文章