逻辑回归实践
Posted crjia
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了逻辑回归实践相关的知识,希望对你有一定的参考价值。
1.逻辑回归是怎么防止过拟合的?为什么正则化可以防止过拟合?
答:
(1)可以通过增加样本量,或者提取不重要的特征进行降维来防止过拟合,也可以通过正则化来防止过拟合。
(2)正则化的原理,就是通过约束系数(w)的大小,进而抑制整体的过拟合情况。
2.用logiftic回归来进行实践操作,数据不限。
答:
我这次选择的实践是,利用逻辑回归 依据各种属性数据预测乳腺癌的患病情况。
数据应用的是UCI的 威斯康星州(诊断)数据 ,并给它添加了标签。(一共570条数据)。
其属性信息为:
1)ID号
2)诊断(M =恶性,B =良性)
3-32)
为每个细胞核计算十个实值特征:
a)半径(中心到周长上各点的距离的平均值)
b)纹理(灰度值的标准偏差)
c)周长
d)面积
e)光滑度(半径长度的局部变化)
f)紧凑度(周长^ 2 /面积-1.0)
g)凹度(轮廓凹部的严重程度)
h )凹点(轮廓的凹入部分的数量)
i)对称性
j)分形维数(“海岸线近似”-1)
实验代码:
from sklearn.model_selection import train_test_split # 划分数据集
from sklearn.linear_model import LogisticRegression # 逻辑回归
from sklearn.metrics import classification_report
from sklearn.preprocessing import StandardScaler # 标准化处理
#导入基础的库
import pandas as pd
data = pd.read_csv(r‘D:shujvjiaizhenghuanzhe1.csv‘, encoding=‘utf-8‘) #读取csv数据
#data.head(3)
x_data = data.iloc[:, 2:10]
y_data = data.iloc[:, 1]
x_train, x_test, y_train, y_test = train_test_split(x_data, y_data, test_size=0.3) #划分测试集占整体30%
#进行标准化处理
std = StandardScaler()
x_train = std.fit_transform(x_train)
x_test = std.transform(x_test)
#建模
mylg = LogisticRegression() #应用逻辑回归算法
mylg.fit(x_train, y_train) #用逻辑回归构建模型
print(‘模型参数:
‘, mylg.coef_) #其结果代表θ,以矩阵方式呈现
mylg_predict = mylg.predict(x_test) #预测
target_names = [‘M‘, ‘B‘]
print(‘准确率:
‘, mylg.score(x_test, y_test))
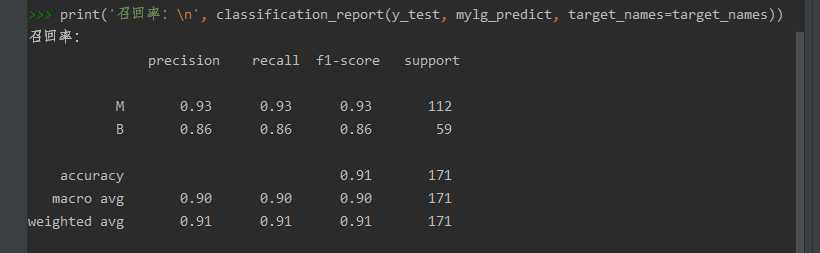
print(‘召回率:
‘, classification_report(y_test, mylg_predict, target_names=target_names))
模型参数:

模型准确率:

召回率和预测精度:
![]()
以上是关于逻辑回归实践的主要内容,如果未能解决你的问题,请参考以下文章