小目标检测
Posted wujianming-110117
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了小目标检测相关的知识,希望对你有一定的参考价值。
小目标检测
论文地址:
https://arxiv.org/pdf/2004.12432.pdf
一.Stitcher: Feedback-driven Data Provider for Object Detection
目标检测通常根据尺度变化质量,其中对小目标的性能最不令人满意。本文研究了这种现象,发现:在大多数训练迭代中,小目标几乎不占总损失的一部分,从而导致不平衡优化的性能下降。受此启发,本文提出了Stitcher,一个反馈驱动的数据提供商,旨在以平衡的方式训练目标检测器。在Stitcher中,图像被调整成更小的组件,然后Stitch成与常规图像相同的大小。Stitch图像包含不可避免的较小对象,这将有利于作者的核心思想,利用损失统计作为反馈,以指导下一次迭代更新。在不同的检测、骨干网、训练周期、数据集上进行了实验,甚至在实例分割上也进行了实验。Stitcher在所有设置中都稳定地提高了性能,特别是对于小对象,在训练和测试阶段几乎没有额外的计算。代码和模型将公开提供。
二. Motivation
在COCO数据集中,研究detection的training方式,当时尝试了Multi-scale training的各种settings、SNIP[1]/SNIPER[2]、CSN[3]等。发现Multi-scale training对模型训练是真的很有帮助,即使在接近50 AP的高baseline上还有不俗的提升。
然而,普通的Multi-scale training太低效了,而SNIPER是真的复杂,需要处理好label assignments, valid range tuning, positive/negative chip selection,费了作者很大的力气才把它从MXNet源码迁移到自己的框架上。
这样的心态和需求,迫使去研究一种更简洁实用的multi-scale training 方法。
不管是普通训练还是Multi-scale training,作者发现在COCO上训练出来的模型,小物体的AP永远是比中物体和大物体低很多。
比如,在最常用的baseline: Faster R-CNN + ResNet 50-FPN (1x) 的结果(AP: 36.7 %, AP small: 21.1 %, AP mid: 39.9 %, AP large : 48.1 %)中,AP small 比 AP large 低了两倍还多。
接下来,作者就开始研究,小物体到底出了什么问题,以及怎样解决这样的问题。
首先,作者统计了小物体在数据集中的分布,发现训练集中小物体的数量并不少。
如下表所示,在所有boxes中,有41.4 %是小物体,是这三类物体之中最多的;但小物体的分布却非常不均匀,只有52.3%的图片中包含了小物体,而中物体和大物体分布都相对均匀。
换句话说,小物体数量很多、但分布非常不均匀,有接近50%的图片中都没有小物体。

接下来,作者又统计了一下,在训练过程中小物体的loss分布。能直接反应模型学习情况的是loss,进一步发现,还是在这个Baseline: Faster R-CNN + ResNet 50-FPN (1x)的训练过程中,有超过50% iterations中,小物体所产生的loss都非常低(不到总loss的0.1)。
这说明在模型训练过程中,小物体提供给网络的监督是不足的。
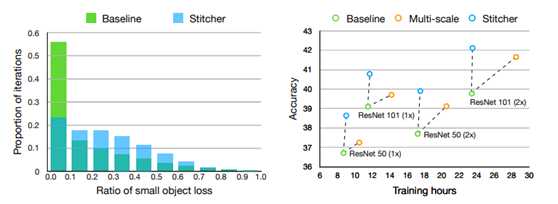
通过上述分析,作者的猜疑链形成:数据集中小物体分布不均匀 --> 训练中小物体学习不充分(Loss不足) --> 训练完的模型小物体精度差。而接下来就是按照这个逻辑逐步设计解决方法。
三.Method
在已经有了前面multi-scale
training和SNIPER的实验结果后,作者想到可以把图像缩小,并拼接在一起(逆SNIPER而行,SNIPER是裁剪,Stitcher是拼接)。
如下图所示,作者把batch内每4张图都缩小到同样大小,之后拼成一张与正常普通同样大小的图作为训练。通过这样的方式,把大物体和中物体缩小成中物体和小物体,来均衡不同Scale物体在训练过程中的分布。

(这里与YOLOv4-Mosaic类似,但不同的是作者没想到拼接的时候可以调整4张图为不同大小。)
接下来就是紧张刺激的实验环节,完全采用这种拼接图进行训练,在上文36.7% 的baseline上得到了32.1%的惊人结果。
然而,就算在32.1% 的 AP 中(AP small: 21.9, AP mid: 36.4, AP large: 36.8)的AP small仍然比36.7% 的baseline中的AP small要高,这让作者看到了希望。
这说明,拼接图是有用的,只是作者没用好,所以影响了最终效果。
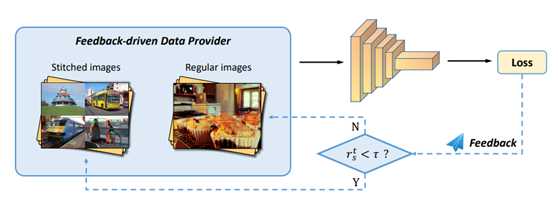
前面对训练过程中loss的分析,给作者提供了一个自然而然的思路,就是直接用loss 作为反馈信号,来指导拼接图的使用。
作者采用了一种“缺啥补啥”的简单思路:如果上一个iteration中,小物体产生的loss不足(比例小于一个阈值),则下一个iteration就用拼接图;否则就用正常图片训练。
这个思路将32.1%的结果一下子增长到了38.6%,且统计loss比例几乎不需要额外的计算量。
四. Experimental Result
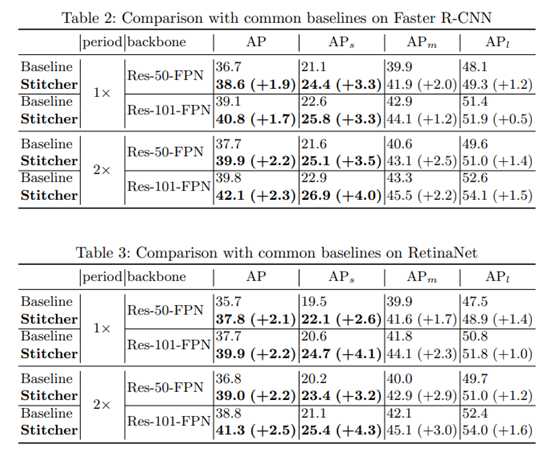
1. 作者在Faster R-CNN、RetinaNet的1x / 2x上都进行了实验,有2个点左右的AP提升,且涨点主要来自于AP small。这符合作者最初的Motivation和方法设计。
2. 此外,作者还在更大的backbone / 更高的baseline (ResNext + Deformable) 、其他数据集 (PASCAL VOC)、Instance Segmentation (Mask R-CNN) 等settings上都做了实验验证,都有不同程度的效果提升。
五. Further Analysis
除了常规实验以外,还有一些其他的效果分析可供讨论。
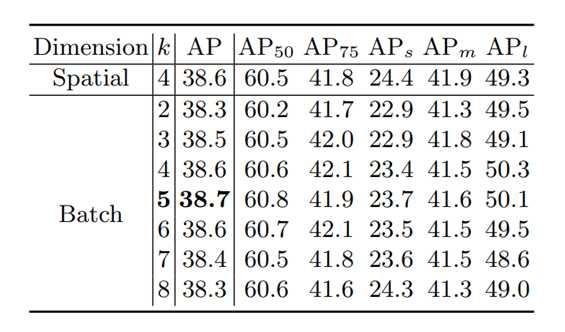
1. 只能4张 (平方数) 拼接吗?答案是否定的。
不管是上文介绍的拼接方式还是YOLO v4,都是在Spatial维度 (h,w)上进行拼接的。如下图(c)中所示,本文还提供了一种在batch维度n上拼接的等价的实现方式,也能达到一样的效果。
这样的做法可以带来如下好处:
a. 拼接图像的数目不再需要因为spatial的限制局限于平方数,可以自由选择2、3、4、5、6等张数图像进行拼接。
b. 对于那些读写内存有限制的训练设备平台,提供了一定的自由度。
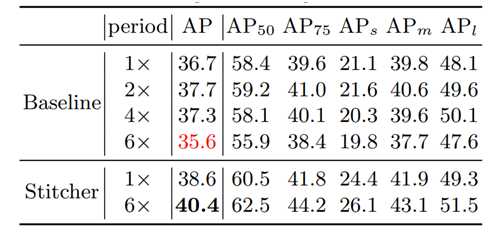
2. 过拟合问题(更长训练时间的增益)在后续实验中,作者还发现Stitcher可以起到防止过拟合的作用。在不用SyncBN之类的骚操作的情况下,把一个最普通的Faster R-CNN + FPN模型直接训练时间较长(6x)是会有严重的过拟合的(36.7-->35.6),但Stitcher却没有这个问题。因为在Stitcher训练过程中,拼接图像的挑选组合是随机的,拼接图像的多样性防止了过拟合的发生。
3. 计算量代价
a. 对于Inference阶段,Stitcher 没有做任何修改,不需要调multi-scale testing之类的操作。所以,如果使用者只关心Inference time 的话,Stitcher带来的涨点可以说是完全免费的。
b. 对于Training阶段,Stitcher 额外引入的操作包括:image stitching 和 loss ratio calculation这两步。经实测,后者可以忽略不计,额外的耗时集中在于前者对图像的interpolation. 作者在同一台 8 GPUs RTX 2080 TI 的机器上实测,对于Faster R-CNN + ResNet 50 + FPN的baseline上,加上Stitcher需要额外多训练15分钟左右。这相比于8个多小时的训练来说,多等15分钟也是可以接受的。
六.Conclusion
总结一下,作者这篇工作从小物体精度低这个问题入手分析,提出了一种新的multi-scale training方式 Stitcher,在常用的数据集、检测器、训练方式上均涨点明显,没有引入任何Inference负担,有一定的简洁实用性。代码和模型都会在近期开源。
参考文献:
1.An Analysis of Scale Invariance in Object Detection
SNIPhttp://openaccess.thecvf.com/content_cvpr_2018/papers/Singh_An_Analysis_of_CVPR_2018_paper.pdf
2.SNIPER: Efficient Multi-Scale
Traininghttps://papers.nips.cc/paper/8143-sniper-efficient-multi-scale-training.pdf
3.Consistent Scale Normalization for Object Recognition
以上是关于小目标检测的主要内容,如果未能解决你的问题,请参考以下文章