DStreaming练习
Posted yaoss
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了DStreaming练习相关的知识,希望对你有一定的参考价值。
DStream接收socket数据统计
安装并启动生产者
#在linux系统上安装nc工具,利用它向某个端口发送数据 yum -y install nc #执行发送数据命令 nc -lk port
执行streaming依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.12</artifactId>
<version>${spark.version}</version>
<scope>provided</scope>
</dependency>
spark Streaming程序
import org.apache.spark.streaming.{Seconds, StreamingContext} import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream} import org.apache.spark.{SparkConf, SparkContext} object Spark_Socket { def main(args: Array[String]): Unit = { //创建SparkConf val sparkConf: SparkConf = new SparkConf().setAppName("socket").setMaster("local[2]") //创建SparkContext val sc = new SparkContext(sparkConf) sc.setLogLevel("warn") //创建StreamingContext需要一个SparkContext对象,还有一个批处理时间间隔,表示没5S处理一次数据 val ssc = new StreamingContext(sc, Seconds(5)) //接受scoket数据 val socketTextStream: ReceiverInputDStream[String] = ssc.socketTextStream("ip", 9999) //切分每一行数据 val words:DStream[String] = socketTextStream.flatMap(_.split(" ")) //每个单词记为1 val pairs = words.map(word => (word, 1)) //向童单词出现累加1 val result = pairs.reduceByKey(_ + _) //打印输出 result.print() //开启流式计算 ssc.start() ssc.awaitTermination() } }
数据(在一个批次间隔内发送)
dada hello
hello helll
helll
结果

package houpu.com.SparkStream
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
object SparkStreaming_Socket_Total {
def main(args: Array[String]): Unit = {
//currentValues:当前批次相同的单词出现的素有的1.(wangan,1)(wangan,1)(wangan,1)--->List(1,1,1)
//historyValues:在之前所有批次中,相同单词出现的总次数
def updateFunc(currentValues:Seq[Int],historyValues:Option[Int]):Option[Int]={
val newValue:Int = currentValues.sum + historyValues.getOrElse(0)
Some(newValue)
}
//创建SparkConf
val sparkConf: SparkConf = new SparkConf().setAppName("socket").setMaster("local[2]")
//创建SparkContext
val sc = new SparkContext(sparkConf)
sc.setLogLevel("warn")
//创建StreamingContext需要一个SparkContext对象,还有一个批处理时间间隔,表示没5S处理一次数据
val ssc:StreamingContext = new StreamingContext(sc, Seconds(5))
//接受scoket数据
val socketTextStream: ReceiverInputDStream[String] = ssc.socketTextStream("ip", 9999)
//切分每一行数据
val words:DStream[String] = socketTextStream.flatMap(_.split(" "))
//每个单词记为1
val pairs = words.map(word => (word, 1))
//缓存rdd过程的数据
ssc.checkpoint("hdfs://ip:9000/dict01/save/relt02")
//向童单词出现累加1
val result = pairs.updateStateByKey(updateFunc)
//打印输出
result.print()
//启动并等待数据流的到来
ssc.start()
ssc.awaitTermination()
}
}
数据
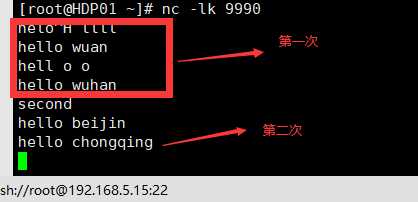
结果
第一个批次间隔内测试

第二个批次间隔内测试结果

三、
package houpu.com.SparkStream
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
object SparkStreaming_SocketWindow {
def main(args: Array[String]): Unit = {
//创建SparkConf
val sparkConf: SparkConf = new SparkConf().setAppName("socket").setMaster("local[2]")
//创建SparkContext
val sc = new SparkContext(sparkConf)
sc.setLogLevel("warn")
//创建StreamingContext需要一个SparkContext对象,还有一个批处理时间间隔,表示没5S处理一次数据
val ssc:StreamingContext = new StreamingContext(sc, Seconds(5))
//接受scoket数据
val socketTextStream: ReceiverInputDStream[String] = ssc.socketTextStream("ip", 9999)
//切分每一行数据
val words:DStream[String] = socketTextStream.flatMap(_.split(" "))
//每个单词记为1
val pairs = words.map(word => (word, 1))
//相同单词出现的1累加
//reduceFunc:(V,V) => V,一个函数
//windowOuration:Duration 窗口长度
//slidDuration:Duration 滑动窗口的时间间隔,表示多久计算一次
val result:DStream[(String,Int)] = pairs.reduceByKeyAndWindow((x:Int,y:Int) => x+y,Seconds(10),Seconds(10))
//打印输出
result.print()
//启动并等待数据流的到来
ssc.start()
ssc.awaitTermination()
}
}
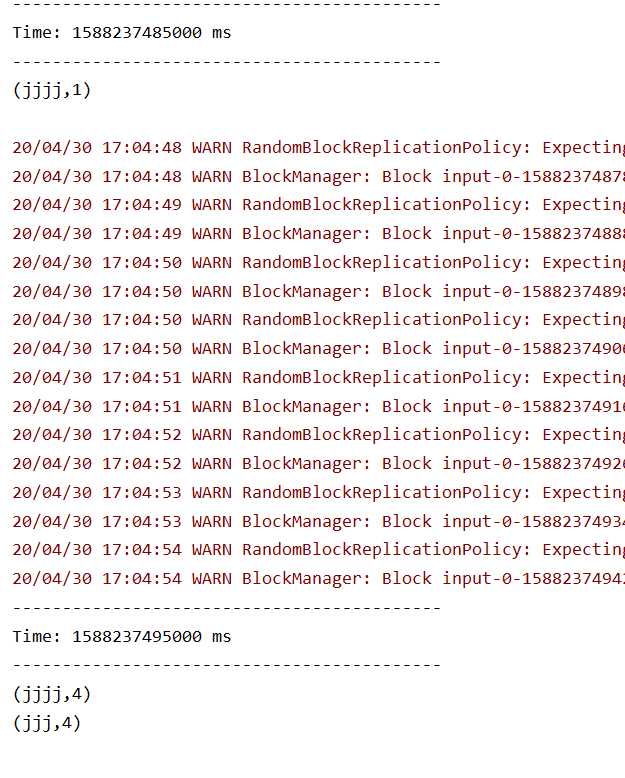
数据
批次间隔为5s,窗口时长是10s,滑出长度是10s,10秒内的数据才会执行统计
这个测试数据,经过两个批次间隔,在10秒内发出

结果
时间差为10s,第二次才是正确统计
四、
package houpu.com.SparkStream
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.ReceiverInputDStream
import org.apache.spark.streaming.{Seconds, StreamingContext}
object TransForm {
def main(args: Array[String]) {
val conf = new SparkConf().setMaster("local[2]").setAppName("TransForm")
val ssc = new StreamingContext(conf,Seconds(5))
//黑名单列表
val blackList = ssc.sparkContext.parallelize(Array(("Mike",true),("Bob",true)))
val socketTextStream: ReceiverInputDStream[String] = ssc.socketTextStream("master", 9999)
val result = socketTextStream.map(line => {
val userinfo = line.split(" ")
(userinfo(0),userinfo(1))
})
//进行黑名单过滤,之筛选出不在黑名单
result.transform(rdd =>{
rdd.leftOuterJoin(blackList).filter(_._2._2.isEmpty)
})print()
//启动并等待数据流的到来
ssc.start()
ssc.awaitTermination()
}
}
//leftOuterJoin类似于SQL中的左外关联left outer join,返回结果以前面的RDD为主,关联不上的记录为空。
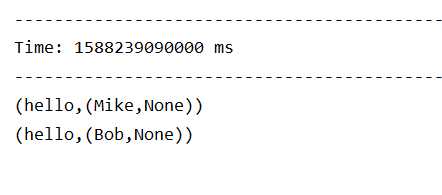
数据
测试数据
hello Mike
hello Bob
结果
五、累加TopN
程序
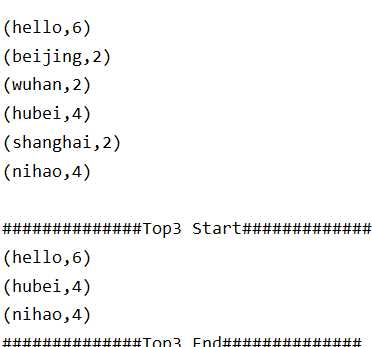
import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} import org.apache.spark.streaming.{Seconds, StreamingContext} import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream} object SparkStream_SocketTotal { def main(args: Array[String]): Unit = { //currentValues:当前批次相同的单词出现的素有的1.(wangan,1)(wangan,1)(wangan,1)--->List(1,1,1) //historyValues:在之前所有批次中,相同单词出现的总次数 def updateFunc(currentValues:Seq[Int],historyValues:Option[Int]):Option[Int]={ val newValue:Int = currentValues.sum + historyValues.getOrElse(0) Some(newValue) } //创建SparkConf val sparkConf: SparkConf = new SparkConf().setAppName("socket").setMaster("local[2]") //创建SparkContext val sc = new SparkContext(sparkConf) sc.setLogLevel("warn") //创建StreamingContext需要一个SparkContext对象,还有一个批处理时间间隔,表示没5S处理一次数据 val ssc:StreamingContext = new StreamingContext(sc, Seconds(5)) //接受scoket数据 val socketTextStream: ReceiverInputDStream[String] = ssc.socketTextStream("ip", 9999) //切分每一行数据 val words:DStream[String] = socketTextStream.flatMap(_.split(" ")) //每个单词记为1 val pairs = words.map(word => (word, 1)) ssc.checkpoint("hdfs://ip:9000/tets/data02/relt01") //相同单词出现累加1 val result = pairs.updateStateByKey(updateFunc) //按照单词出现的次数降序 val finalResult:DStream[(String,Int)] = result.transform(rdd =>{ //可以使用RDD排序的方法来操作 val sortRDD:RDD[(String,Int)] = rdd.sortBy(_._2,false) //取出次数最多的前三位 val top3:Array[(String,Int)] = sortRDD.take(3) //打印 println("##############Top3 Start##############") top3.foreach(println) println("##############Top3 End##############") sortRDD }) //打印输出 finalResult.print() //打印输出 result.print() //启动并等待数据流的到来 ssc.start() ssc.awaitTermination() } }
数据
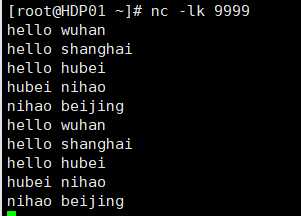
结果
以上是关于DStreaming练习的主要内容,如果未能解决你的问题,请参考以下文章
Python练习册 第 0013 题: 用 Python 写一个爬图片的程序,爬 这个链接里的日本妹子图片 :-),(http://tieba.baidu.com/p/2166231880)(代码片段