推荐算法简介
Posted gaowenxingxing
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了推荐算法简介相关的知识,希望对你有一定的参考价值。
推荐算法
推荐算法简单的来说就是根据用户的喜好来推荐相似的东西
例如淘宝的猜你喜欢,抖音的XXX。
推荐算法的特点csdn
1.根据和你共同喜好的人来给你推荐 ,好友或者关注的人
2.根据你喜欢的物品找出和它相似的来给你推荐 ,淘宝的猜你喜欢
3.根据你给出的关键字来给你推荐,这实际上就退化成搜索算法了 ,类似于学长讲的page ranking,我暂时先这么理解
4.根据上面的几种条件组合起来给你推荐,这个需要收集的信息就比较多了
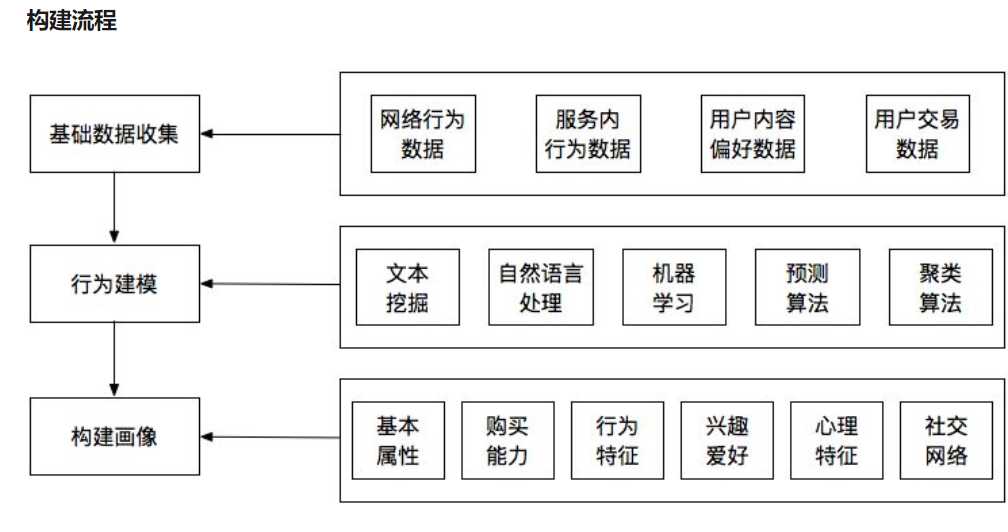
user profile
用户画像是根据用户的社会属性,消费行为,生活习惯抽象出一个标签化的用户模型。(zhihua)[https://www.zhihu.com/question/19853605]
简单的来说就是就是分析user的特点,是根据基础数据不断修正的过程
图片来自zhihu
基于流行度的推荐算法
基于流行度的推荐算法比较简单粗暴,主要是对热点商品或者信息的推荐。它主要是根据PV、UV、日均PV或分享率等数据来按某种热度排序来推荐给用户。
PV:page view 页面的浏览量或者访问量,用户对同一页面的多次访问,算累计
UV:unique view 一个ip只算一个,不算累计wise
VV:visit view 用户一天内访问网页的累计量
这种可以解决新注册的用户的冷启动问题,但是没办法进行个性化推荐。不过可以根据tag进行分类后在进行推荐
基于内容推荐
它的核心思想是根据推荐物品或内容的元数据,发现物品或者内容的相关性,然后基于用户以往的喜好记录,推荐给用户相似的物品。比如你看了哈利波特I,基于内容的推荐算法发现哈利波特II-VI,与你以前观看的在内容上面(共有很多关键词)有很大关联性,就把后者推荐给你。淘宝的猜你喜欢。
- 多用于资讯文章等,可以抽取tag作为相似度
- 易于实现,不需要用户数据因此不存在稀疏性和冷启动问题。
用户数据稀疏性:
现在待处理的推荐系统规模越来越大,用户和商品(也包括其他物品,譬如音乐、网页、文献……)数目动辄百千万计,两个用户之间选择的重叠非常少。如果以用户和商品之间已有的选择关系占所有可能存在的选择关系的比例来衡量系统的稀疏性,那么我们平时研究最多的MovieLens数据集的稀疏度是4.5%,Netflix是1.2%,这些其实都是非常密的数据了,Bibsonomy是0.35%,Delicious是0.046%。想想淘宝上号称有8亿商品,平均而言一个用户能浏览800件吗,我估计不能,所以稀疏度应该在百万分之一或以下的量级。数据非常稀疏,使得绝大部分基于关联分析的算法(譬如协同过滤)效果都不好。这个问题本质上是无法完全克服的,为了解决这个问题,也有很多办法,譬如可以通过扩散的算法,从原来的一阶关联(两个用户有多少相似打分或者共同购买的商品)到二阶甚至更高阶的关联(假设关联性或者说相似性本身是可以传播的)[8],也可以添加一些缺省的打分[9],从而提高相似性的分辨率。数据规模越大,一般而言越稀疏,现在能够处理稀疏数据的算法被认为是更有前途的起个名字真的好难啊哈哈
简单的来说就是特征多,而重叠的样本很少
冷启动:推荐系统需要根据用户的历史行为和兴趣预测用户未来的行为和兴趣,对于BAT这类大公司来说,它们已经积累了大量的用户数据,不发愁。但是对于很多做纯粹推荐系统的网站或者很多在开始阶段就希望有个性化推荐应用的网站来说,如何在对用户一无所知(即没有用户行为数据)的情况下进行最有效的推荐呢?这就衍生了冷启动问题。csdn
-
基于物品本身特征推荐,因此不存在过度推荐热门的问题。
-
抽取的特征既要保证准确性又要具有一定的实际意义,否则很难保证推荐结果的相关性。豆瓣网采用人工维护tag的策略,依靠用户去维护内容的tag的准确性。
-
推荐的Item可能会重复,典型的就是新闻推荐,如果你看了一则关于MH370的新闻,很可能推荐的新闻和你浏览过的,内容一致。也就是重复了
基于关联规则的推荐
基于关联规则的推荐更常见于电子商务系统中,并且也被证明行之有效。其实际的意义为购买了一些物品的用户更倾向于购买另一些物品。基于关联规则的推荐系统的首要目标是挖掘出关联规则,也就是那些同时被很多用户购买的物品集合,这些集合内的物品可以相互进行推荐。目前关联规则挖掘算法主要从Apriori和FP-Growth两个算法发展演变而来。 基于关联规则的推荐系统一般转化率较高,因为当用户已经购买了频繁集合中的若干项目后,购买该频繁集合中其他项目的可能性更高。
对已有的用户购买行为信息,推荐相似物品。
- 样本大,计算量大
- 用户数据稀疏,冷启动问题
基于协同过滤的推荐算法
协同过滤是一种在推荐系统中广泛采用的推荐方法。这种算法基于一个“物以类聚,人以群分”的假设,喜欢相同物品的用户更有可能具有相同的兴趣。基于协同过滤的推荐系统一般应用于有用户评分的系统之中,通过分数去刻画用户对于物品的喜好。而是通过用户建立物品与物品之间的联系。
3.4.1 基于用户(User-based)的推荐
基于用户的协同过滤推荐的基本原理是,根据所有用户对物品或者信息偏好(评分),发现与当前用户口味和偏好相似的“邻居”用户群,在一般应用中是采用计算K近邻的算法;基于这 K个邻居的历史偏好信息,为当前用户进行推荐。 这种推荐系统的优点在于推荐物品之间在内容上可能完全不相关,因此可以发现用户的潜在兴趣,并且针对每个用户生成其个性化的推荐结果。缺点在于一般的Web系统中,用户的增长速度都远远大于物品的增长速度,因此其计算量的增长巨大,系统性能容易成为瓶颈。因此在业界中单纯的使用基于用户的协同过滤系统较少。
就是根据用户分类,相似度矩阵是根据用户之间的
基于物品(Item-based)的推荐
基于物品的协同过滤和基于用户的协同过滤相似,它使用所有用户对物品或者信息的偏好(评分),发现物品和物品之间的相似度,然后根据用户的历史偏好信息,将类似的物品推荐给用户。基于物品的协同过滤可以看作是关联规则推荐的一种退化,但由于协同过滤更多考虑了用户的实际评分,并且只是计算相似度而非寻找频繁集,因此可以认为基于物品的协同过滤准确率较高并且覆盖率更高。 同基于用户的推荐相比,基于物品的推荐应用更为广泛,扩展性和算法性能更好。由于项目的增长速度一般较为平缓,因此性能变化不大。缺点就是无法提供个性化的推荐结果。
根据物品进行分类,相似度矩阵是物品之间
- 因此无论基于物品的推荐算法还是基于商品的推荐算法,都是基于用户的历史数据的,对于新用户的话就会存在用户的冷启动问题。
- 结果会依赖用户的偏好数据,而用户的额偏好数据是稀疏的
- 对于用户的偏好变化趋势是无法从历史数据中得到的
基于模型的推荐算法
基于模型的方法有很多,主要是使用常用的机器学习算法对目标用户建立推荐算法模型,然后对用户的爱好进行预测推荐以及对推荐的结果打分排序等。 常用的模型包括Aspect Model,pLSA,LDA,聚类,SVD,Matrix Factorization,LR,GBDT等,这种方法训练过程比较长,但是训练完成后,推荐过程比较快且准确。因此它比较适用于实时性比较高的业务如新闻、广告等。当然,而若是需要这种算法达到更好的效果,则需要人工干预反复的进行属性的组合和筛选,也就是我们常说的 特征工程。而由于新闻的时效性,系统也需要反复更新线上的数学模型,以适应变化。基于模型的算法由于快速、准确,适用于实时性比较高的业务如新闻、广告等,而若是需要这种算法达到更好的效果,则需要人工干预反复的进行属性的组合和筛选,也就是常说的Feature Engineering。而由于新闻的时效性,系统也需要反复更新线上的数学模型,以适应变化。
真正的现实应用中,其实基本上很少会使用单一的推荐算法去实现推荐任务。因此,大型成熟网站的推荐系统都是基于各种推荐算法的优缺点以及适合场景分析的情况下的组合使用的“混合算法”。当然,混合策略也会是十分丰富的,例如不同策略的算法加权、不同场景和阶段使用不同的算法等等。具体的怎么混合需要结合实际的应用场景进行分析与应用。
CTR
推荐系统中使用ctr预估模型
ctr即广告点击率,在推荐系统中,通常是按照ctr来对召回的内容子集进行排序,然后再结合策略进行内容的分发。
LR
能够很好的处理离散特征,具体推导见之前的随笔
GBDT
GBDT的优势在于处理连续值特征,比如用户历史点击率,用户历史浏览次数等连续值特征。而且由于树的分裂算法,它具有一定的组合特征的能力,模型的表达能力要比LR强。GBDT对特征的数值线性变化不敏感,它会按照目标函数,自动选择最优的分裂特征和该特征的最优分裂点,而且根据特征的分裂次数,还可以得到一个特征的重要性排序。所以,使用GBDT减少人工特征工程的工作量和进行特征筛选。
GBDT善于处理连续值特征,但是推荐系统的绝大多数场景中,出现的都是大规模离散化特征,如果我们需要使用GBDT的话,则需要将很多特征统计成连续值特征(或者embedding),这里可能需要耗费比较多的时间。同时,因为GBDT模型特点,它具有很强的记忆行为,不利于挖掘长尾特征,而且GBDT虽然具备一定的组合特征的能力,但是组合的能力十分有限,远不能与dnn相比。
GBDT+LR
即先使用GBDT对一些稠密的特征进行特征选择,得到的叶子节点,再拼接离散化特征放进去LR进行训练。在方案可以看成,利用GBDT替代人工实现连续值特征的离散化,而且同时在一定程度组合了特征,可以改善人工离散化中可能出现的边界问题,也减少了人工的工作量。
(X_{n e w}=X+g b d t(x)^{prime} s) nodes
(f(x)=log i) stics (left( ext {linear}left(X_{ ext {new}}
ight)
ight))
dnn
比较著名的是谷歌的wide and deep 推导可以看之前的随笔
以上是关于推荐算法简介的主要内容,如果未能解决你的问题,请参考以下文章