推荐系统与推荐算法概念与简介
Posted nuist__NJUPT
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了推荐系统与推荐算法概念与简介相关的知识,希望对你有一定的参考价值。
推荐系统与推荐算法概念与简介
一、推荐系统的目的
针对海量数据和信息过载的情况。面对海量的数据信息,从中快速提取符合用户特点的物品,解决一些人的选择恐惧症,主要面向一些没有明确需求的人。
一个好的推荐系统应实现三方面
1-让用户更好的获取自己需要的内容
2-让内容更好更快的推送到喜欢的人手中
3-让网站(平台)更有效的保留用户资源
二、推荐系统的应用
推荐系统的应用范围很广,现在比较主流的如抖音,淘宝,微博等等都应用了推荐系统,如下图所示的领域都涉及到推荐系统。不同的业务场景推荐系统是有很大不同的。
三、推荐系统的基本思想
类似于介绍对象的过程,把用户需要的东西推荐给他。
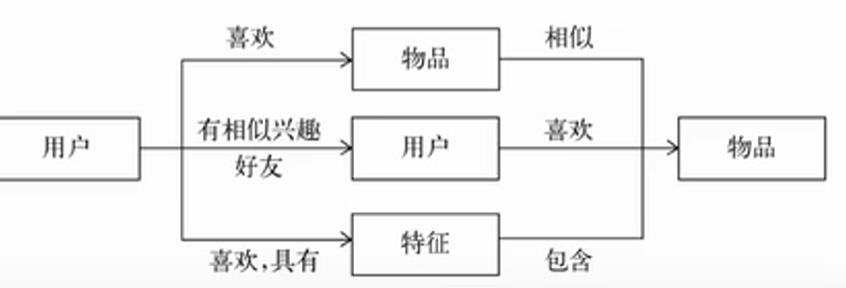
一般是通过三种方式进行推荐:
1-根据用户和物品的特征进行匹配。
2-把用户喜欢过的物品做一个特征提取,找到相似的物品,推荐给用户。
3-找到和用户有相似兴趣和特征的好友,把用户的好友喜欢过的物品推荐给用户。
四、推荐系统的数据分析
推荐系统的数据包含用户数据和物品数据,用户数据包含个人信息,喜好标签,上下文信息,物品信息包含内容信息,分类标签,关键词。
个人信息:一般注册的时会收集用户的相关个人信息。
喜好标签:一般会设置喜欢标签共供用户选择。
上下文信息:通过浏览器的上下文信息,读取cookie,获取用户的浏览记录。
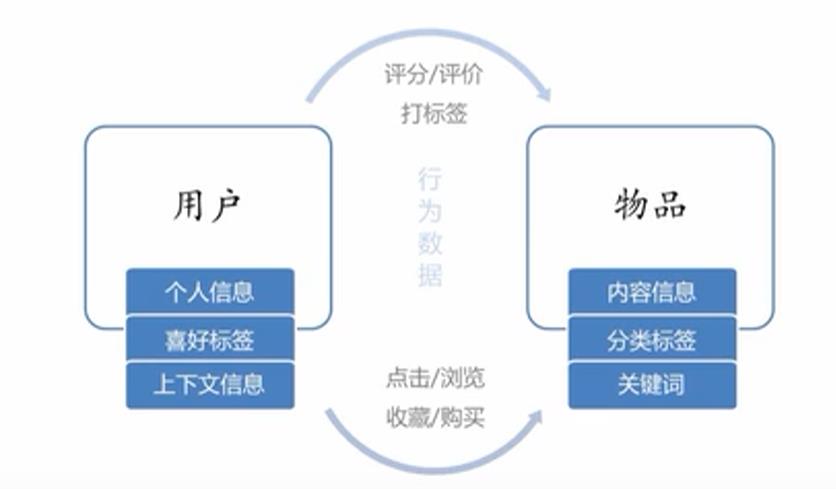
除了用户和物品信息,还有用户和物品的关联信息,即用户的行为信息,比如用户点击,浏览,购买,收藏,评分等。
记录用户的行为信息,可以分为两种反馈机制:
1-显示的用户反馈:这类是用户在网站上自然浏览网站以外,显示的提供的反馈信息,例如:用户对物品的评论,用户对物品的打分。
2隐式的用户反馈:这类是用户使用网站产生的数据,隐式的反映了用户对物品的喜好,例如:用户购买了某物品,用户查看了某物品。
显示的用户反馈一般是从数据库只给你获取,隐式的用户反馈一般从日志中收集。
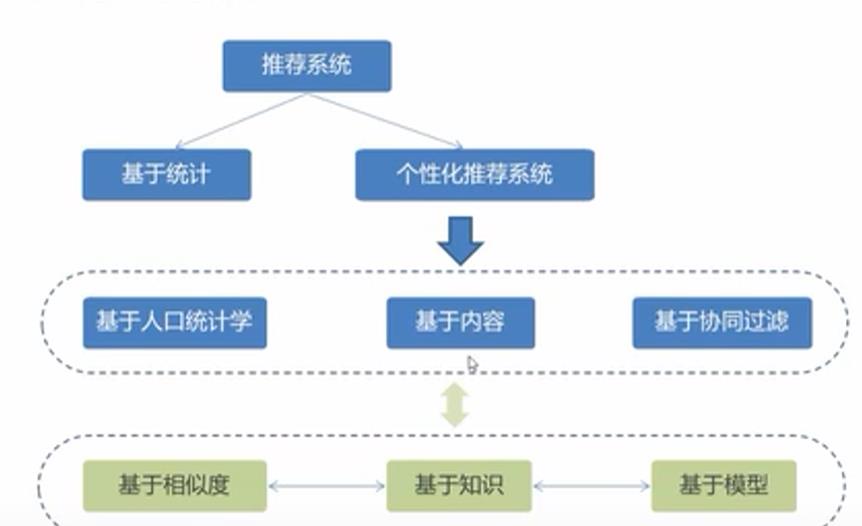
五、推荐系统的分类
根据实时性分类
1-离线推荐
2-实时推荐
根据是否个性化的推荐
1-基于统计的推荐(比如:热门推荐)
2-个性化推荐
根据推荐原则分类
1-基于相似度的推荐(物以类聚,人以群分)
2-基于知识的推荐(定义规则,什么样的人推什么样的物品)
3-基于模型的推荐(训练一个模型,让模型发现规律,再做推荐)
根据数据源分类
1-基于人口统计学的推荐
2-基于内容的推荐(根据物品信息推荐)
3-基于协同过滤的推荐(根据行为数据进行推荐)
六、推荐算法的简介
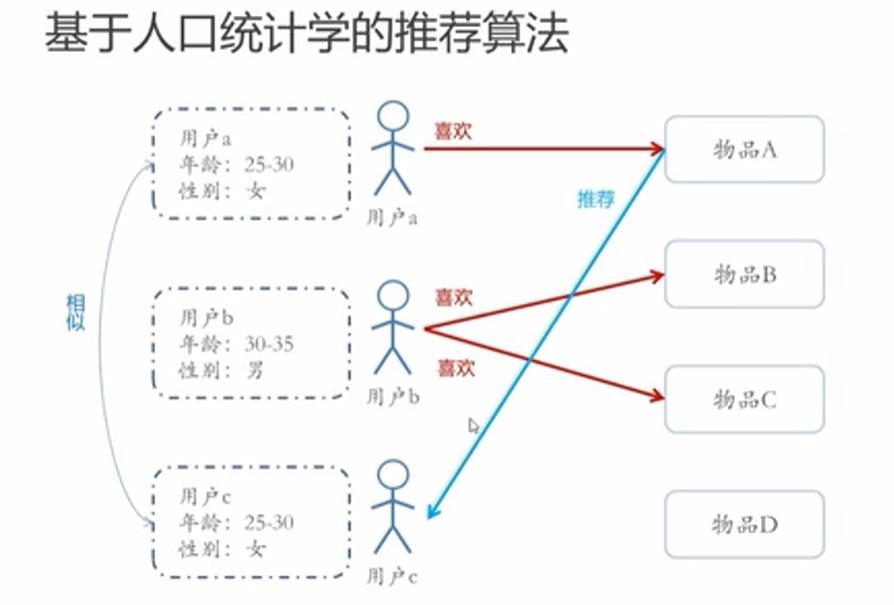
1-基于人口统计学的推荐
用户a和用户c有相似的个人信息,若用户a喜欢A物品,则用户c也可能喜欢A物品,我们可以考虑把A物品推荐给用户c。
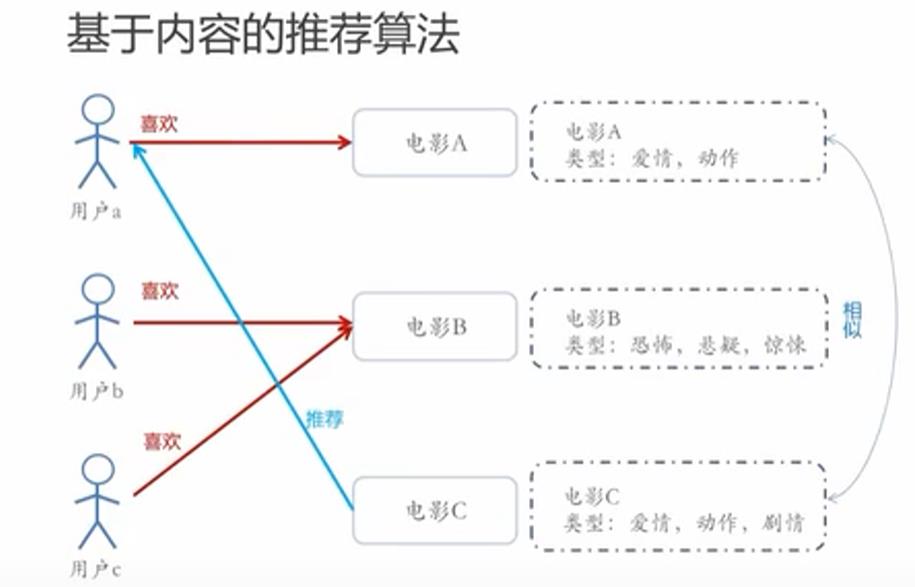
2-基于内容的推荐
物品(电影)A和C有相似的内容信息,用户a喜欢电影A,我们可以考虑将和电影A相似的电影C推荐给用户a
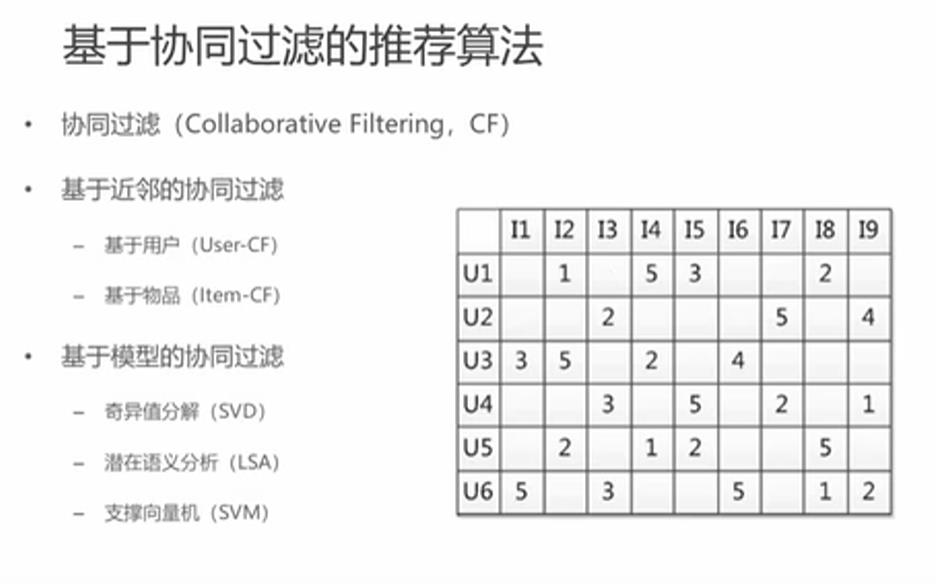
3-基于协同过滤的推荐
根据用户和物品的关系,即用户的行为关系进行推荐。基于协同过滤的推荐可以分为基于近邻的协同过滤和基于模型的协同过滤。
基于近邻的协同过滤可以分为基于用户和基于物品
1-基于用户的协同过滤(User-CF):没有用户信息和物品信息,用户a喜欢过物品A和物品C,用户c喜欢过物品A,C,D,此时,我们可以认为用户a可能喜欢物品D。可以考虑将物品D推荐给用户a
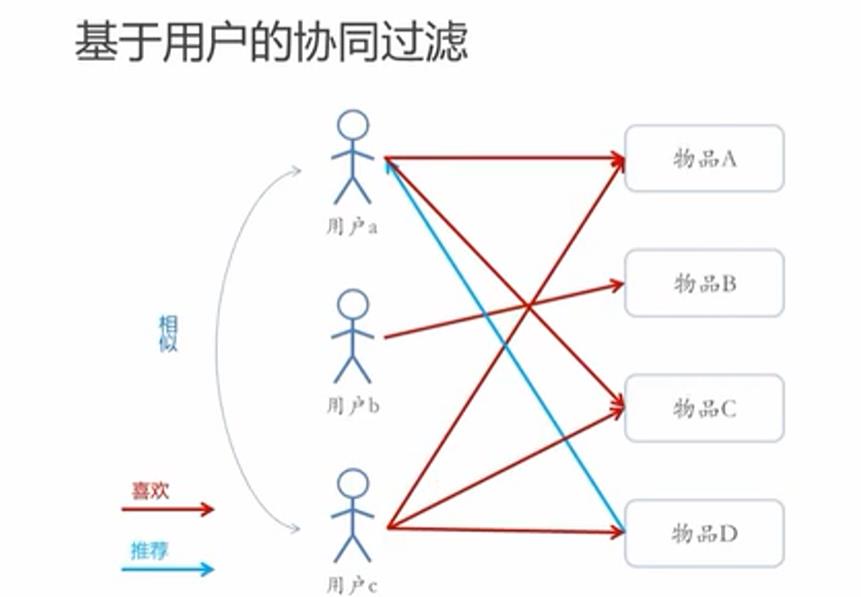
2-基于物品的协同过滤(Item-CF):没有用户信息和物品信息,物品A同时被用户a和用户c喜欢,那么物品C被用户a喜欢,物品C可能也被用户c喜欢。可以考虑将物品C推荐给用户c
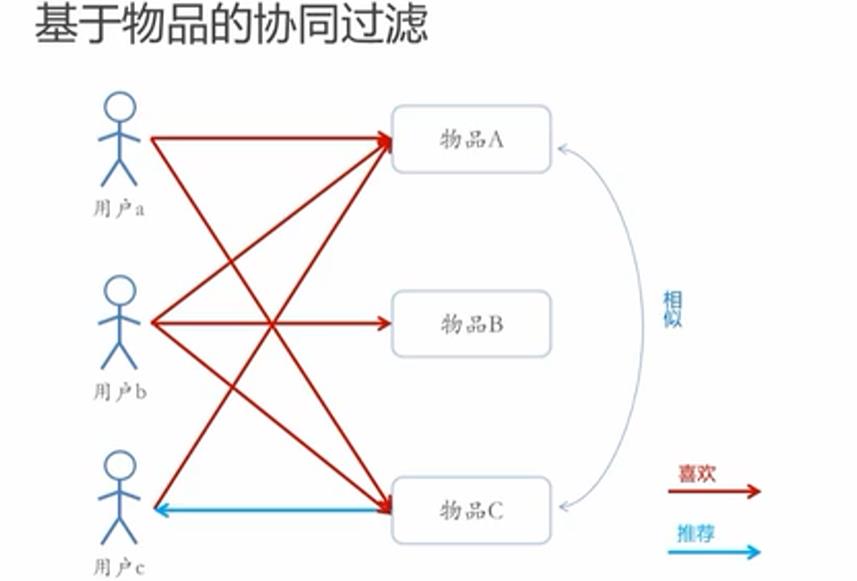
基于内容的推荐算法(CB)主要是利用用户评价过的物品特征,协同过滤推荐算法(CF)还可以利用其它用户评分过的物品。
CF的优点
CF可以解决CB的一些局限:
1-物品内容不完全或者难以获得时,依然可以通过其它用户的反馈给出推荐。
2-CF基于用户之间对物品的评价质量,避免了CB依赖物品内容可能对物品质量判断的干扰。
3-CF推荐不受内容的限制,只要其它类似用户给出对物品的兴趣,CF就可以给用户推荐出内容差距很大,但存在某种联系的物品。
CF的缺点
我们得到的协同过滤数据更多是一个稀疏矩阵,CF比较依赖礼历史数据,冷启动的情况下,需要使用其它推荐方式。
4-混合推荐
实际网站的推荐系统往往都不是单纯的采用了某一种推荐机制和策略,更多的是多种方法混合在一起,从而达到更好的推荐效果,比较流行的组合方法有:
1-加权混合
用线性公式将几种不同的推荐按照一定的权重组合起来,具体的权重值需要在测试数据集上反复的试验,从而达到更好的推荐效果。
2-切换混合
允许在不同的情况下,选择最为合适的推荐机制进行推荐
3-分区混合
采用多种推荐机制,并将推荐结果分不同的区显示给用户。
4-分层混合
采用多种推荐机制,并将一个推荐机制的结果作为输入,从而综合各个推荐机制的优缺点,得到更加准确的效果。
七、推荐系统的实验方法
1-离线实验
通过体制系统获取用户的行为数据,并按照一定的格式生产一个标准的数据集,将数据集按照一定的规则分成训练集和测试集,在训练集上训练用户模型,在测试集上进行预测,通过事先定义的离线指标评测算法在测试集上预测结果。
优点:方便,不需要单独的业务系统
缺点:因为离线,和实际的业务系统还是有些差距,真实可靠程度还是差点意思
2-用户调查
用户调查需要一些真实的用户,让他们在需要测试的推荐系统上完成一些任务,我们需要记录他们的行为,并让他们回答一些问题,最后进行分析
优点:可以直接找到实际用户测试
缺点:靠谱的用户不容易找
3-在线试验
AB测试,原有系统和推荐系统做对比分析。
八、推荐系统的评测指标
1-预测准确度
2-用户满意度(问卷调查)
3-覆盖率(发掘更多小众冷门的物品,而不仅仅是热门物品)
4-多样性
5-惊喜度
6-信任度
7-实时性
8-健壮性
9-商业目标(转换率)
我们写论文做实验,更多考量的是预测准确度问题,比如:我们已知用户对某些网站物品打分信息,我们就可以设计一个模型进行学习,从而预测用户对新物品的评分。至于准不准,我们可以把提前知道评分信息的物品带入到模型进行预测,判断预测的评分与已知评分是否一致。
评分预测的准确度一般用均方差(RMSE)和平均绝对误差(MAE)来计算。
公式如下:其中T表示评分个数,第一个参数r表示真实评分,第二个参数r表示预测评分。
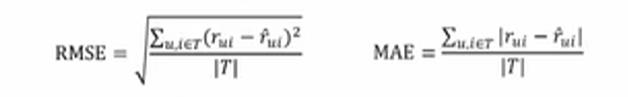
准确率,精准率和召回率的概念

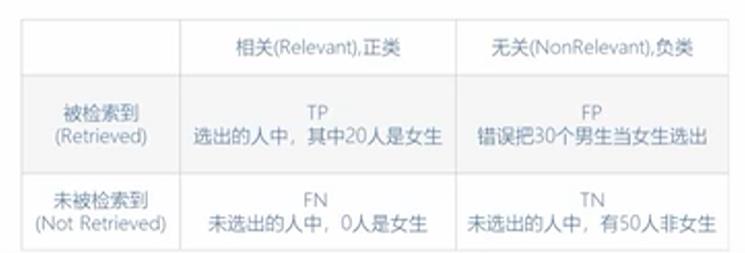
准确率是正确分类的item数与总数之比.
准确率:(20+50)/100=0.7
精确率是所有被检索到的item种,应该被检索到的比例
精确率:(20)/(20+30)=0.4
召回率是所有检索到的item中应该被检索到的比例
召回率:20/(20+0)=1
以上是关于推荐系统与推荐算法概念与简介的主要内容,如果未能解决你的问题,请参考以下文章