Kafk为什么这么快
Posted hxuhongming
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Kafk为什么这么快相关的知识,希望对你有一定的参考价值。
主要基于从kafka0.11.0版本开始之后的版本进行描述
1、批处理
传统消息中间件,一次只发送单挑消息;kafka,一次发送多条消息,微批处理。
生产者发送消息,需要2次rpc:
发送消息;
broker返回ACK信号,表示已经接收消息;
消费者消费消息,3次rpc:
消费者请求接收消息;
broker返回消息;
消费者返回ACK信号,表示已经消费
2、客户端优化
? 新版客户端摒弃单线程,采用双线程模式——主线程+Sender线程。
? 主线程负责将消息置入客户端缓存(缓存会将多个消息聚合为1个批次);Sender线程将缓存中聚合好的批次消息发送到Broker。
3、日志消息格式设计优良
新版本(从kafka 0.11.0版本开始)的日志消息格式,采用了变成字段Varints和ZigZag编码,有效降低了附加字段占用的空间,降低了网络传输、日志存盘占用开销。
4、消息压缩
? Kafka支持多种消息压缩方式(gzip、snappy、lz4)。对消息进行压缩可以极大地减少网络传输 量、降低网络 I/O,从而提高整体的性能。消息压缩是一种使用时间换空间的优化方式,如果对 时延有一定的要求,则不推荐对消息进行压缩。
5、分区
kafak对消息进行分区,提高了数据生产与消费的并行度,有效的提升了数据的吞吐量。
注:一昧地增加分区并不能一直带来性能的提升,详细参考[Kafka主题中的分区数越多吞吐量就越高](https://mp.weixin.qq.com/s?__biz=MzU0MzQ5MDA0Mw==&mid=2247484320&idx=1&sn=eee3caea1f28b180cf68d3469bb7d4f2&chksm=fb0be934cc7c6022cd2244ceb58b821d3fe0dc518eca1b29c4764f7d42cf2627a418bfbbf9f2&scene=21#wechat_redirect)
6、索引
kafka为每个日志分段文件提供了2个索引文件(偏移量索引文件.index、时间戳索引文件.timeindex),提高了消息的查询效率

7、顺序写盘
Kafka 在设计时采用了文件追加的方式来写入消息,即只能在日志文件的尾部追加新的消 息,并且也不允许修改已写入的消息,这种方式属于典型的顺序写盘的操作,而操作系统可以针对线性读写做深层次的优化,比如预读(read-ahead,提前将一个比较大的磁盘块读入内存) 和后写(write-behind,将很多小的逻辑写操作合并起来组成一个大的物理写操作)技术,所以就算 Kafka 使用磁盘作为存储介质,它所能承载的吞吐量也不容小觑。
8、页缓存
? Kafka 中大量使用了页缓存,这是 Kafka 实现高吞吐的重要因素之一。
? 页缓存是操作系统实现的一种主要的磁盘缓存,采用页缓存的主要优点:
(1)减少对磁盘 I/O 的操作(具体来说,就是把磁盘中的数据缓存到内存中,把对磁盘的访问变为对内存的访问)
(2)维护页缓存和文件之间的一致性交由操作系统来负责,比进程内维护更加安全有效
8、零拷贝
Kafka使用了Zero Copy技术提升了消费的效率。前面所说的Kafka将消息先写入页缓存,如果消费者在读取消息的时候如果在页缓存中可以命中,那么可以直接从页缓存中读取,这样又节省了一次从磁盘到页缓存的copy开销。
附录:
(1)磁盘IO流程图
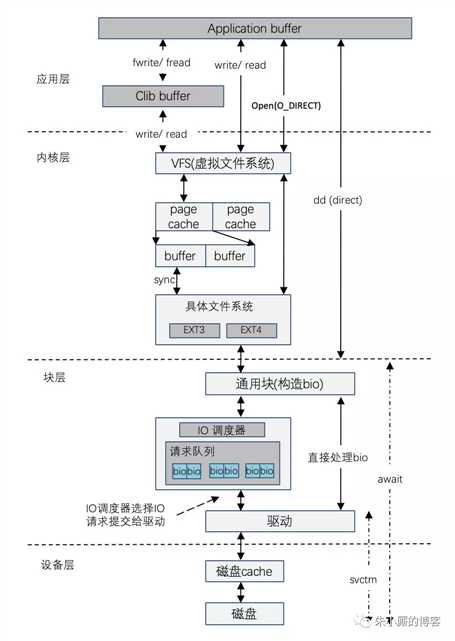
参考:
(1)https://mp.weixin.qq.com/s/G5nfLpPOr80pk1sHzrLuOA
以上是关于Kafk为什么这么快的主要内容,如果未能解决你的问题,请参考以下文章
JUC中的ForkJoin为什么这么快?基于jdk13的代码带你分析