ARM32 页表映射
Posted linhaostudy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ARM32 页表映射相关的知识,希望对你有一定的参考价值。
在32bit中的Linux内核中一般采用3层映射模型,第1层是页面目录(PGD),第2层是页面中间目录(PMD),第3层才是页面映射表(PTE)。但在ARM32系统中只用到两层映射,因此在实际代码中就要3层映射模型中合并一层。在ARM32架构中,可以按段(section)来映射,这时采用单层映射模式。使用页面映射需要两层映射结构,页面的选择可以是64KB的大页面或4KB的小页面,如图2.4所示。Linux内核通常使用4KB大小的小页面。
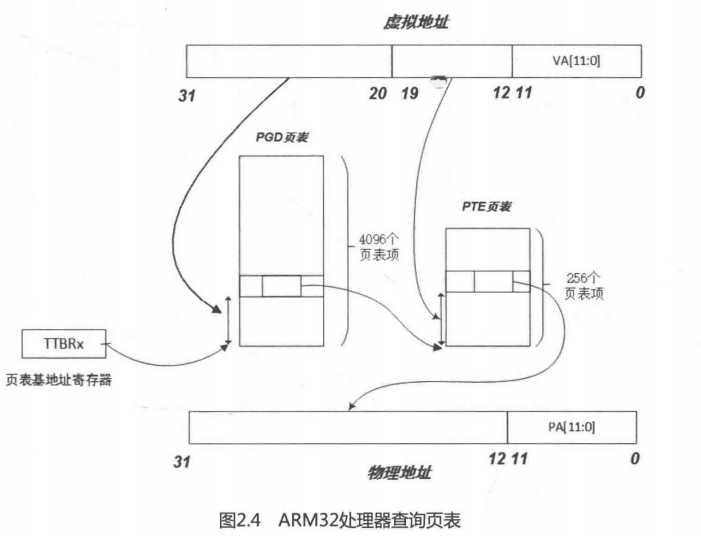
如果采用单层的段映射,内存中有一个段映射表,表中有4096个表项,每个表项的大小是4Byte,所以这个段映射表的大小是16KB,而且其位置必须与16KB边界对齐。每个段表项可以寻址1MB大小的地址空间。当CPU访问内存时,32位虚拟地址的高12位(bit[31:20])用作访问段映射表的索引,从表中找到相应的表项。每个表项提供了一个12位的物理段地址,以及相应的标志位,如可读、可写等标志位。将这个12bit的物理地址和虚拟地址的低20bit拼凑在一起,就得到32bit的物理地址;
如果使用页面映射的方式,段映射表就变成了一级映射表(First Level table,在linux内核中成为PGD),其表项提供的不再是物理段地址,而是二级页表的基地址。32bit虚拟地址的高12bit(bit[31:20])作为访问一级页表的索引值,找到相应的表项,每个表项指向一个二级页表。以虚拟地址的次8bit(bit[19:12])作为访问二级目录的索引值,得到相应的页表项,从这个页表项找到20位的物理页面地址。最后将这20bit的物理页面地址和虚拟地址的低12bit拼凑起来,得到最终的32bit物理地址。这个过程在ARM32架构中由MMU硬件完成,软件不需要介入;
[arch/arm/include/asm/pgtable-21level.h]
#define PMD_SHIFT 21
#define PGDIR_SHIFT 21
#define PMD_SIZE (1UL << PMD_SHIFT)
#define PMD_MASK (~(PMD_SIZE-1))
#define PGDIR_SIZE (1UL << PGDIR_SHIFT)
#define PGDIR_MASK (~(PGDIR_SIZE-1))
ARM32架构中一级页表PGD的偏移量应该从20bit开始,为何这里的头文件定义从21bit开始呢?
我们从ARM linux内核建立具体内存区间的页表映射过程中来看页表映射是如何实现的。crate_mapping()函数就是为一个给定内存区间建立页表映射,这个函数使用map_desc数据结构来描述一个内存区间。
struct map_desc {
unsigned long virtual; //虚拟地址的起始地址
unsigned long pfn; //物理地址的开始地址的页帧号
unsigned long length; //内存区间大小
unsigned int type;
}
其中,virtual表示这个区间的虚拟地址起始点,pfn表示起始物理地址的页帧号,length表示内存区间的长度,type表示内存区间的属性,通常有个struct mem_type[]数组来描述内存属性。struct mem_type数据结构描述内存区间类型以及相应的权限和属性等信息,其数据结构定义如下:
struct mem_type {
pteval_t prot_pte;
pteval_t prot_pte_s2;
pmdval_t prot_l1;
pmdval_t prot_sect;
unsigned int domain;
};
其中,domain成员用于ARM中定义的不同域,ARM中允许使用16个不同域,但在ARM Linux只定义和使用3个;
#define DOMAIN_KERNEL 2
#define DOMAIN_TABLE 2
#define DOMAIN_USER 1
#define DOMAIN_IO 0
DOMAIN_KERNEL和DOMAIN_TABLE其实用于系统空间,DOMAIN_IO用于I/O地址域,实际上也属于系统空间,DOMAIN_USER则是用户空间;
prot_pte成员用于页面表项的控制位和标志位,具体定义在:
#define L_PTE_VALID (_AT(pteval_t, 1) << 0)
#define L_PTE_PRESENT (_AT(pteval_t, 1) << 0)
#define L_PTE_YOUNG (_AT(pteval_t, 1) << 1)
#define L_PTE_DIRTY (_AT(pteval_t, 1) << 6)
#define L_PTE_RDONLY (_AT(pteval_t, 1) << 7)
#define L_PTE_USER (_AT(pteval_t, 1) << 8)
#define L_PTE_XN (_AT(pteval_t, 1) << 9)
#define L_PTE_SHARED (_AT(pteval_t, 1) << 10)
#define L_PTE_NONE (_AT(pteval_t, 1) << 11)
#define PROT_PTE_DEVICE L_PTE_PRESENT|L_PTE_YOUNG|L_PTE_DIRTY|L_PTE_XN
#define PROT_PTE_S2_DEVICE PROT_PTE_DEVICE
#define PROT_SECT_DEVICE PMD_TYPE_SECT|PMD_SECT_AP_WRITE
prot__l1用于一级页表项的控制位和标志位,具体定义如下:
/*
* Hardware page table definitions.
*
* + Level 1 descriptor (PMD)
* - common
*/
#define PMD_TYPE_MASK (_AT(pmdval_t, 3) << 0)
#define PMD_TYPE_FAULT (_AT(pmdval_t, 0) << 0)
#define PMD_TYPE_TABLE (_AT(pmdval_t, 1) << 0)
#define PMD_TYPE_SECT (_AT(pmdval_t, 2) << 0)
#define PMD_PXNTABLE (_AT(pmdval_t, 1) << 2) /* v7 */
#define PMD_BIT4 (_AT(pmdval_t, 1) << 4)
#define PMD_DOMAIN(x) (_AT(pmdval_t, (x)) << 5)
#define PMD_PROTECTION (_AT(pmdval_t, 1) << 9) /* v5 */
系统中定义了一个全局的mem_type[]数组来描述所有的内存区间类型。例如MT_DEVICE_CACHED、MT_DEVICE_WC、MT_MEMORY_RWX和MT_MEMORY_RW类型的内存区间的定义如下:
static struct mem_type mem_types[] = {
[MT_DEVICE] = { /* Strongly ordered / ARMv6 shared device */
.prot_pte = PROT_PTE_DEVICE | L_PTE_MT_DEV_SHARED |
L_PTE_SHARED,
.prot_pte_s2 = s2_policy(PROT_PTE_S2_DEVICE) |
s2_policy(L_PTE_S2_MT_DEV_SHARED) |
L_PTE_SHARED,
.prot_l1 = PMD_TYPE_TABLE,
.prot_sect = PROT_SECT_DEVICE | PMD_SECT_S,
.domain = DOMAIN_IO,
},
[MT_DEVICE_NONSHARED] = { /* ARMv6 non-shared device */
.prot_pte = PROT_PTE_DEVICE | L_PTE_MT_DEV_NONSHARED,
.prot_l1 = PMD_TYPE_TABLE,
.prot_sect = PROT_SECT_DEVICE,
.domain = DOMAIN_IO,
},
[MT_DEVICE_CACHED] = { /* ioremap_cached */
.prot_pte = PROT_PTE_DEVICE | L_PTE_MT_DEV_CACHED,
.prot_l1 = PMD_TYPE_TABLE,
.prot_sect = PROT_SECT_DEVICE | PMD_SECT_WB,
.domain = DOMAIN_IO,
},
[MT_DEVICE_WC] = { /* ioremap_wc */
.prot_pte = PROT_PTE_DEVICE | L_PTE_MT_DEV_WC,
.prot_l1 = PMD_TYPE_TABLE,
.prot_sect = PROT_SECT_DEVICE,
.domain = DOMAIN_IO,
},
[MT_UNCACHED] = {
.prot_pte = PROT_PTE_DEVICE,
.prot_l1 = PMD_TYPE_TABLE,
.prot_sect = PMD_TYPE_SECT | PMD_SECT_XN,
.domain = DOMAIN_IO,
},
[MT_CACHECLEAN] = {
.prot_sect = PMD_TYPE_SECT | PMD_SECT_XN,
.domain = DOMAIN_KERNEL,
},
#ifndef CONFIG_ARM_LPAE
[MT_MINICLEAN] = {
.prot_sect = PMD_TYPE_SECT | PMD_SECT_XN | PMD_SECT_MINICACHE,
.domain = DOMAIN_KERNEL,
},
#endif
[MT_LOW_VECTORS] = {
.prot_pte = L_PTE_PRESENT | L_PTE_YOUNG | L_PTE_DIRTY |
L_PTE_RDONLY,
.prot_l1 = PMD_TYPE_TABLE,
.domain = DOMAIN_USER,
},
[MT_HIGH_VECTORS] = {
.prot_pte = L_PTE_PRESENT | L_PTE_YOUNG | L_PTE_DIRTY |
L_PTE_USER | L_PTE_RDONLY,
.prot_l1 = PMD_TYPE_TABLE,
.domain = DOMAIN_USER,
},
[MT_MEMORY_RWX] = {
.prot_pte = L_PTE_PRESENT | L_PTE_YOUNG | L_PTE_DIRTY,
.prot_l1 = PMD_TYPE_TABLE,
.prot_sect = PMD_TYPE_SECT | PMD_SECT_AP_WRITE,
.domain = DOMAIN_KERNEL,
},
[MT_MEMORY_RW] = {
.prot_pte = L_PTE_PRESENT | L_PTE_YOUNG | L_PTE_DIRTY |
L_PTE_XN,
.prot_l1 = PMD_TYPE_TABLE,
.prot_sect = PMD_TYPE_SECT | PMD_SECT_AP_WRITE,
.domain = DOMAIN_KERNEL,
},
[MT_ROM] = {
.prot_sect = PMD_TYPE_SECT,
.domain = DOMAIN_KERNEL,
},
[MT_MEMORY_RWX_NONCACHED] = {
.prot_pte = L_PTE_PRESENT | L_PTE_YOUNG | L_PTE_DIRTY |
L_PTE_MT_BUFFERABLE,
.prot_l1 = PMD_TYPE_TABLE,
.prot_sect = PMD_TYPE_SECT | PMD_SECT_AP_WRITE,
.domain = DOMAIN_KERNEL,
},
[MT_MEMORY_RW_DTCM] = {
.prot_pte = L_PTE_PRESENT | L_PTE_YOUNG | L_PTE_DIRTY |
L_PTE_XN,
.prot_l1 = PMD_TYPE_TABLE,
.prot_sect = PMD_TYPE_SECT | PMD_SECT_XN,
.domain = DOMAIN_KERNEL,
},
[MT_MEMORY_RWX_ITCM] = {
.prot_pte = L_PTE_PRESENT | L_PTE_YOUNG | L_PTE_DIRTY,
.prot_l1 = PMD_TYPE_TABLE,
.domain = DOMAIN_KERNEL,
},
[MT_MEMORY_RW_SO] = {
.prot_pte = L_PTE_PRESENT | L_PTE_YOUNG | L_PTE_DIRTY |
L_PTE_MT_UNCACHED | L_PTE_XN,
.prot_l1 = PMD_TYPE_TABLE,
.prot_sect = PMD_TYPE_SECT | PMD_SECT_AP_WRITE | PMD_SECT_S |
PMD_SECT_UNCACHED | PMD_SECT_XN,
.domain = DOMAIN_KERNEL,
},
[MT_MEMORY_DMA_READY] = {
.prot_pte = L_PTE_PRESENT | L_PTE_YOUNG | L_PTE_DIRTY |
L_PTE_XN,
.prot_l1 = PMD_TYPE_TABLE,
.domain = DOMAIN_KERNEL,
},
};
这样一个map_desc数据结构就完整描述了一个内存区间,调用create_mapping()时以此数据结构指针为调用参数;
start_kernel() -->
setup_arch() -->
paging_init() -->
map_lowmem() -->
create_mapping()
/*
* Create the page directory entries and any necessary
* page tables for the mapping specified by `md‘. We
* are able to cope here with varying sizes and address
* offsets, and we take full advantage of sections and
* supersections.
*/
static void __init create_mapping(struct map_desc *md)
{
unsigned long addr, length, end;
phys_addr_t phys;
const struct mem_type *type;
pgd_t *pgd;
if (md->virtual != vectors_base() && md->virtual < TASK_SIZE) {
pr_warn("BUG: not creating mapping for 0x%08llx at 0x%08lx in user region
",
(long long)__pfn_to_phys((u64)md->pfn), md->virtual);
return;
}
if ((md->type == MT_DEVICE || md->type == MT_ROM) &&
md->virtual >= PAGE_OFFSET &&
(md->virtual < VMALLOC_START || md->virtual >= VMALLOC_END)) {
pr_warn("BUG: mapping for 0x%08llx at 0x%08lx out of vmalloc space
",
(long long)__pfn_to_phys((u64)md->pfn), md->virtual);
}
type = &mem_types[md->type];
#ifndef CONFIG_ARM_LPAE
/*
* Catch 36-bit addresses
*/
if (md->pfn >= 0x100000) {
create_36bit_mapping(md, type);
return;
}
#endif
addr = md->virtual & PAGE_MASK;
phys = __pfn_to_phys(md->pfn);
length = PAGE_ALIGN(md->length + (md->virtual & ~PAGE_MASK));
if (type->prot_l1 == 0 && ((addr | phys | length) & ~SECTION_MASK)) {
pr_warn("BUG: map for 0x%08llx at 0x%08lx can not be mapped using pages, ignoring.
",
(long long)__pfn_to_phys(md->pfn), addr);
return;
}
pgd = pgd_offset_k(addr);
end = addr + length;
do {
unsigned long next = pgd_addr_end(addr, end);
alloc_init_pud(pgd, addr, next, phys, type);
phys += next - addr;
addr = next;
} while (pgd++, addr != end);
}
这个函数的入参是一个结构体为map_desc叫 md 的东东,这个玩意用来表征一个映射关系的结构;
在create_mapping()函数中,以PGDIR_SIZE为单位,在内存区域[virtual, virtual+length]中通过调用alloc_init_pud()来初始化PGD页表项内容和下一级页表PUD。pgd_addr_end()以PGDIR_SIZE为步长;
在第7行代码中,通过md->type来获取描述内存区域属性的mem_type数据结构,这里只需要通过查表的方式来获取mem_type数据结构里的具体内容;
在第13行代码中,通过pgd_offset_k()函数获取所属的页面目录项PGD。内核页表存放在
swapper_pg_dir地址中,可以通过init_mm数据结构来获取;
struct mm_struct init_mm = {
.mm_rb = RB_ROOT,
.pgd = swapper_pg_dir,
.mm_users = ATOMIC_INIT(2),
.mm_count = ATOMIC_INIT(1),
.mmap_sem = __RWSEM_INITIALIZER(init_mm.mmap_sem),
.page_table_lock = __SPIN_LOCK_UNLOCKED(init_mm.page_table_lock),
.mmlist = LIST_HEAD_INIT(init_mm.mmlist),
INIT_MM_CONTEXT(init_mm)
};
内核页表的基地址定义在arch/arm/kernel/head.S汇编代码中。
[arch/arm/kernel/head.S]
#define KERNEL_RAM_VADDR (PAGE_OFFSET+TEXT_OFFSET)
#define PG_DIR_SIZE 0x4000
.globl swapper_pg_dir
.equ swapper_pg_dir, KERNEL_RAM_VADDR - PG_DIR_SIZE
[arch/arm/Makefile]
textofs-y := 0x00008000
TEXT_OFFSET := $(textofs-y)
从上面的代码中,可以推算出页表的基地址是0xc0004000;
pgd_offset_k()宏可以从init_mm数据结构所指定的页面目录中找到地址addr所属的页面目录项指针pgd。首先通过init_mm结构体得到页表的基地址,然后通过addr右移PGDIR_SHIFT得到pgd的索引值,最后在一级页表中找到页表项pgd指针。pgd_offset_k()宏定义如下:
#define PGDIR_SHIFT 21
#define pgd_index(addr) ((addr) >> PGDIR_SHIFT)
#define pgd_offset(mm, addr) ((mm)->pgd + pgd_index(addr))
#define pgd_offset_k(addr) pgd_offset(&init_mm, addr)
create_mapping()函数中的第15-22行代码,由于ARM Vexpress平台支持两级页表映射,所以PUD和PMD设置成与PGD等同了。
#define pud_offset(dir,addr) ((pud_t *) pgd_page_vaddr(*(dir)) + (((addr) >> PUD_SHIFT) & (PTRS_PER_PUD - 1)))
#endif
/* Find an entry in the third-level page table.. */
#define pmd_offset(dir,addr) ((pmd_t *) pud_page_vaddr(*(dir)) + (((addr) >> PMD_SHIFT) & (PTRS_PER_PMD - 1)))
因此,alloc_init_pud()函数一路调用到alloc_init_pte()函数。
static void __init alloc_init_pte(pmd_t *pmd, unsigned long addr,
unsigned long end, unsigned long pfn,
const struct mem_type *type)
{
pte_t *pte = early_pte_alloc(pmd, addr, type->prot_l1);
do {
set_pte_ext(pte, pfn_pte(pfn, __pgprot(type->prot_pte)), 0);
pfn++;
} while (pte++, addr += PAGE_SIZE, addr != end);
}
alloc_init_pte()首先判断相应的PTE页表项是否已经存在,如果不存在,那就要新建PTE页表项。接下来的while循环是根据物理地址的pfn页帧号来生成新的PTE表项(PTE entry),最后设置到ARM硬件页表中。
create_mapping ->
alloc_init_pud ->
alloc_init_pmd ->
alloc_init_pte ->
early_pte_alloc
static pte_t * __init early_pte_alloc(pmd_t *pmd, unsigned long addr, unsigned long prot)
{
if (pmd_none(*pmd)) {
pte_t *pte = early_alloc(PTE_HWTABLE_OFF + PTE_HWTABLE_SIZE);
__pmd_populate(pmd, __pa(pte), prot);
}
BUG_ON(pmd_bad(*pmd));
return pte_offset_kernel(pmd, addr);
}
pmd_none()检查这个参数的对应的PMD表项的内容,如果为0,说明这个页表PTE还没建立,所以要先去建立页面表。这里会去分配(PTE_HWTABLE_OFF+PTE_HWTABLE_SIZE)个PTE页面表项,即会分配512+512个PTE页表项。但是在ARM32架构中,二级页表也只有256个页面表项,为何要分配那么多呢?
#define PTRS_PER_PTE 512
#define PTRS_PER_PMD 1
#define PTRS_PER_PGD 2048
#define PTE_HWTABLE_PTRS (PTRS_PER_PTE)
#define PTE_HWTABLE_OFF (PTE_HWTABLE_PTRS * sizoef(pte_t))
#define PTE_HWTABLE_SIZE (PTRS_PER_PTE * sizoof(u32))
先回答刚才的问题:ARM架构中一级页表的PGD的偏移量应该从20位开始,为何这里的头文件定义从21位开始呢?
-
这里分配了两个PTRS_PER_PTE(512)个页面表项,也就是分配了两份页面表项。因为Linux内核默认的PGD从21位开始,也就是bit[31:21],一共2048个一级页表项;而ARM32硬件结构上,PGD是从20bit开始的,页表项为4096个,比Linux内核多一倍,那么代码实现上取巧了,以PTE_HWTABLE_OFF为偏移来写PGD表项。而在真实硬件中,一个PGD页表项,只有256个PTE,也就是说,前512个PTE页表项是给OS用的(也就是Linux内核用的页表,可以用于模拟L_PTE_DIRTY、L_PTE_YOUNG等标志位),后512个页面表是给ARM硬件MMU使用的;
-
一次映射两个相邻的一级页表项,也就是对应的两个相邻的二级页表都存放在一个page中;
然后把这个PTE页面表的基地址通过__pmd_populate()函数设置到PMD页表项中;
static inline void __pmd_populate(pmd_t *pmdp, phys_addr_t pte,
pmdval_t prot)
{
pmdval_t pmdval = (pte + PTE_HWTABLE_OFF) | prot;
pmdp[0] = __pmd(pmdval);
#ifndef CONFIG_ARM_LPAE
pmdp[1] = __pmd(pmdval + 256 * sizeof(pte_t));
#endif
flush_pmd_entry(pmdp);
}
注意这里是把刚分配的1024个PTE页面表中的第512个页表项的地址作为基地址,再加上一些标志位信息prot作为页表项内容,写入上一级页表项PMD中。
相邻的两个二级页表的基地址分别写入PMD的页表项中的pmdp[0]和pmdp[1]指针中。
typedef struct (pmdval_t pgd(2))
/* to find an entry in a page-table-directory */
#define pgd_index(addr) ((addr) >> PGDIR_SHIFT)
#define pgd_offset(mm, addr) ((mm)->pgd + pgd_index(addr))
PGD的定义其实是pmdval_t pgd[2],长度是两倍,也就是pgd包括两份相邻的PTE页表。所以pgd_offset()在查找pgd表项时,是按照pgd[2]长度来进行计算的,因此查找相应的pgd表项时,其中pgd[0]指向第一份PTE页表,pgd[1]指向第二份PTE页表;
pte_offset_kernel()函数返回相应的PTE页表表项,然后通过__pgprot()和pfn组成PTE entry,最后由set_pte_ext()完成对硬件页表项的设置;
static void __init alloc_init_pte(pmd_t *pmd, unsigned long addr,
unsigned long end, unsigned long pfn,
const struct mem_type *type)
{
pte_t *pte = early_pte_alloc(pmd, addr, type->prot_l1);
do {
set_pte_ext(pte, pfn_pte(pfn, __pgprot(type->prot_pte)), 0);
pfn++;
} while (pte++, addr += PAGE_SIZE, addr != end);
}
set_pte_ext()对于不同的CPU有不同的实现。对于基于ARMv7-A架构的处理器,例如Contex-A9,它的实现是在汇编函数cpu_v7_set_pte_ext中:
ENTRY(cpu_v7_set_pte_ext)
#ifdef CONFIG_MMU
str r1, [r0] @ linux version
bic r3, r1, #0x000003f0
bic r3, r3, #PTE_TYPE_MASK
orr r3, r3, r2
orr r3, r3, #PTE_EXT_AP0 | 2
tst r1, #1 << 4
orrne r3, r3, #PTE_EXT_TEX(1)
eor r1, r1, #L_PTE_DIRTY
tst r1, #L_PTE_RDONLY | L_PTE_DIRTY
orrne r3, r3, #PTE_EXT_APX
tst r1, #L_PTE_USER
orrne r3, r3, #PTE_EXT_AP1
tst r1, #L_PTE_XN
orrne r3, r3, #PTE_EXT_XN
tst r1, #L_PTE_YOUNG
tstne r1, #L_PTE_VALID
eorne r1, r1, #L_PTE_NONE
tstne r1, #L_PTE_NONE
moveq r3, #0
ARM( str r3, [r0, #2048]! )
THUMB( add r0, r0, #2048 )
THUMB( str r3, [r0] )
ALT_SMP(W(nop))
ALT_UP (mcr p15, 0, r0, c7, c10, 1) @ flush_pte
#endif
bx lr
ENDPROC(cpu_v7_set_pte_ext)
cpu_v7_set_pte_ext()函数参数r0表示PTE entry页表项的指针,注意ARM Linux中实现了两份页表,硬件页表的地址r0+2048。因此r0指Linux版本的页面表地址,r1表示要写入的Linux版本的PTE页面表项内容,这里指Linux版本的页面表项内容,而非硬件版本的页面表项内容。该函数的主要目的是根据Linux版本的页面表项内容来填充ARM硬件版本的页表项;
首先把linux内核版本的页表项内容写入linux版本的页表中,然后根据mem_type数据结构prot_pte的标志位来设置ARMV7-A硬件相关标志位。prot_pte的标志位是linux内核中采用的,定义在arch/arm/include/asm/pgtable-2level.h头文件。而硬件相关的标志位定义在arch/arm/include/asm/pgtable-2level-hwdef.h头文件。这两个标志位对应的偏移是不一样的,所以不同架构下的处理器需要单独处理。ARM32架构硬件PTE页面表定义的标志位如下:
/*
* - extended small page/tiny page
*/
#define PTE_EXT_XN (_AT(pteval_t, 1) << 0) /* v6 */
#define PTE_EXT_AP_MASK (_AT(pteval_t, 3) << 4)
#define PTE_EXT_AP0 (_AT(pteval_t, 1) << 4)
#define PTE_EXT_AP1 (_AT(pteval_t, 2) << 4)
#define PTE_EXT_AP_UNO_SRO (_AT(pteval_t, 0) << 4)
#define PTE_EXT_AP_UNO_SRW (PTE_EXT_AP0)
#define PTE_EXT_AP_URO_SRW (PTE_EXT_AP1)
#define PTE_EXT_AP_URW_SRW (PTE_EXT_AP1|PTE_EXT_AP0)
#define PTE_EXT_TEX(x) (_AT(pteval_t, (x)) << 6) /* v5 */
#define PTE_EXT_APX (_AT(pteval_t, 1) << 9) /* v6 */
#define PTE_EXT_COHERENT (_AT(pteval_t, 1) << 9) /* XScale3 */
#define PTE_EXT_SHARED (_AT(pteval_t, 1) << 10) /* v6 */
#define PTE_EXT_NG (_AT(pteval_t, 1) << 11) /* v6 */
linux内核定义的PTE页面表相关的软件标志位如下:
/*
* "Linux" PTE definitions.
*
* We keep two sets of PTEs - the hardware and the linux version.
* This allows greater flexibility in the way we map the Linux bits
* onto the hardware tables, and allows us to have YOUNG and DIRTY
* bits.
*
* The PTE table pointer refers to the hardware entries; the "Linux"
* entries are stored 1024 bytes below.
*/
#define L_PTE_VALID (_AT(pteval_t, 1) << 0) /* Valid */
#define L_PTE_PRESENT (_AT(pteval_t, 1) << 0)
#define L_PTE_YOUNG (_AT(pteval_t, 1) << 1)
#define L_PTE_DIRTY (_AT(pteval_t, 1) << 6)
#define L_PTE_RDONLY (_AT(pteval_t, 1) << 7)
#define L_PTE_USER (_AT(pteval_t, 1) << 8)
#define L_PTE_XN (_AT(pteval_t, 1) << 9)
#define L_PTE_SHARED (_AT(pteval_t, 1) << 10) /* shared(v6), coherent(xsc3) */
#define L_PTE_NONE (_AT(pteval_t, 1) << 11)
第9~10行代码设置ARM硬件页表的PTE_EXT_TEX比特位;
第13~15行代码设置ARM硬件页表的PTE_EXT_APX比特位;
第17~18行代码设置ARM硬件页表的PTE_EXT_AP1比特位;
第20~21行代码设置ARM硬件页表的PTE_EXT_XN比特位;
第23~27行代码,在旧版本中的linux内核代码中(例如linux3.7),等同如下代码片段:
tst r1, #L_PTE_YOUNG
tstne r1, #L_PTE_PRESENT
moveq r3, #0
如果没有设置L_PTE_YOUNG并且L_PTE_PRESENT置位,那就保持Linux版本的页表不变,把ARM32硬件版本的页表表项内容清零。代码中的L_PTE_VAILD和L_PTE_NONE这两个软件比特位是后来添加的,因此在linux3.7及以前内核版本中更加容易理解;
为什么这里要把ARM硬件版本的页面表项内容清零呢?我们观察ARM32硬件版本的页面表的相关标志位会发现,没有表示被访问和页面在内存中的硬件标志位。linux内核最早基于x86体系结构设计的,所以linux内核关于页表的许多术语和设计都是针对x86体系的,而ARM Linux只能从软件架构上去跟随了,因此设计了两套页表。在x86的页表中有3个标志位是ARM32硬件页面表没有提供的。
- PTE_DIRTY: CPU是写操作时会设置该标志位,表示该页表被写过,为脏页;
- PTE_YOUNG: CPU访问该页时会设置该标志位,在页面换出的时候,如果该标志位置位了,说明该页刚被访问过,页面是young的,不适合把该页换出,同事清除该标志位;
- PTE_PRESENT:表示该页在内存中;
因此在ARM Linux中实现中需要模拟上述3个比特位;
如何模拟PTE_DIRTY呢?在ARM MMU硬件中为一个干净页面建立映射时,设置硬件页表项是只读权限的。当往一个干净页表写入时,会触发写权限缺页中断(虽然linux版本的页面表项标记了可写权限,但是ARM硬件页面表项还不具有写入权限),那么在缺页中断处理handle_pte_falut()会在该页的linux版本中PTE页面表项标记为"dirty",并且发现PTE页表项内容改变了,ptep_set_access_flags()函数会把新的linux版本的页表项内容写入硬件页表,从而实现模拟过程;
以上是关于ARM32 页表映射的主要内容,如果未能解决你的问题,请参考以下文章