ARM64 Linux 内核页表的块映射
Posted CSDN
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ARM64 Linux 内核页表的块映射相关的知识,希望对你有一定的参考价值。
内核文档 Documentation/arm64/memory.rst 描述了 ARM64 Linux 内核空间的内存映射情况,应该是此方面最权威文档。

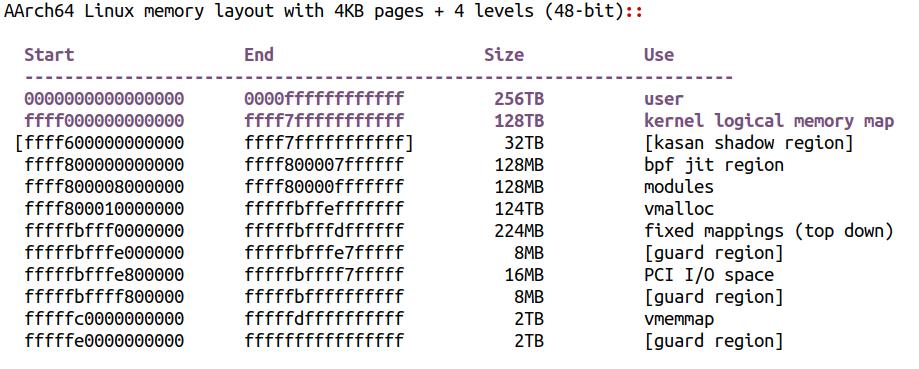
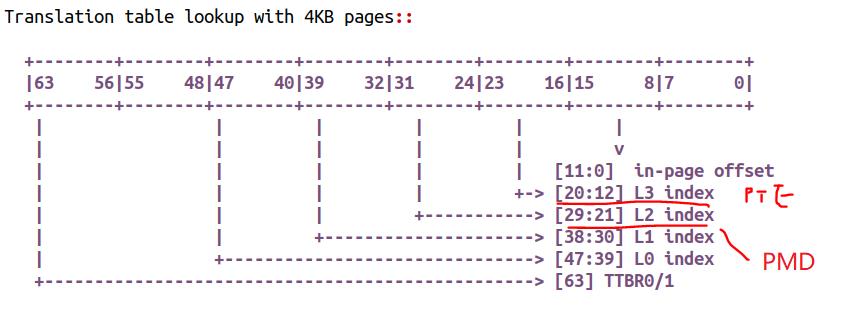
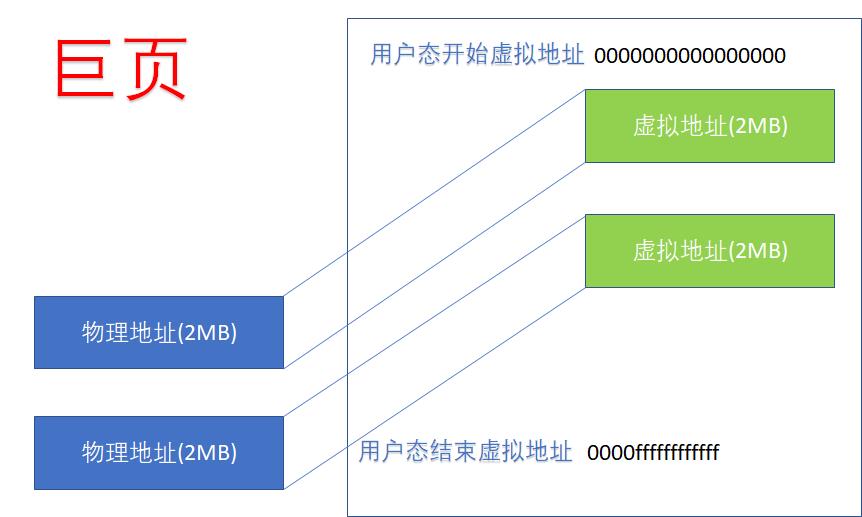
但是,这不意味着它们就是 Huge Page。
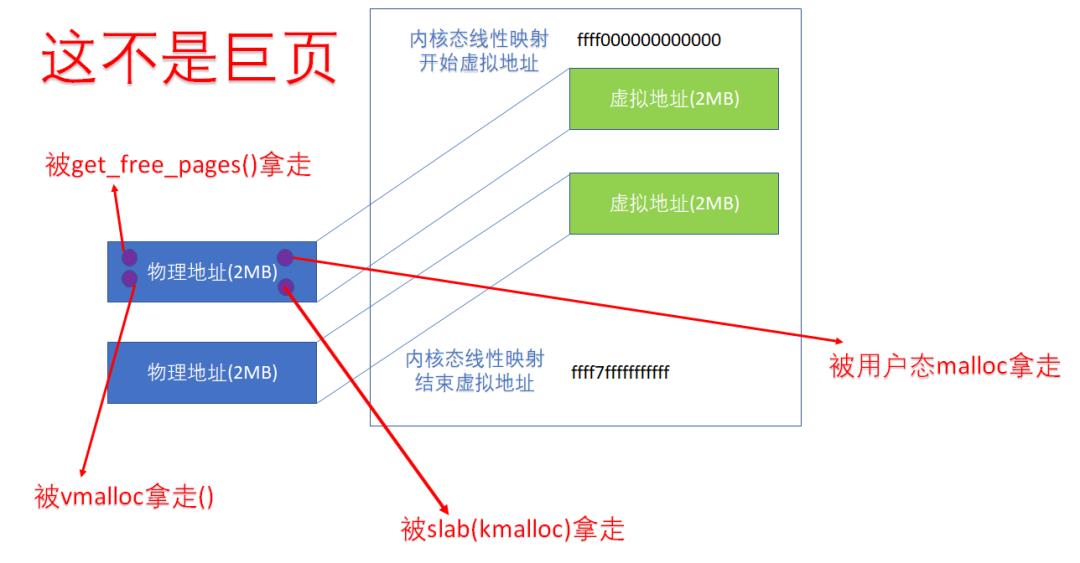
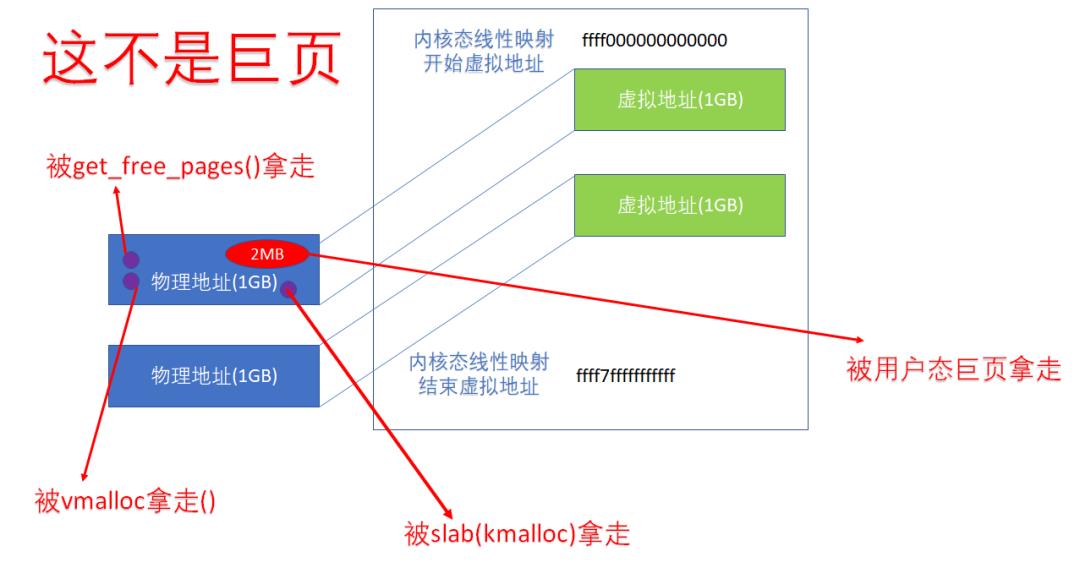
所以,即便我们在内核空间进行 PMD 映射,里面的每个蓝色圆圈(一个 4K页),还是可以被单独分配的,这种分配可以是 kmalloc、vmalloc,用户态的 malloc 等。
内核态进行的 PMD 映射,不意味着相关的 2MB 成为了 huge page。
当然,更牛的情况下,内核应该也可以直接用【38:30】位的 PUD 来进行映射,这样映射关系是 1GB 的,则整个 1GB 后面占 TLB 的时候,只需要占一个入口。
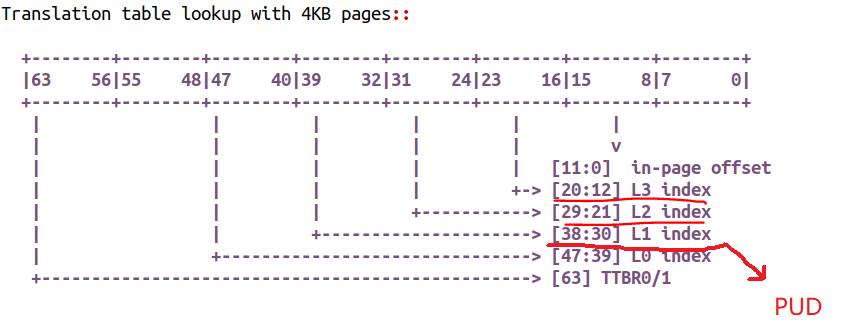
当然,如果用户态的虚实映射是这样的,用户实际得到了一个 1GB 的巨页。
但是对于内核的线性映射区域而言,即便我们进行了 1GB 的 PUD 映射,这 1G 内部就可以进一步切割为 4KB 页或者 2MB 的巨页。
记住:内核态的线性映射区的映射只是个映射关系,不是个分配关系。比如下面的 1GB 的内核线性映射的 1GB 区域,仍然可以被 4K 分配走,或者被用户以 huge page 以 2MB 为单位分配走:
我们需要一个真实的调试手段来验证我们的想法,这个调试手段就是 PTDUMP(Page Table Dump),相关的代码在 ARM64 内核的:
arch/arm64/mm/ptdump.c和ptdump_debugfs.c
我们把它们全部选中,这样我们可以得到一个 debugfs 接口:
/sys/kernel/debug/kernel_page_tables
来获知内核态页表的情况。
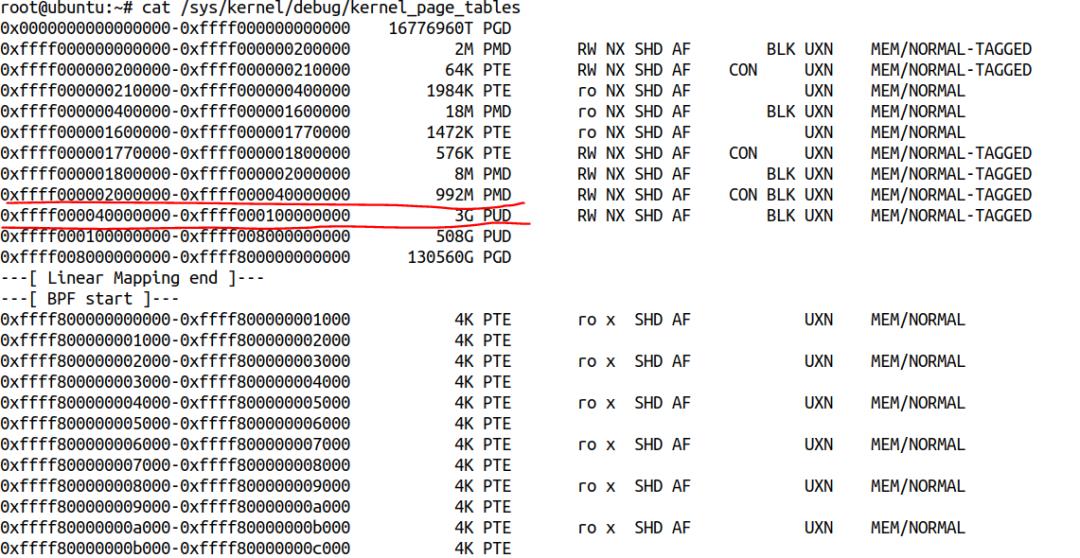
我的内核启动参数加了 rodata=0:
$ cat /proc/cmdlineroot=/dev/vda2 rw console=ttyAMA0 ip=dhcp rodata=0
原因是内核在几种情况下,是不会做这种 PMD 和 PUD 映射的,相关代码见于:
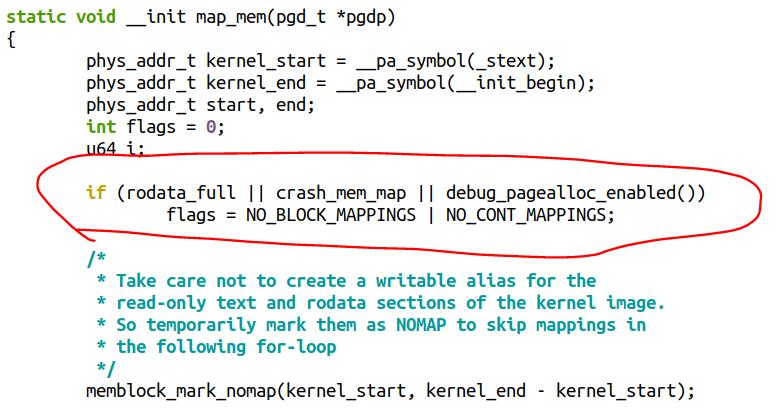
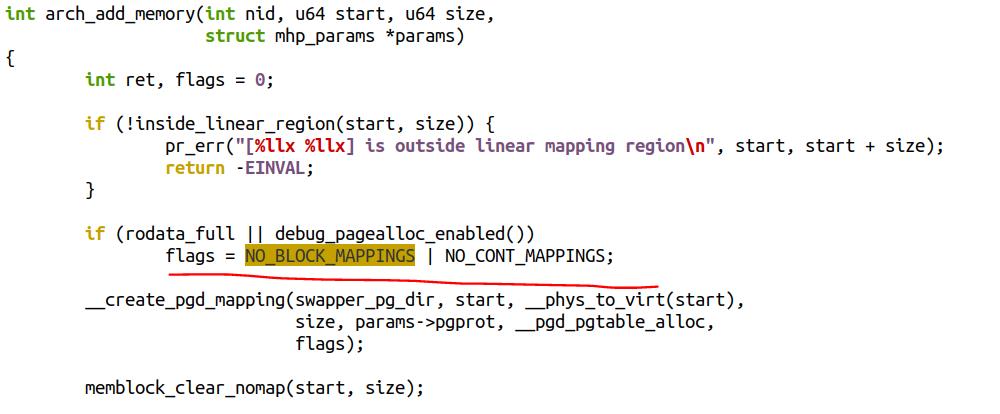
rodata_full 在默认情况下总是成立的,它对应着内核的一个 Config 选项 CONFIG_RODATA_FULL_DEFAULT_ENABLED, "Apply r/o permissions of VM areas also to their linear aliases",这个选项提高了内核的安全性,但是减小了内核的性能。

我在内核启动参数加的 rodata=0 实际上是让 rodata_full 为 false。
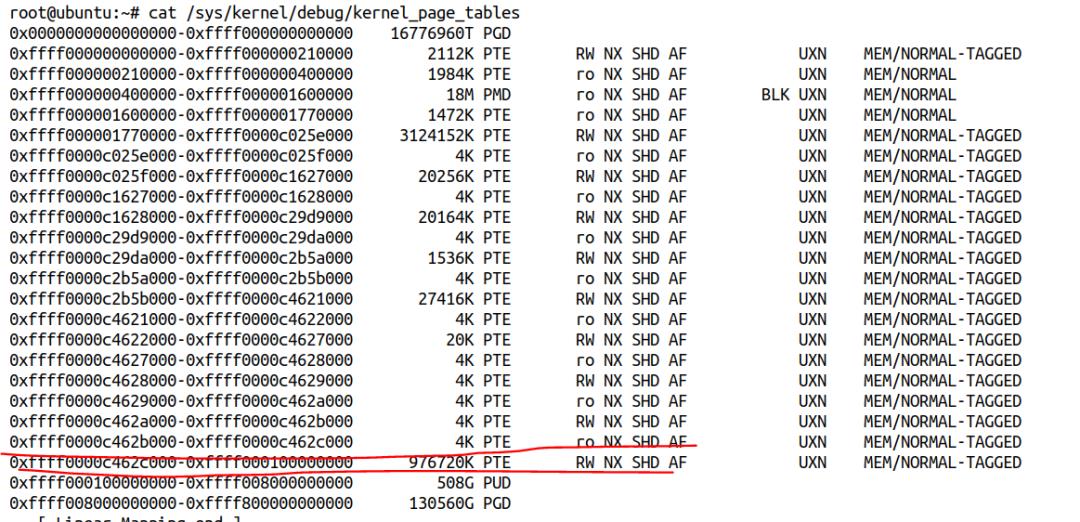
如果我把这个 kernel 启动选项去掉,我得到的内核页表是完全不一样,线性映射区也全部是 PTE 映射:
最后,值得一提的是,不仅线性映射区可以使用 PMD 映射,vmemmap 映射区也是在 4K 页面情况下,默认用 PMD 映射的:

字节跳动的宋牧春童鞋发了一个 patchset,企图在用户分得巨页的情况下,删除巨页内部的 4KB 的小 page 占用的 page struct 的内存消耗,这个 patchset 在圣诞节前目前发到了 V11:
https://lore.kernel.org/linux-mm/20201222142440.28930-1-songmuchun@bytedance.com/

在这个 patchset 中,它就需要拆分 vmemmap 的 PMD 映射为 PTE 映射:
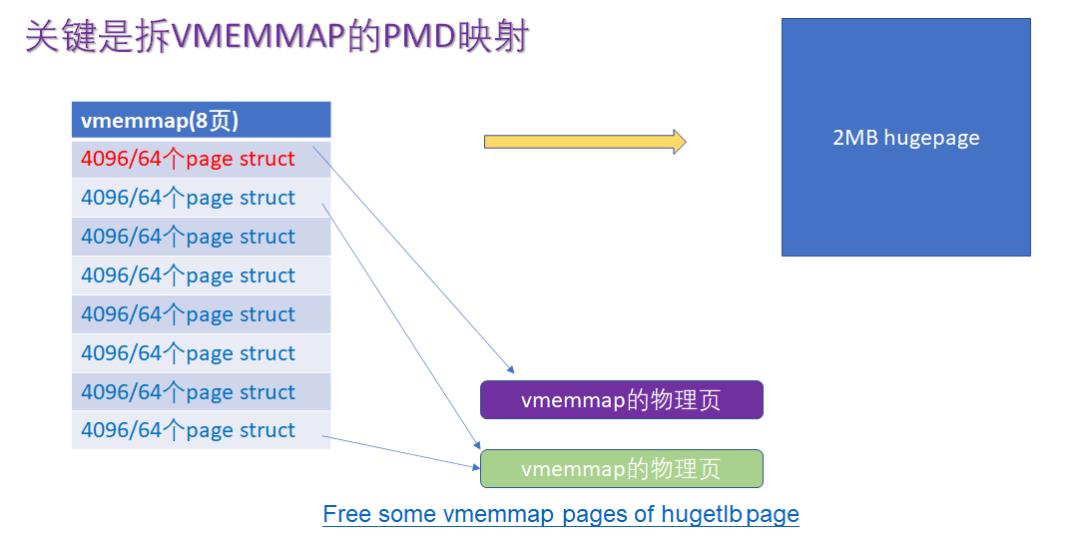
这个 patchset 的原理建立在,当内核以 4KB 分页的时候,每个 page 需要 64 字节的 page struct。
但是,当用户把它分配为巨页的时候,我们不再需要一个个 4KB 单独用 page struct 描述,对于这种 compound page 的情况,我们应该可以把后面的 page struct 的内存直接释放掉,因为情况完全是雷同的,这样可以省下不少内存。
看到牧春童鞋从一个青葱少年成长为这方面的大牛,我真的替他高兴和骄傲。这同时也激励我必须保持奋斗姿态,2021 年要不停歇地学习进步,争取赶上牧春童鞋。

程序员如何避免陷入“内卷”、选择什么技术最有前景,中国开发者现状与技术趋势究竟是什么样?快来参与「2020 中国开发者大调查」,更有丰富奖品送不停!

更多精彩推荐 nux5.10.5 发布 | 极客头条

点 分 享 
点 收 藏 点 点 赞 点 在看
以上是关于ARM64 Linux 内核页表的块映射的主要内容,如果未能解决你的问题,请参考以下文章