对传入的数据进行分类
Posted hany-postq473111315
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了对传入的数据进行分类相关的知识,希望对你有一定的参考价值。
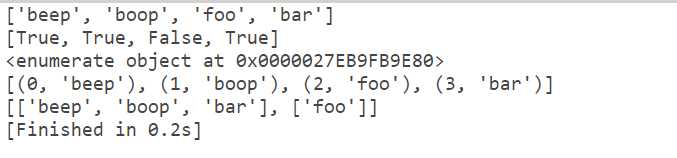
def bifurcate(lst, filter): print(lst) # [‘beep‘, ‘boop‘, ‘foo‘, ‘bar‘] print(filter) # [True, True, False, True] # 列表名,不是 filter 函数 print(enumerate(lst)) # <enumerate object at 0x0000017EB10B9D00> print(list(enumerate(lst))) # [(0, ‘beep‘), (1, ‘boop‘), (2, ‘foo‘), (3, ‘bar‘)] print([ [x for i, x in enumerate(lst) if filter[i] == True], [x for i, x in enumerate(lst) if filter[i] == False] ]) ‘‘‘ filter[i] 主要是对枚举类型前面的索引和传入的 filter 列表进行判断是否重复 ‘‘‘ bifurcate([‘beep‘, ‘boop‘, ‘foo‘, ‘bar‘], [True, True, False, True])
以上是关于对传入的数据进行分类的主要内容,如果未能解决你的问题,请参考以下文章
pyspark databricks 代码对传入文件进行零字节检查