pandas GroupBy上的方法apply:一般性的“拆分-应用-合并”
Posted 朴素贝叶斯
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了pandas GroupBy上的方法apply:一般性的“拆分-应用-合并”相关的知识,希望对你有一定的参考价值。
方法定义
最一般化的GroupBy方法是apply,apply会将待处理的对象拆分成多个片段,然后对各片段调用传入的函数,最后尝试将各片段组合到一起。
代码示例
我们使用的数据集为利用python进行数据分析中的小费数据集,
tips_df.head()
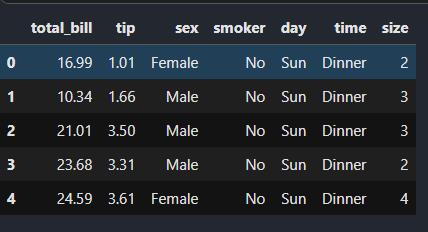
首先定义一个函数,在指定列找出最大值,然后把这个值所在的行选取出来。
def top(df,n=5,column=\'tip\'):
return df.sort_values(by=column)[-n:]
这里df是拆分的每一个小片段,函数的第一个参数必须是拆分的每一个小片段,这里的n=5,column=\'tip\'是我们如果需要的话,传入的参数。
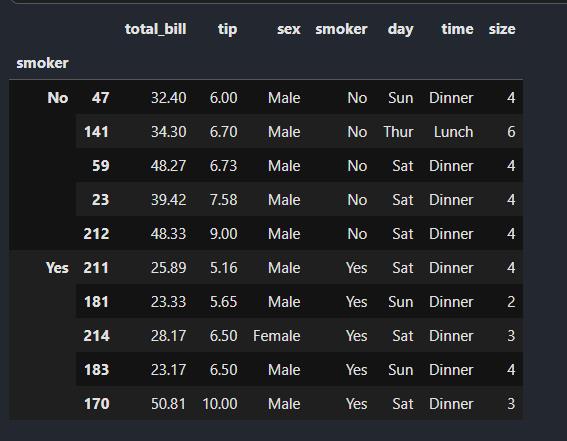
现在,我们进行操作:tips_df.groupby(\'smoker\').apply(top)
输出的结果为:
如果传给apply的函数能够接受其他参数或关键字,则可以将这些内容放在函数名后面一并传入:
tips_df.groupby([\'smoker\',\'day\']).apply(top,n=1,column=\'total_bill\')
输出结果为:
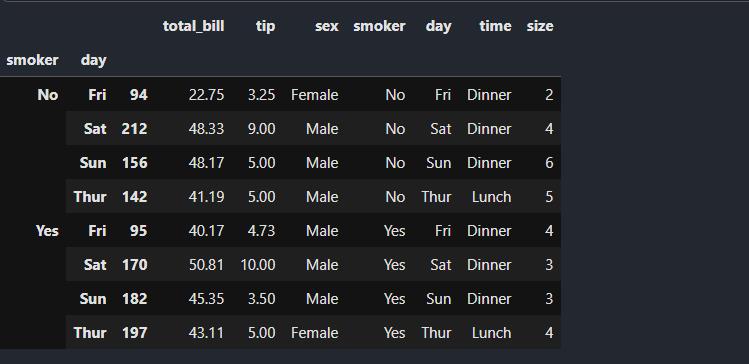
上面的代码例子发生了什么?top函数在DataFrame的各个片段上调用,然后结果由pandas.concat组装到一起,并以分组名称进行了标记。于是,最终结果有了一个层次化索引,其内层索引值来自原DataFrame.
之前当我们在GroupBy对象上调用describe()方法时:
result = tips.groupby(\'smoker\')[\'tip_pct].describe()
result
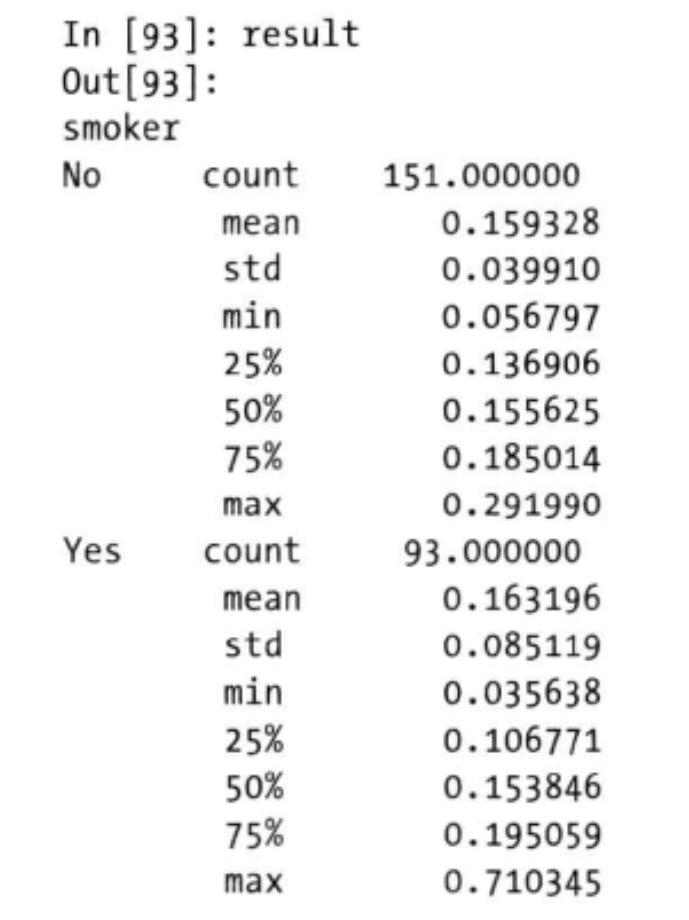
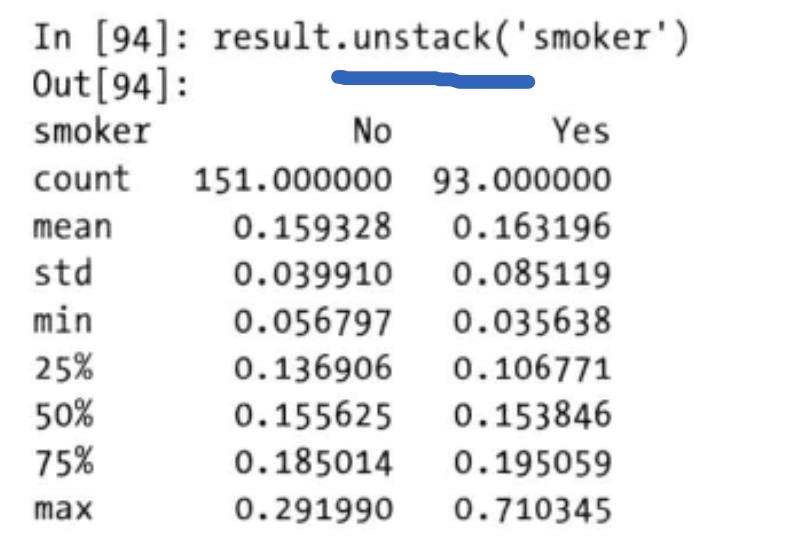

从上面的例子中,可以看出分组键会跟原始对象的索引共同构成结果对象中的层次化索引。将group_keys=False传入groupby即可禁止该效果。

几个需要注意的点
-
这里的各个片段是指的是根据分组键将划分成的各个片段,这个df片段的index是这个片段在原df中所对应的片段,列是原df中的全部的列,当然包括分组键列,列的数据是分组片段列在原df中对应的数据,进行这个操作
tips.groupby(\'smoker)[\'tip\'].apply(f)时,则我们在片段上只选择了一列tip,当然没有选择分组键列,所以传进函数f的分组片段df这里只有一列tip,没有分组键列smoker -
并以分组名称进行了标记
这是最后阶段apply函数做的工作,也就是说在组装到一起后,在最后结果的index的外层以分组名加了一个索引,于是最终结果就有了一个层次化索引,group_keys参数控制着apply函数是否在最后阶段做这个额外的工作。当然这个apply做的额外工作,有的时候会直接不做,此时group_keys参数无意义,这主要看传入apply中的函数,到底是进行了何种操作。
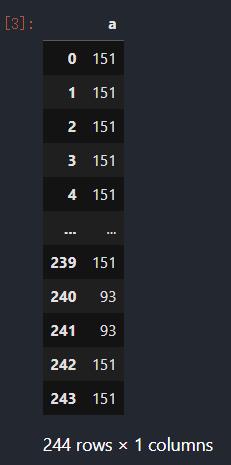
def f_a(df):
temp = pd.DataFrame({\'a\':len(df)*[str(len(df))]},index=df.index)
return temp
tips_df.groupby(\'smoker\').apply(f_a)
def new_copy_col(df,col=\'smoker\'):
df[\'y\'] = df[col]*2
return df
tips_df.groupby(\'smoker\').apply(new_copy_col,col=\'time\')
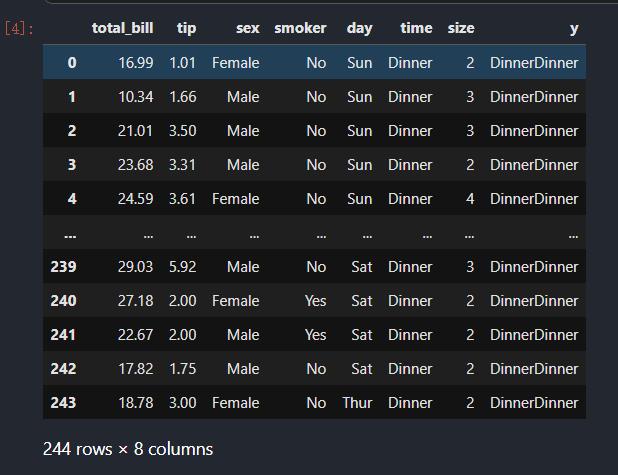
从这两个例子中,可以看出当我们传入apply里面的函数在每个分组上所做的操作产生的结果dataframe的index还是原来的分组的index时,分组键不会构成最后结果的多级索引的最外层的索引.
以上是关于pandas GroupBy上的方法apply:一般性的“拆分-应用-合并”的主要内容,如果未能解决你的问题,请参考以下文章