数据预处理
Posted enhaofrank
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据预处理相关的知识,希望对你有一定的参考价值。
数据预处理的主要内容包括数据清洗、数据集成、数据变换、数据规约。
数据清洗主要是删除原始数据集中的无关数据、重复数据,平滑噪声数据,筛选掉与挖掘主题无关的数据,处理缺失值和异常值。
数据质量分析是检查数据中是否存在一些脏数据,例如:缺失值、异常值和不一致的值等。
数据缺失有很多原因,例如数据无法获得,人为原因没有填写,数据采集设备故障等等,那么缺失值对建模过程多少会有一些影响,目前对于缺失,大致有三种处理方式:1、删除缺失值的特征 2、对缺失值进行插补 3、不处理。
数据插补的方法:均值/中位数/众数插补、使用固定值、最近邻插补、回归方法、插值法。
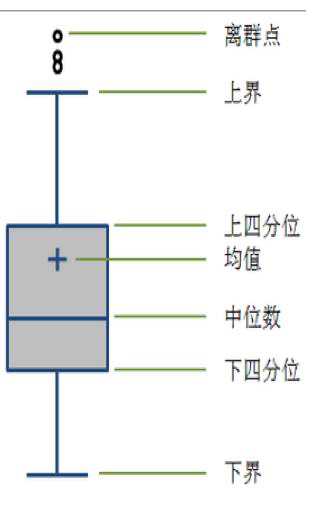
异常值指的是样本中的个别值,其数值明显偏离其他的观测数据,异常值也称为离群值,可以从下面几个方面判断:1、简单的统计量分析,例如年龄,客户的年龄填的是200岁,这种就是很明显的异常值,2、3σ原则,如果数据服从正太分布,在3σ原则下,异常值被定义为一组测定值中与平均值的偏差超过3倍标准差的值。因为数值分布在(μ-3σ,μ+3σ)中的概率为0.9973,分布在外面的概率<=0.003,数据极个别小概率事件,3、箱线图分析,异常值通常被定义为QL-1.5IQR或者QU+1.5IQR的值。QL称为下四分位数,QU称为上四分位数,IQR称为四分位数间距,是上四分位数与下四分位数之差。
异常值处理:删除含有异常值的记录、视为缺失值(按照缺失值填充)、平均值修正、不处理。
数据规范化(归一化):因为不同的指标结果具有不同的量纲,数值间差别可能很大,不进行处理可能会影响数据分析的结果。为了消除指标之间的量纲和取值范围差异的影响,需要进行标准化处理。常用的数据归一化方法有:
1、最小-最大规范化
(x - min)/ (max -min)
2、零-均值规范化
(x - mean(x))/std(x)
参考资料:
1、python数据分析与挖掘实战
以上是关于数据预处理的主要内容,如果未能解决你的问题,请参考以下文章