数据迁移的套路
Posted stonefang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据迁移的套路相关的知识,希望对你有一定的参考价值。
数据迁移的类型
随着业务的发展,存储也会经常性的需要迁移。以下场景是我们开发过程中经常遇到的
- 业务、团队在快速扩张,需要适当时机进行微服务的拆分,需要独立的数据库,将数据从源数据库迁移到新的数据库
- 单表的记录数比较大,需要进行分库分表。需要将老表的数据迁移到新的分表中。
- 存储选型不对,比如关系型数据库的相互迁移, PG, mysql,Oracle的相互迁移。NoSQL的Mongo,Cassandra,Hbase的相互迁移。
- 机房的迁移,自建机房到云的相互迁移
这些场景都需要进行数据迁移,虽然细节的方案有不同之处,但是也会有一些共同之处。
数据迁移的方案
数据迁移简单来说就是将数据从一个地方挪到另外一个地方。
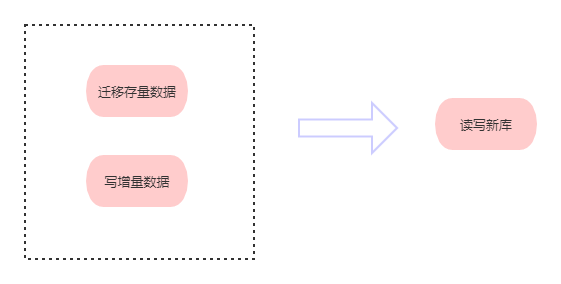
因为我们的数据不是静态的,所以我们不能随便写个job迁移就好了。需要确保一些迁移上的标准
标准
数据一致性
迁移完数据不能丢记录,单条记录的数据不能缺字段。
不停机
数据在不断的写入,不能为了阻止写入,而不允许数据写入,需要保证业务写入的可用性。
迁移过程可中断、可回滚
这点要求很高,是确保数据万无一失的策略。在迁移数据的各个阶段发现有问题,都可以回滚到原来的库,保证业务正常运行。
迁移方案
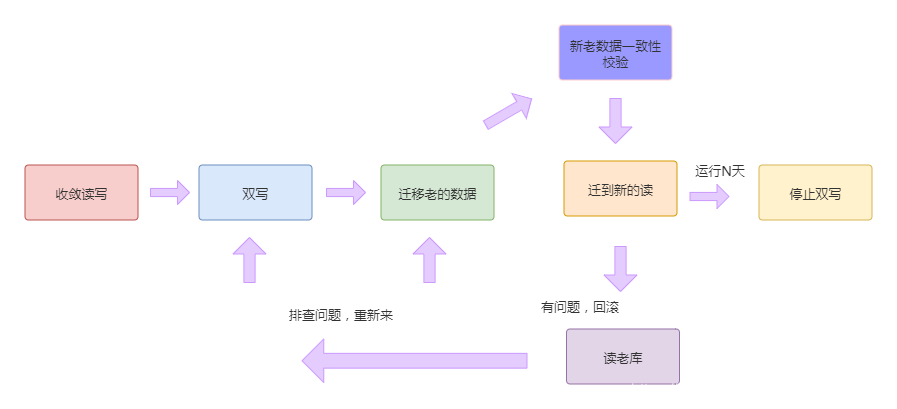
为了达到上述要求,一般采用双写策略。也就是写两份,既往老的写,也往新的写。
- 收敛读写
读写的入口越多,后续需要进行开关切换的地方就越多,就越容易出错,所以要尽可能的先将所有的读写入口都收敛到一个地方 - 双写
将增量的数据同时写入到两个存储系统。确保新的写入代码没问题。双写以写入老的为准,老的写入成功代表操作成功了,写入新的失败了需要记录失败日志,分析为何失败,进行修正和补偿 - 将老的存量数据迁移过来
老的存量数据迁移就是通过遍历id,写入新的存储。具体的方案有很多。可以使用同步工具,比如binlog +flink来处理。数据量比较少的就直接遍历就行。 - 数据校验
数据的一致性校验是重中之重,确保两边数据的记录数,单条记录的数据完整性。如果数据量不多,一般是全量校验。数据量很多,可以抽样校验。 - 切换新的读
数据校验通过后,就可以切换到新的读,万一还有问题,可以切换到老的读。排查问题,重新来过。 - 停止双写
在新的存储中安全平稳的运行了N天后,就可以停掉老的读了,整个迁移过程完成了。
注意事项
- 对于后端服务,存储是基石,是重中之重。稳定性要求是最高的。一定要确保数据是平滑迁移的,对业务无感知。
- 同时存储是有状态的,迁移难度比较大,开发者需要具备前瞻性,尽量在选型的时候慎重,选择合适的数据库,避免进行数据库迁移。发现数据库选型有潜在的问题时,需要当机立断,尽早迁移。不要以为出现问题的概率不大,就拖延了。否则一旦出现问题,就是重大故障,造成的损失难以估量。
以上是关于数据迁移的套路的主要内容,如果未能解决你的问题,请参考以下文章