数据迁移 - 如何快速迁移
Posted stonefang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据迁移 - 如何快速迁移相关的知识,希望对你有一定的参考价值。
摘要
在上一篇中我们介绍了数据迁移的套路,但是没有介绍具体的方案,这篇着重介绍下具体的数据迁移方案
一. 设计目标
设计一个数据迁移的方案,需要实现以下目标
-
迁移速度
qps 需要达到1k,这样能保证1亿的数据能够在1~2天内跑完 -
迁移qps可控
迁移有可能对线上服务有影响,需要可动态调整qps -
数据完整,不丢失
不能遗漏数据,虽然事后我们有数据校验的过程,但是设计数据迁移方案时,需要尽可能的包装数据不丢失。 -
进度可控
迁移过程可中断,可重试。比如先迁移10分之一的数据,再继续来
二. 架构设计
数据迁移任务大致分为3个步骤,如下图所示
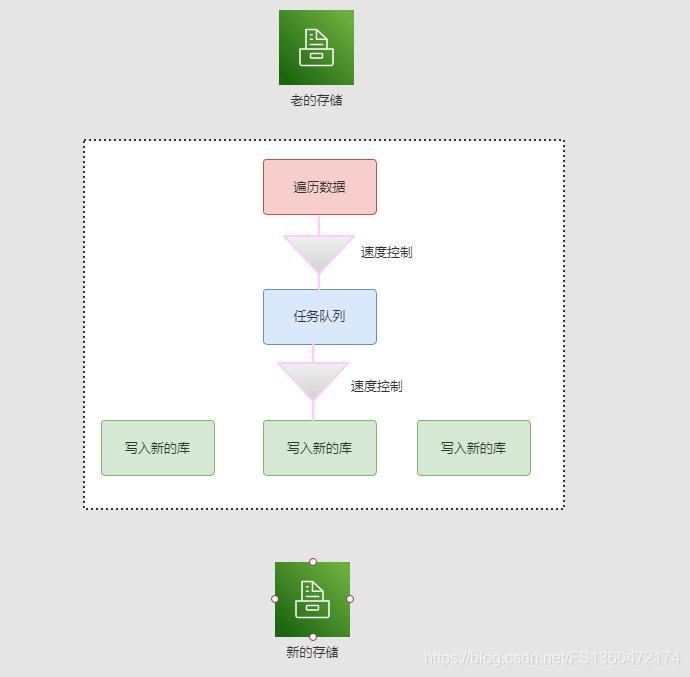
因为有迁移速度的要求,我们将每个步骤进行分解,确保每个部分可以异步化,并发处理。这样可以提升速度。
遍历数据
完整遍历老的数据库。不同的数据库有不同的方法,比如对于mysql,可以利用现成的binlog,其中就有全量的数据。
对于其他数据库,通常有两种方案
- 单线程游标遍历
单向遍历,这样不用进行线程之间的数据同步管理,实现比较简单。为什么不直接查数据记录呢,因为相比较于游标,查数据记录数据量比较大,网络开销大。游标一次可以拉取1000个数,而只占用很小的数据大小,然后在内存中分配。单个值获取耗时远小于1ms,所以即使是单线程,遍历数据这块的qps也能轻松达到1k以上。
同时因为是顺序遍历,所以可以保证数据不会丢。 可以可以将成功遍历完,写入到任务队列的数据记录到某个存储,比如redis中,这样可以保证游标中断,或者服务重启后,可以从这个key中继续遍历,这样就实现了迁移的可中断
2. 多线程分块遍历
需要提前对数据进行分片,保证每块不冲突。比如所有的数据是按照A~Z来分布的。那可以开26的线程,分别负责遍历A,Z。 因为不同的数据
任务队列
任务队列的要求就是高并发的写,能够支持较长时间的存储。kafka,rocketmq等消息队列都能满足,
qps都能达到万级别以上,都能满足当前方案的性能要求。
同时可以使用批量提交,来进一步提升写入速度。
写入新库
写入新库的操作不要求有顺序性,所以只要支持水平扩展即可无限提升速度。
三. 具体实现
需要结合具体的业务场景和公司已有的基础设施来选用具体的实现方案。
场景一: 数据量很少,1千万以内
杀鸡焉用牛刀,使用本地线程池来实现即可,不需要额外的任务队列。简单高效
场景二: 数据量比较大,公司里已经有离线数据处理基础设施
数据库 to kafka 组件,将数据写入到kafka,然后写处理job扔到flink中跑。
场景三: 数据量比较大,公司无基础设施
遍历老数据库, 写入到消息队列中,然后监听消息,查询数据,写入到新库中。也很容易实现。
以上是关于数据迁移 - 如何快速迁移的主要内容,如果未能解决你的问题,请参考以下文章
Elasticsearch数据迁移或者版本升级,如何快速提升迁移效率?
Elasticsearch数据迁移或者版本升级,如何快速提升迁移效率?