浙大《数据结构》第九章:排序(上)
Posted superorange
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了浙大《数据结构》第九章:排序(上)相关的知识,希望对你有一定的参考价值。
注:本文使用的网课资源为中国大学MOOC
https://www.icourse163.org/course/ZJU-93001
简单排序
前提
void X_Sort( ElementType A[], int N )
- 大多数情况下,为简单起见,讨论从小到大的整数排序
- N是正整数
- 只讨论基于比较的排序(>=<有意义)
- 只讨论内部排序(即不考虑类似于数据分布于不同的服务器中)
- 稳定性:任意两个相等的数据,排序前后的相对位置不发生改变
冒泡排序
基本思想:
- 比较相邻的元素。如果第一个比第二个大,就交换他们两个
- 对每一对相邻元素做同样的工作,从开始第一对到结尾的最后一对。在这一点,最后的元素应该会是最大的数;
- 针对所有的元素重复以上的步骤,除了最后一个;
- 持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。
时间复杂度:
- 最好情况,顺序T=O(N)
- 最坏情况,逆序T=O(N^2)
稳定性:是
void Bubble_Sort( ElementType A[], int N )
{
int P,i,flag;
for (P=N-1; P>=0; P--)
{
flag = 0;
for (i=0; i<P; i++)
{
// 一趟冒泡
if (A[i] > A[i+1])
{
Swap(A[i], A[i+1]);
flag = 0; // 标识发生了交换
}
}
if (flag==0) // 如果第一趟冒泡全程无交换
break;
}
}
插入排序
基本思想:
- 从第2张牌开始排序
- 取出未排序序列中的第一个元素
- 插到前面已经排好的序列中,比较并右移,使得插入后序列也是排好顺序的
- 按照此法对所有元素进行插入,直到整个序列排为有序的过程
时间复杂度:
- 最好情况,顺序T=O(N)
- 最坏情况,逆序T=O(N^2)
稳定性:是
void Insertion_Sort( ElementType A[], int N )
{
int P, i;
ElementType Tmp;
for ( P=1; P<N; P++ )
{
Tmp = A[P]; // 取出未排序序列中的第一个元素
for ( i=P; i>0 && A[i-1]>Tmp; i-- )
A[i] = A[i-1]; // 依次与已排序序列中元素比较并右移
A[i] = Tmp; // 放进合适的位置
}
}
时间复杂度下界
- 对于下标i<j, 如果A[i] > A[j],则称(i, j)是一对逆序对
- 问题:序列{34, 8, 64, 51, 32, 21}中有多少逆序对?
——(34,8) (34,32) (34,21) (64,51) (64,32) (64,21) (51,32) (51,21) (32,21)
- 交换2个相邻元素正好消去一个逆序对!
- 插入排序:T(N,I) = O(N+I),N为序列长度,I为逆序对个数
——如果序列基本有序,则插入排序简单且高效
- 定理:任意N个不同元素组成的序列平均具有N(N-1)/4个逆序对
- 定理:任何仅以交换相邻两元素来排序的算法,其平均时间复杂度为(Omega(N^2))
- 这意味着:要提高算法效率,我们必须
- 每次消去不止一个逆序对
- 每次交换相隔较远的2个元素
希尔排序
举个例子
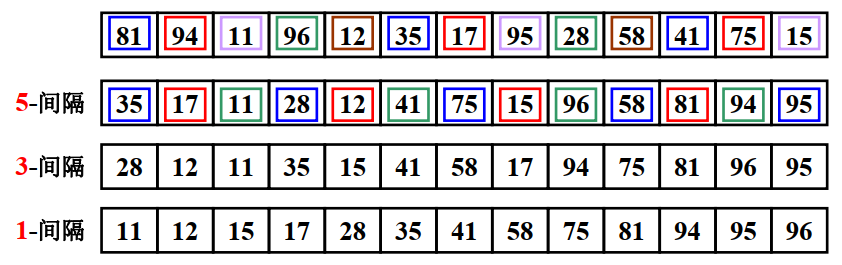
- 初始序列为{81,94,11,96,12,35,17,95,28,58,41,75,15}
- 首先按照5间隔取子序列排序,即首先取{81,35,41}进行排序,然后依次取{94,17,75},{11,95,15},{96,28},{12,58}进行子序列排序,之后再将子序列合并成总的序列即{35,17,11,28,12,41,75,15,96,58,81,94,95}
- 同理对5间隔排序后得到的序列进行3间隔排序可以得到序列{28,12,11,35,15,41,58,17,94,75,81,96,95}
- 最后对3间隔的序列做1间隔排序
归纳为:
- 定义增量序列(D_M > D_{M-1} > ... > D_1 = 1)
- 对每个(D_k)进行(D_k)间隔排序(k=M,M-1,...,1)
- 注意:(D_k)间隔有序序列,在执行(D_{k-1})间隔排序后,仍然是(D_k)间隔有序的。
原始希尔增量序列
原始希尔排序 : (D_M = left lfloor N/2 ight floor, D_k = left lfloor D_{k+1}/2 ight floor)
void Shell_Sort( ElementType A[], int N )
{
int D,P,i;
ElementType Tmp;
for ( D=N/2; D>0; D/=2 ) // 希尔增量序列
{
for ( P=D; P<N; P++) // 插入排序
{
Tmp = A[P];
for ( i=P; i>=D && A[i-D]>Tmp; i-=D )
A[i] = A[i-D];
A[i] = Tmp;
}
}
}
更多增量序列
-
Hibbard增量序列
- (D_k = 2^k-1)——相邻元素互质
- 最坏情况:(T=Theta(N^{3/2}))
- 猜想:(T_{avg}=O(N^{5/4}))
-
Sedgewick增量序列
- {1,5,19, 41, 109,...}——9x4^i - 9x2^i + 1或4^i - 3x2^i + 1
- 猜想:(T_{avg} = O(N^{7/6}), T_{worst} = O(N^{4/3}))
/* 希尔排序 - 用Sedgewick增量序列 */
void ShellSort( ElementType A[], int N )
{
int Si, D, P, i;
ElementType Tmp;
/* 这里只列出一小部分增量 */
int Sedgewick[] = {929, 505, 209, 109, 41, 19, 5, 1, 0};
for ( Si=0; Sedgewick[Si]>=N; Si++ )
; /* 初始的增量Sedgewick[Si]不能超过待排序列长度 */
for ( D=Sedgewick[Si]; D>0; D=Sedgewick[++Si] )
for ( P=D; P<N; P++ ) /* 插入排序*/
{
Tmp = A[P];
for ( i=P; i>=D && A[i-D]>Tmp; i-=D )
A[i] = A[i-D];
A[i] = Tmp;
}
}
堆排序
选择排序
思路:
- 先从A[i]到A[N–1]中直接扫描找最小元,记录其位置
- 将A[i]与处于最小元位置的元素进行交换
void Selection_Sort( ElementType A[], int N )
{
int i, MinPosition;
for ( i=0; i<N; i++ )
{
// 从A[i]到A[N–1]中找最小元,并将其位置赋给MinPosition
MinPosition = ScanForMin( A, i, N-1 );
// 将未排序部分的最小元换到有序部分的最后位置
Swap( A[i], A[MinPosition])
}
}
堆排序
思路:与选择排序类似,但是改变最小元的扫描策略,利用堆结构扫描
算法1
思路:
- 首先将数组调整为最小堆
- 利用一个临时数组存储依次弹出的根结点
- 将临时数组直接赋值给原数组
因此:
- 算法1的最终时间复杂度为T(N) = O(NlogN);
- 但是需要额外的O(N)空间,并且复制元素需要时间
void Heap_Sort( ElementType A[], int N )
{
BuildHeap(A); // 将数组A调整为堆,复杂度为O(N)
for ( i=0; i<N; i++ )
TmpA[i] = DeleteMin(A); // 依次弹出根结点,此时 O(logN)
for ( i=0; i<N; i++ )
A[i] = TmpA[i]; // 直接赋值,此时复杂度为O(N)
}
算法2:
思路:
- 先将数组调整为一个最大堆
- 将根结点与堆的最后一个元素进行交换
- 删除堆的倒数第一个元素,存至数组的末尾,重新对堆进行最大堆的调整
- 直到堆的元素为1
/* 交换 */
void Swap( ElementType *a, ElementType *b )
{
ElementType t = *a; *a = *b; *b = t;
}
/* 将N个元素的数组中以A[p]为根的子堆调整为最大堆 */
void PercDown( ElementType A[], int p, int N )
{
int Parent, Child;
ElementType X;
X = A[p]; /* 取出根结点存放的值 */
for( Parent=p; (Parent*2+1)<N; Parent=Child )
{
Child = Parent * 2 + 1;
if( (Child!=N-1) && (A[Child]<A[Child+1]) )
Child++; /* Child指向左右子结点的较大者 */
if( X >= A[Child] )
break; /* 找到了合适位置 */
else /* 下滤X */
A[Parent] = A[Child];
}
A[Parent] = X;
}
/* 堆排序 */
void HeapSort( ElementType A[], int N )
{
int i;
for ( i=N/2-1; i>=0; i-- )/* 建立最大堆 */
PercDown( A, i, N );
for ( i=N-1; i>0; i-- )
{
/* 删除最大堆顶 */
Swap( &A[0], &A[i] );
PercDown( A, 0, i );
}
}
- 定理:堆排序处理N个不同元素的随机排列的平均比较次数是2N logN - O(N log(logN ))
- 虽然堆排序给出最佳平均时间复杂度,但是实际效果不如用Sedgewick增量序列的希尔排序
归并排序
核心思想:有序子列的归并
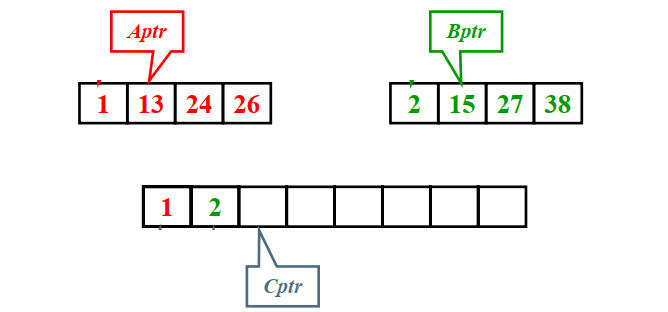
将子序列A,B的元素依次比较,合并成C序列
/* L = 左边起始位置, R = 右边起始位置, RightEnd = 右边终点位置 */
void Merge( ElementType A[], ElementType TmpA[], int L, int R, int RightEnd )
{
int LeftEnd, Tmp, NumElements;
LeftEnd = R - 1; // 左边终点位置。假设左右两列挨着
Tmp = L; // 存放结果的数组的初始位置
NumElements = RightEnd - L + 1;
while ( L<=LeftEnd && R<=RightEnd )
{
if ( A[L] <= A[R] )
TmpA[Tmp++] = A[L++];
else
TmpA[Tmp++] = A[R++];
}
while( L <= LeftEnd ) // 直接复制左边剩下的
TmpA[Tmp++] = A[L++];
while( R <= RightEnd ) // 直接复制右边剩下的
TmpA[Tmp++] = A[R++];
for( i = 0; i < NumElements; i++, RightEnd -- )
A[RightEnd] = TmpA[RightEnd];
}
递归版分而治之
void MSort( ElementType A[], ElementType TmpA[], int L, int RightEnd )
{
int Center;
if ( L < RightEnd )
{
Center = ( L + RightEnd ) / 2;
MSort( A, TmpA, L, Center );
MSort( A, TmpA, Center+1, RightEnd );
Merge( A, TmpA, L, Center+1, RightEnd );
}
}
可以推得:T(N) = T(N/2)+T(N/2)+O(N) --> T(N)=O(N logN )
统一函数接口
void Merge_sort( ElementType A[], int N )
{
ElementType *TmpA;
TmpA = (ElementType *)malloc(N*sizeof( ElementType ))
if ( TmpA != NULL )
{
MSort(A, TmpS, 0, N-1);
free( TmpA );
}
else
Error("空间不足");
}
非递归版归并排序
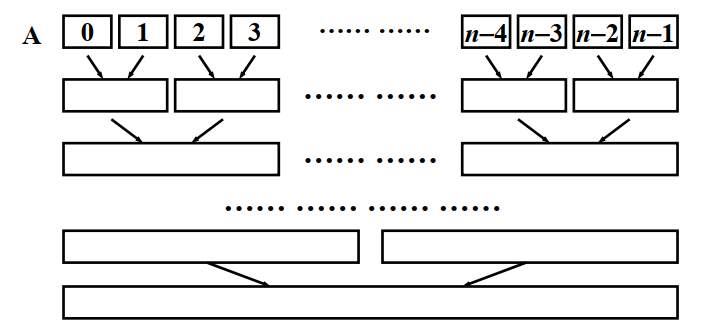
思路:
- 首先对长度为N的序列相邻的两个元素进行排列,
- 然后合并成N/2个子序列,对相邻的子序列进行合并排序
- 依次类推,直至合并成为长度为N的序列
- 由图可知,需要额外的O(N)内存空间进行临时值得存储
/* 归并排序 - 循环实现 */
/* 两两归并相邻有序子列 */
/* length = 当前有序子列的长度*/
void Merge_pass( ElementType A[], ElementType TmpA[], int N, int length )
{
int i, j;
for ( i=0; i <= N-2*length; i += 2*length ) // 首先只考虑偶数子列的情况
Merge( A, TmpA, i, i+length, i+2*length-1 ); // 与递归版本中的Merge函数一致
if ( i+length < N ) /* 归并最后2个子列*/
Merge( A, TmpA, i, i+length, N-1);
else /* 最后只剩1个子列*/
{
for ( j = i; j < N; j++ )
TmpA[j] = A[j];
}
}
void Merge_Sort( ElementType A[], int N )
{
int length;
ElementType *TmpA;
length = 1; /* 初始化子序列长度*/
TmpA = malloc( N * sizeof( ElementType ) );
if ( TmpA != NULL )
{
while( length < N )
{
Merge_pass( A, TmpA, N, length );
length *= 2;
Merge_pass( TmpA, A, N, length ); // 保证最后的排序结果存储在数组A中
length *= 2;
}
free( TmpA );
}
else
printf( "空间不足" );
}
结论:
- 在内排序中一般不使用归并排序,因为要使用内存
- 在外排序中归并排序比较有用
以上是关于浙大《数据结构》第九章:排序(上)的主要内容,如果未能解决你的问题,请参考以下文章