三维点云深度学习与语义理解方法及关键技术
Posted yongqivisionimax
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了三维点云深度学习与语义理解方法及关键技术相关的知识,希望对你有一定的参考价值。
作者:若晨Date:2020-05-14
这一次给大家带来在自动驾驶中关于三维点云的深度学习方法应用、三维场景语义理解的方法以及对应的关键技术介绍。
1.三维点云深度学习
在深度学习引入前,传统方法大多使用人工设计的特征[26-29] 以及随机森林(Random Forest) 等分类器进行点云的语义理解。近年来,深度学习[30] 在图像处理、语音识别等领域已有较多成果。深度学习的成功之处在于其可以利用如前所述的大规模数据集,进行特征的自动学习,避免人工设计特征的局限。卷积神经网络 (Convolutional Neural Network, CNN) 是深度学习中强有力的特征提取工具,其应用的条件之一是所处理的数据为规则数据。值得注意的是,语音为一维空间上规则排列的信号,图像为二维空间上栅格排列的像素,视频为三维空间上的规则数据,均满足 CNN 应用的条件。受制于原始点云数据的无序性,直接在点云上应用卷积神经网络(Convolutional Neural Network, CNN) 并不现实。针对此问题,众多学者进行了大量有价值的研究。
三维点云有多种表示方法(如图1所示),不同的表示对应着不同的处理方法。比较容易的处理方式为将其投影为二维图像或者转换为三维体素 (Voxel),从而将无序的空间点转变为规则的数据排列;也可以使用原始点作为表示,不做任何变换,该方式的好处为最大可能保留所有原始信息。此外,点云作为空间无序点集,可以被看作普适意义上的图数据;点云还有另外一种表示,称作网格 (Mesh),其也可以被看作是构建了局部连接关系的点,即为图。将点云看作图数据,可以使用图领域新兴的图卷积 (Graph Convolution) 技术进行处理。需要提及的是,原始点的表示和图表示之间并无明确界限(事实上原始点云和网格 (Mesh) 之间有一定区别,但若从语义理解方法的角度看,可暂时忽略此区别,将Mesh看作是增加了一种连接关系),本文将其划分为两类,是为了更加详细地介绍图卷积的发展背景与脉络。
综上,本节从四种点云表示切入,介绍深度学习在三维点云上的应用,分别为:基于二维投影的方法、基于三维体素的方法、基于原始点的方法和基于图的方法。

1.1 基于二维投影的方法
CNN 最好的应用领域在于图像处理,将三维点云数据投影到二维图像平面,即可使得 CNN 应用于点云数据成为可能。
在文献 [31] 中,作者将原始的三维点云从不同视角进行投影,得到 12 个视角下的投影图片,并使用 CNN 对不同视角的图片分别提取特征,通过池化结合不同视角的信息,进行最终的点云物体分类。在文献 [32, 33] 中,作者使用类似的思路对三维场景进行多视角投影,生成一系列 RGB 图、深度图及其他属性图片,并使用全卷积 (Fully Convolutional Networks, FCN)[34] 进行像素级语义分割,最终通过反向投影得到点云的语义分割结果。在文献 [35] 中,作者将单帧 64 线激光雷达数据投影为鸟瞰图和前视图,并结合摄像头采集的 RGB 图,并列输入进三个CNN,其中,鸟瞰图和前视图编码了高度、密度、强度等一系列信息,三个网络的特征相互融合得到物体的三维边界框。在文献 [36] 中,作者使用类似于 [31] 的思路,设置多个不同尺度的投影视角,并结合条件随机场(Conditional Random Field,CRF)[37],进行三维点云物体的部件分割。在文献 [38] 中,作者对单帧 64 线激光雷达数据进行球面投影 (Spherical Projection),得到对应的图像,图像的像素值编码为 x 坐标、强度和深度三通道,使用运行效率较高的 SqueezeNet[39] 进行图像的语义分割,使用 CRF 进行后处理优化,最终将分割结果投影至点云。在文献 [40]中,作者将层次分组概念引入到多视角投影中,提出“视角-组别-形状”由低到高的三个层次,实现更加具有可分度的特征学习。在文献 [41] 中,作者沿着点云表面法线方向,将局部点云投影至切平面,对切平面上的投影图像使用 FCN 进行语义分割。在文献 [42] 中,作者使用类似于 [35] 的点云投影方法,进行三维目标的边框预测。与 [35] 不同的是, [42] 未使用前视图,并舍弃了鸟瞰图中的强度信息。
1.2 基于三维体素的方法
对三维点云进行二维投影降低了算法处理的难度,但是三维到二维的投影必然带来几何结构信息的损失,直接进行三维特征的提取在一些场景下是非常有必要的。一种最自然的想法便是 CNN 的延拓,将二维卷积神经网络拓展一个维度,使其可以处理三维排列的数据;同时,对点云进行体素化 (Voxelization),将其转换为空间上规则排布的栅格,使得三维卷积神经网络(Three Dimension Convolutional Neural Network, 3DCNN) 可以直接应用在这种表示上。
文献 [43, 44] 是较早将 3DCNN 应用于三维点云处理的工作,他们将原始点云转换为体素 (Voxel),并使用 3DCNN 进行点云物体的特征提取。在文献 [45] 中,作者深入探讨了基于二维投影的方法和基于三维体素的方法的优劣,尝试寻找这两种方法精度差异的来源,并针对 3DCNN 提出两种优化措施:使用完整物体的一部分进行辅助训练以及使用各向异性的 3D卷积核。在文献 [46] 中,作者使用三维卷积构建三维全卷积网络,串联以三线性插值和条件随机场,实现室内、室外点云场景的语义分割。在文献 [47] 中,作者提出体素特征编码模块,使用 PointNet[48]编码同一体素内的特征,并使用 3DCNN 进行体素间的特征提取。
在文献 [49, 50] 中,作者使用八叉树数据结构对三维点云进行编码,以降低3DCNN 的显存占用与计算耗时,使得体素的分辨率可以进一步提高,从而可以学习到空间上更加精细的特征。在文献 [51, 52] 中,作者提出类似的降低 3DCNN 显存占用的方法,不过省略了使用八叉树作为中间表示,直接通过哈希表构建了稀疏矩阵的索引关系。这类思路极大提高了 3DCNN 提取特征的能力。在文献 [53]中,作者将稀疏编码技术应用于点云的目标检测,其整体框架类似于 [47]。由于稀疏编码的优势,使得该方法相比 [47] 取得了更好的效果。在文献 [54] 中,作者将稀疏优化的卷积[51] 用作点云目标检测的特征提取网络,借鉴传统两阶段目标检测框架[55],提升了三维目标检测的性能。
1.3 基于原始点的方法
无论是二维投影还是三位体素,均需要对原始点云进行一定的转换,而转换必然带来数据信息的损失。
在文献 [48] 中,作者开创性地提出 PointNet,一个用于直接处理原始点云数据的神经网络。该方法使用多层感知机进行逐点特征提取,使用池化进行全局特征提取,可用于三维点云的分类、部件分割、语义分割等多种任务,开辟了基于原始点方法的先河。但是 PointNet 没有考虑点云的局部特征,该研究者在随后发表的 [56] 中,对 PointNet 进行改进,通过设计点云数据的层次结构以及多尺度特征,实现局部特征与全局特征的融合。
点云局部特征的有效提取是点云理解中较为本质的问题之一。在文献 [57] 中,作者根据点云局部坐标信息学习置换矩阵,对局部点云的特征进行变换和加权,试图实现点云局部排序的一致性。在文献 [58] 中,作者通过自组织映射从原始点云中计算得到自组织节点,并将近邻点的特征汇聚至自组织节点处。在文献 [59]中,作者将点云转换到 Lattice 坐标系下,并定义了在该坐标系下的卷积操作。在文献 [60] 中,作者沿三个坐标轴对点云进行空间分块,使用三组循环神经网络(RecurrentNeural Network, RNN) 进行块与块之间特征的传递,构建局部联系。在文献 [61] 中,作者使用金字塔池化方法和双向 RNN 进行局部特征的传递。文献[62] 借鉴 SIFT[63] 特征点的思路,将局部点云划分为八个区域,解决仅根据离进行近邻搜索所带来的问题。类似的思路有 [64],其提出一种逐点的 3D 卷积,对于每个点,将其局部邻域按照卷积核的排列规则,划分到不同的栅格中,并将 3D卷积核应用于该局部栅格。在文献 [65] 中,作者通过公式推导提出一种高效的点云卷积,在不改变计算精度的情况下,大幅降低了模型显存的需求。在文献 [66]中,作者定义了一种新的点云卷积核函数,其不同于规则的固定栅格式卷积,而是通过插值计算每个点处的卷积参数,在使用上更加灵活。
基于原始点的方法从 2017 年开始兴起,并已经取得了较大的进步,其在语义分割[56, 62]、目标检测[67-69]、实例分割[70, 71]、点云匹配[72, 73] 等任务上应用并取得不错的效果。
1.4 基于图的方法
现实生活中存在大量的非结构化数据,如交通网络、社交网络等,这些数据的节点间存在联系,可以表示为图。研究图数据的学习是近年来学界的热点。三维点云数据可以看作图数据的一种,图网络的很多思想可以被借鉴于点云数据的特征学习中。
图卷积 (Graph Convolution Network, GCN) 可分为基于谱的图卷积(Spectralbased GCN) 和基于空间的图卷积 (Spatial-based GCN)。基于谱的图卷积的基本思路是:依据卷积定理,首先根据图的傅里叶变换将图数据从空间域变换到谱域,并在谱域上进行卷积,随后再通过图的傅里叶反变换将卷积结果转换到空间域。早期的图卷积大多为基于谱的方法,在文献 [74] 中,作者使用拉普拉斯矩阵 (Laplacian Matrix) 定义图的傅里叶变换,并定义了图数据上的卷积操作,构建了图卷积网络。
在文献 [75] 中,作者对 [74] 的工作进行了改进,使用切比雪夫多项式代替先前工作中的傅里叶变换,避免了矩阵的特征值分解,同时使得图卷积操作的感受野变为近邻的 k 个节点 (K-localized),参数复杂度也由 ??(??) 降低为??(??)。在文献 [76]中,作者对 [75] 提出的多项式进行了进一步的简化,仅保留 0 阶项和 1 阶项。从[74] 到 [75, 76] 的发展,也伴随着图卷积从基于谱的方法到基于空间的方法的转变。空间方法的本质简单可理解为在节点域定义节点间的权重,然后对邻域进行加权求和。在文献 [77] 中,作者提出使用注意力机制,定义节点之间的权重。在文献 [78] 中,作者针对邻域的采样和特征汇聚的方式进行了探讨,提出针对大规模图数据的处理方法。
图卷积的理论研究影响着三维点云的深度学习。在文献 [79] 中,作者使用基于谱的图卷积进行三维物体模型的语义分割,其提出谱变换网络以实现更好的参数共享,同时引入了空洞卷积的概念,增加多尺度信息。在文献 [80] 中,作者使用图卷积进行点云局部特征的提取。基于谱的图卷积由于需要计算特征分解,而不同点云数据的特征分解不相同,因此增加了基于谱的图卷积在点云上应用的难度。近年来不少学者转向使用基于空间的图卷积。在文献 [81] 中,作者结合边信息进行图卷积参数的学习。在文献 [82] 中,作者使用将邻接的边特征送进多层感知机进行训练。文献 [83] 借鉴 [77] 的思想应用在点云的语义分割任务上。
2. 三维场景语义理解方法
本节将介绍基于点云数据的三维场景语义理解方法。三维场景的语义理解包含多种任务,不同任务的目标和最终结果也各不相同,其中比较重要的任务包括语义分割、目标检测和实例分割(如图1–3所示)。

2.1 语义分割
三维点云语义分割任务是对每个点进行语义类别的预测,其常用的评价指标有整体精度 (Overall Accuracy, OA)、平均类别精度 (meanAccuracy, mAcc)、平均类别交并比 (mean Intersection over Union,mIoU),其定义为:
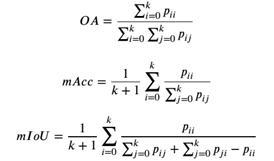
其中,??????表示本属于第 ??类的点被预测为第??类的数目。语义分割的研究重心之一在于其局部特征的提取以及局部特征和全局特征的融合。在文献 [46, 51, 52] 中,作者使用三维卷积构建三维全卷积网络,其结构类似于二维语义分割,其中 [51, 52] 对三维卷积进行了稀疏优化。在文献 [48] 中,作者提出使用池化进行全局特征的提取,并随后在 [56] 中提出适用于点云数据的编码-解码结构。在文献 [60, 61] 中,作者对点云进行分块从而提取局部特征,并使用 RNN 进行局部特征的传递。文献 [80, 82, 83] 借鉴图卷积的思想实现局部点云特征的提取。
2.2 目标检测
三维点云目标检测任务是对场景中的物体(如人、车等)进行识别,并预测其在空间中的三维边界框,其常用的评价指标有精确率 (Precision)、召回率 (Recall) 和平均精度 (Average Precison, AP)(此处的“平均精度”和语义分割中的“平均类别精度”不是同一指标,由于翻译为中文,容易混淆。),其定义为:
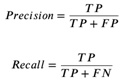
其中, TP 为正样本被正确识别为正样本的数量, FP 为负样本被错误识别为正样本的数量, FN 为正样本被错误识别为负样本的数量。在不同 IoU 阈值条件下,这三者的值也会对应发生变化。平均精度 (AP) 的值,即为设置不同阈值条件, PrecisionRecall 曲线下包含的积分面积。
早期使用二维投影进行三维目标检测的方法居多,在文献 [35, 42] 中,作者将单帧 64 线激光雷达数据投影为鸟瞰图,使用二维卷积神经网络进行预测。随着三维方法的不断发展,二维投影的精度优势逐渐消失。在文献 [47] 中,作者结合PointNet 和 3DCNN,先使用 PointNet 进行体素特征编码,再通过 3DCNN 进行边界框的回归。在文献 [53] 中,作者使用前述稀疏编码的方式对 [47] 进行了优化。在文献 [67] 中,作者首先使用图像得到二边界框,根据成像模型进行投影得到三维视锥,并使用 PointNet 对视锥内的点云进行三维边界框的预测。在文献 [68]中,作者使用一种自底向上的方式直接生成三维边界框,并在第二阶段对边界框进行优化改善。
2.3 实例分割
三维点云实例分割任务某种程度上可以理解为语义分割和目标检测的结合,该任务不仅需要预测每个点的语义类别,还需要区分其属于哪一个目标。该任务常用的评价指标与目标检测类似,为平均精度 (Average Precison, AP)。不同之处在于,目标检测判断预测是否正确的阈值为预测边界框和真实边界框的交并比,而实例分割使用的是预测点集与真实点集之间的交并比。
在文献 [70] 中,作者为实例分割定义了基于相似度矩阵的损失函数,对实例特征进行监督学习。文献 [71, 84] 使用基于目标提名的方式进行实例分割。在文献 [71] 中,作者使用生成模型预先得到实例的提名点;在 [84] 中,作者将图像特征融合进 3DCNN 进行目标检测与实例分割。
3.三维场景语义理解关键技术
使用点云数据进行三维场景语义理解,其关键技术主要分为三个方面:局部特征提取算法、特征监督算法、特征融合算法。
3.1 局部特征提取算法
三维点云在存储上是无序数据,因此其局部邻域不像有序数据如图像、文本等易于索引。对点云局部的有效表示及快速索引,是点云特征提取的基础。基于有效的局部表示和快速的局部索引,如何构建局部点云的相关性与联系,从局部结构中学习高层的语义特征,对基于点云数据的各项语义理解任务均是基础且重要的技术。
3.2 特征监督算法
使用深度学习提取特征的质量,除了和特征提取算法相关,还受特征监督算法的影响。有效的特征监督可以引导特征向正确的方向学习进化,不同任务对于特征监督的要求也各不相同。设计合适的特征监督算法,对于场景的语义理解是非常有价值的。
3.3 特征融合算法
原始点云数据具有很强的几何特征,但不具有颜色纹理信息。因此仅依靠三维点云进行语义理解在一些场景下是比较困难的。利用图像等其他数据,融合多源数据特征、优势互补,对三维场景语义理解很有价值,不同数据特征融合的位置、方式、程度对最终语义理解的效果也有非常大的影响。
参考文献
[26] RUSU R B, BLODOW N, BEETZ M. Fast point featurehistograms (FPFH) for 3D registration[C]//2009 IEEE International Conference onRobotics and Automation. Kobe, Japan: IEEE, 2009: 3212-3217.
[27] RUSU R B, BLODOW N, MARTON Z C, et al. Aligning pointcloud views using persistent feature histograms[C]//2008 IEEE/RSJ InternationalConference on Intelligent Robots and Systems. Nice, France: IEEE, 2008:3384-3391.
[28] OSADA R, FUNKHOUSER T, CHAZELLE B, et al. Shapedistributions[J]. ACM Transactions on Graphics (TOG), 2002, 21(4): 807-832.
[29] THOMAS H, DESCHAUD J E, MARCOTEGUI B, et al. SemanticClassification of 3D Point Clouds with Multiscale Spherical Neighborhoods[J].ArXiv preprint arXiv:1808.00495, 2018.
[30] LECUN Y, BENGIO Y, HINTON G. Deep learning[J]. Nature,2015, 521(7553): 436-444.
[31] SU H, MAJI S, KALOGERAKIS E, et al. Multi-viewconvolutional neural networks for 3d shape recognition[C]//Proceedings of theIEEE international conference on computer vision. Santiago, Chile: IEEE, 2015:945-953.
[32] BOULCH A, LE SAUX B, AUDEBERT N. Unstructured Point CloudSemantic Labeling Using Deep Segmentation Networks.[J]. 3DOR, 2017, 2: 7.
[33] LAWIN F J, DANELLJAN M, TOSTEBERG P, et al. Deepprojective 3D semantic segmentation[C]//International Conference on ComputerAnalysis of Images and Patterns. Ystad, Sweden: Springer, 2017: 95-107.
[34] LONG J, SHELHAMER E, DARRELL T. Fully convolutionalnetworks for semantic segmentation[C]//Proceedings of the IEEE conference oncomputer vision and pattern recognition. Boston, MA, USA: IEEE, 2015:3431-3440.
[35] CHEN X, MA H, WAN J, et al. Multi-view 3d objectdetection network for autonomous driving[C]//Proceedings of the IEEEinternational conference on computer vision. Honolulu, HI, USA: IEEE, 2017:1907-1915.
[36] KALOGERAKIS E, AVERKIOU M, MAJI S, et al. 3D ShapeSegmentation With Projective Convolutional Networks[C]//The IEEE Conference onComputer Vision and Pattern Recognition (CVPR). Honolulu, HI, USA: IEEE, 2017.
[37] LAFFERTY J, MCCALLUM A, PEREIRA F C. Conditional randomfields: Probabilistic models for segmenting and labeling sequence data[J].,2001.
[38] WU B, WAN A, YUE X, et al. Squeezeseg: Convolutionalneural nets with recurrent crf for real-time road-object segmentation from 3dlidar point cloud[C]//2018 IEEE International Conference on Robotics and Automation(ICRA). Brisbane, QLD, Australia: IEEE, 2018: 1887-1893.
[39] IANDOLA F N, HAN S, MOSKEWICZ M W, et al. SqueezeNet:AlexNet-level accuracy with 50x fewer parameters and< 0.5 MB model size[J].ArXiv preprint arXiv:1602.07360, 2016.
[40] FENG Y, ZHANG Z, ZHAO X, et al. GVCNN: Group-viewconvolutional neural networks for 3D shape recognition[C]//Proceedings of theIEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City, UT,USA: IEEE, 2018: 264-272.
[41] TATARCHENKO M, PARK J, KOLTUN V, et al. Tangentconvolutions for dense prediction in 3d[C]//Proceedings of the IEEE Conferenceon Computer Vision and Pattern Recognition. Salt Lake City, UT, USA: IEEE,2018: 3887-3896.
[42] KU J, MOZIFIAN M, LEE J, et al. Joint 3d proposalgeneration and object detection from view aggregation[C]//2018 IEEE/RSJInternational Conference on Intelligent Robots and Systems (IROS). Madrid,Spain: IEEE, 2018: 1-8.
[43] WU Z, SONG S, KHOSLA A, et al. 3d shapenets: A deeprepresentation for volumetric shapes[C]//Proceedings of the IEEE conference oncomputer vision and pattern recognition. Boston, MA, USA: IEEE, 2015:1912-1920.
[44] MATURANA D, SCHERER S. Voxnet: A 3d convolutionalneural network for real-time object recognition[C]//2015 IEEE/RSJ InternationalConference on Intelligent Robots and Systems (IROS). Hamburg, Germany: IEEE,2015: 922-928.
[45] QI C R, SU H, NIEßNER M, et al. Volumetric andmulti-view cnns for object classification on 3d data[C]//Proceedings of theIEEE conference on computer vision and pattern recognition. Las Vegas, NV, USA:IEEE, 2016: 5648-5656.
[46] TCHAPMI L, CHOY C, ARMENI I, et al. Segcloud: Semanticsegmentation of 3d point clouds[C]//3D Vision (3DV), 2017 InternationalConference on. Qingdao, China: IEEE, 2017: 537-547.
[47] ZHOU Y, TUZEL O. Voxelnet: End-to-end learning forpoint cloud based 3d object detection[C]//Proceedings of the IEEE Conference onComputer Vision and Pattern Recognition. Salt Lake City, UT, USA: IEEE, 2018:4490-4499.
[48] QI C R, SU H, MO K, et al. Pointnet: Deep learning onpoint sets for 3d classification and segmentation[C]//Proceedings of the IEEEConference on Computer Vision and Pattern Recognition. Honolulu, HI, USA: IEEE,2017: 652-660.
[49] RIEGLER G, ULUSOY A O, GEIGER A. Octnet: Learning deep3d representations at high resolutions[C]//Proceedings of the IEEE Conferenceon Computer Vision and Pattern Recognition. Honolulu, HI, USA: IEEE, 2017:3577-3586.
[50] WANG P S, LIU Y, GUO Y X, et al. O-cnn: Octree-basedconvolutional neural networks for 3d shape analysis[J]. ACM Transactions onGraphics (TOG), 2017, 36(4): 72.
[51] GRAHAM B, ENGELCKE M, van der MAATEN L. 3d semanticsegmentation with submanifold sparse convolutional networks[C]//Proceedings ofthe IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City,UT, USA: IEEE, 2018: 9224-9232.
[52] CHOY C, GWAK J, SAVARESE S. 4D Spatio-TemporalConvNets: Minkowski Convolutional Neural Networks[J]. ArXiv preprintarXiv:1904.08755, 2019.
[53] YAN Y, MAO Y, LI B. Second: Sparsely embeddedconvolutional detection[J]. Sensors, 2018, 18(10): 3337.
[54] SHI S, WANG Z, WANG X, et al. Part-A^ 2 Net: 3DPart-Aware and Aggregation Neural Network for Object Detection from PointCloud[J]. ArXiv preprint arXiv:1907.03670, 2019.
[55] REN S, HE K, GIRSHICK R, et al. Faster r-cnn: Towardsreal-time object detection with region proposal networks[C]//Advances in neuralinformation processing systems. Montreal, Quebec, Canada: MIT Press, 2015:91-99.
[56] QI C R, YI L, SU H, et al. Pointnet++: Deep hierarchicalfeature learning on point sets in a metric space[C]//Advances in NeuralInformation Processing Systems. Long Beach, CA, USA: MIT Press, 2017:5099-5108.
[57] LI Y, BU R, SUN M, et al. Pointcnn: Convolution onx-transformed points[C]// Advances in Neural Information Processing Systems.Montreal, Quebec, Canada: MIT Press, 2018: 820-830.
[58] LI J, CHEN B M, HEE LEE G. So-net: Self-organizingnetwork for point cloud analysis[C]//Proceedings of the IEEE conference oncomputer vision and pattern recognition. Salt Lake City, UT, USA: IEEE, 2018:9397-9406.
[59] SU H, JAMPANI V, SUN D, et al. Splatnet: Sparse latticenetworks for point cloud processing[C]//Proceedings of the IEEE Conference onComputer Vision and Pattern Recognition. Salt Lake City, UT, USA: IEEE, 2018:2530-2539.
[60] HUANG Q, WANG W, NEUMANN U. Recurrent Slice Networksfor 3D Segmentation of Point Clouds[C]//Proceedings of the IEEE Conference onComputer Vision and Pattern Recognition. Salt Lake City, UT, USA: IEEE, 2018:2626-2635.
[61] YE X, LI J, HUANG H, et al. 3d recurrent neuralnetworks with context fusion for point cloud semanticsegmentation[C]//Proceedings of the European Conference on Computer Vision(ECCV). Munich, Germany: Springer, 2018: 403-417.
[62] JIANG M, WU Y, ZHAO T, et al. Pointsift: A sift-likenetwork module for 3d point cloud semantic segmentation[J]. ArXiv preprintarXiv:1807.00652, 2018.
[63] LOWE D G. Distinctive image features fromscale-invariant keypoints[J]. International journal of computer vision, 2004,60(2): 91-110.
[64] HUA B S, TRAN M K, YEUNG S K. Pointwise convolutionalneural networks[C]//Proceedings of the IEEE Conference on Computer Vision andPattern Recognition. Salt Lake City, UT, USA: IEEE, 2018: 984-993.
[65] WU W, QI Z, FUXIN L. Pointconv: Deep convolutionalnetworks on 3d point clouds[C]//Proceedings of the IEEE Conference on ComputerVision and Pattern Recognition. Long Beach, CA, USA: IEEE, 2019: 9621-9630.
[66] THOMAS H, QI C R, DESCHAUD J E, et al. KPConv: Flexibleand Deformable Convolution for Point Clouds[J]. ArXiv preprintarXiv:1904.08889, 2019.
[67] QI C R, LIU W, WU C, et al. Frustum pointnets for 3dobject detection from rgb-d data[C]//Proceedings of the IEEE Conference onComputer Vision and Pattern Recognition. Salt Lake City, UT, USA: IEEE, 2018:918-927.
[68] SHI S, WANG X, LI H. Pointrcnn: 3d object proposalgeneration and detection from point cloud[C]//Proceedings of the IEEEConference on Computer Vision and Pattern Recognition. Long Beach, CA, USA:IEEE, 2019: 770-779.
[69] QI C R, LITANY O, HE K, et al. Deep Hough Voting for 3DObject Detection in Point Clouds[J]. ArXiv preprint arXiv:1904.09664, 2019.
[70] WANG W, YU R, HUANG Q, et al. Sgpn: Similarity groupproposal network for 3d point cloud instance segmentation[C]//Proceedings ofthe IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City,UT, USA: IEEE, 2018: 2569-2578.
[71] YI L, ZHAO W, WANG H, et al. GSPN: Generative ShapeProposal Network for 3D Instance Segmentation in Point Cloud[J]. ArXiv preprintarXiv:1812.03320, 2018.
[72] AOKI Y, GOFORTH H, SRIVATSAN R A, et al. PointNetLK:Robust & efficient point cloud registration using PointNet[C]//Proceedingsof the IEEE Conference on Computer Vision and Pattern Recognition. Long Beach,CA, USA: IEEE, 2019: 7163-7172.
[73] WANG Y, SOLOMON J M. Deep Closest Point: LearningRepresentations for Point Cloud Registration[J]. ArXiv preprintarXiv:1905.03304, 2019.
[74] BRUNA J, ZAREMBA W, SZLAM A, et al. Spectral networksand locally connected networks on graphs[J]. ArXiv preprint arXiv:1312.6203,2013.
[75] DEFFERRARD M, BRESSON X, VANDERGHEYNST P. Convolutionalneural networks on graphs with fast localized spectral filtering[C]//Advancesin neural information processing systems. Barcelona, Spain: MIT Press, 2016:3844-3852.
[76] KIPF T N, WELLING M. Semi-supervised classificationwith graph convolutional networks[J]. ArXiv preprint arXiv:1609.02907, 2016.
[77] VELI?KOVI? P, CUCURULL G, CASANOVA A, et al. Graphattention networks[J]. ArXiv preprint arXiv:1710.10903, 2017.
[78] HAMILTON W, YING Z, LESKOVEC J. Inductiverepresentation learning on large graphs[C]//Advances in Neural InformationProcessing Systems. Long Beach, CA, USA: MIT Press, 2017: 1024-1034.
[79] YI L, SU H, GUO X, et al. Syncspeccnn: Synchronizedspectral cnn for 3d shape segmentation[C]//Proceedings of the IEEE Conferenceon Computer Vision and Pattern Recognition. Honolulu, HI, USA: IEEE, 2017:2282-2290.
[80] WANG C, SAMARI B, SIDDIQI K. Local spectral graphconvolution for point set feature learning[C]//Proceedings of the EuropeanConference on Computer Vision (ECCV). Munich, Germany: Springer, 2018: 52-66.
[81] SIMONOVSKY M, KOMODAKIS N. Dynamic edgeconditionedfilters in convolutional neural networks on graphs[C]//Proceedings of the IEEEConference on Computer Vision and Pattern Recognition. Honolulu, HI, USA: IEEE,2017: 3693-3702.
[82] WANG Y, SUN Y, LIU Z, et al. Dynamic graph CNN forlearning on point clouds[J]. ArXiv preprint arXiv:1801.07829, 2018.
[83] WANG L, HUANG Y, HOU Y, et al. Graph AttentionConvolution for Point Cloud Semantic Segmentation[C]//Proceedings of the IEEEConference on Computer Vision and Pattern Recognition. Long Beach, CA, USA:IEEE, 2019: 10296-10305.
[84] HOU J, DAI A, NIEßNER M. 3D-SIS: 3D Semantic InstanceSegmentation of RGB-D Scans[J]. ArXiv preprint arXiv:1812.07003, 2018.
[85] ARMENI I, SENER O, ZAMIR A R, et al. 3d semanticparsing of large-scale indoor spaces[C]//Proceedings of the IEEE Conference onComputer Vision and Pattern Recognition. Las Vegas, NV, USA: IEEE, 2016:1534-1543.
以上是关于三维点云深度学习与语义理解方法及关键技术的主要内容,如果未能解决你的问题,请参考以下文章