spark:distinct算子实现原理
Posted hejunhong
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了spark:distinct算子实现原理相关的知识,希望对你有一定的参考价值。
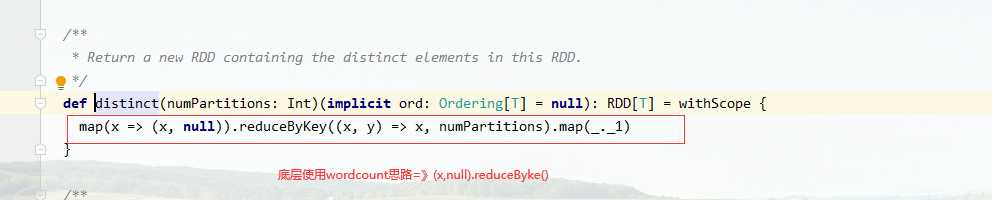
distinct的底层使用reducebykey巧妙实现去重逻辑
//使用reduceByKey或者groupbykey的shuffle去重思想
rdd.map(key=>(key,null)).reduceByKey((key,value)=>key)
.map(_._1)
以上是关于spark:distinct算子实现原理的主要内容,如果未能解决你的问题,请参考以下文章
Spark Distinct算子写入MySql TopN 性能分析