Spark Core学习之常用算子(含经典面试题)
Posted 烟雨蒋楠
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark Core学习之常用算子(含经典面试题)相关的知识,希望对你有一定的参考价值。
目录
union()并集、subtract()差集、intersection()交集
aggregateByKey()按照k进行分区内和分区间逻辑
foldByKey()分区内核分区间具有相同逻辑的aggregateByKey()
takeOrdered(n)返回RDD排序后前n个元素组成的数组
foreach()&foreachPartition遍历RDD中每一个元素
前言
在 Spark Core中,RDD(Resilient Distributed Dataset,弹性分布式数据集) 支持 2 种操作:
1、transformation
从一个已知的 RDD 中创建出来一个新的 RDD 。例如: map就是一个transformation。
2、action
在数据集上计算结束之后, 给驱动程序返回一个值.。例如: reduce就是一个action。
注意:
本文只简单讲述Transformation算子和Action算子,目的是了解其相应的算子如何使用;并不打算深入理解每一个算子的执行过程和逻辑思想。
在 Spark 中几乎所有的transformation操作都是懒执行的(lazy),也就是说transformation操作并不会立即计算他们的结果,而是记住了这个操作。只有当通过一个action来获取结果返回给驱动程序的时候这些转换操作才开始计算。这种设计可以使 Spark 运行起来更加的高效。
默认情况下,你每次在一个 RDD 上运行一个action的时候,前面的每个transformed RDD 都会被重新计算。但是我们可以通过persist (or cache)方法来持久化一个 RDD 在内存中,也可以持久化到磁盘上, 来加快访问速度。
根据 RDD 中数据类型的不同,整体分为 2 种 RDD:
- Value类型
- Key-Value类型(其实就是存了一个二维的元组)
第一部分:Transformation算子
Value类型
map()映射
需求:
创建一个1~4数组的RDD,两个分区,将所有元素*2形成新的RDD。
代码实现:
object TransformationDemo {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setMaster("local[*]")
.setAppName("TransformationDemo_test")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
//3具体业务逻辑
mapTest(sc)
//4.关闭连接
sc.stop()
}
def mapTest(sc: SparkContext): Unit = {
// 3.1 创建一个RDD
val rdd: RDD[Int] = sc.makeRDD(1 to 4,2)
// 3.2 调用map方法,每个元素乘以2
val mapRdd: RDD[Int] = rdd.map(_ * 2)
// 3.3 打印修改后的RDD中数据
mapRdd.collect().foreach(println)
}
}map()操作如图所示:
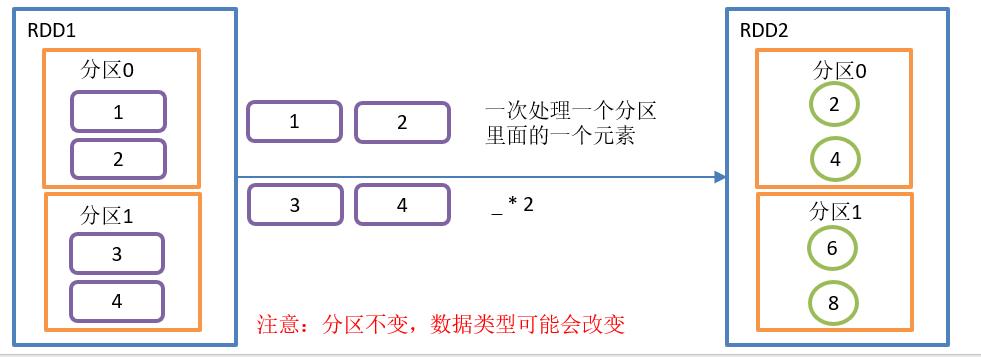
map()函数结构
def map[U: ClassTag](f: T => U): RDD[U] = withScope {
val cleanF = sc.clean(f)
new MapPartitionsRDD[U, T](this, (context, pid, iter) => iter.map(cleanF))
}功能描述
参数f是一个函数,它可以接收一个参数。当某个RDD执行map方法时,会遍历该RDD中的每一个数据项,并依次应用f函数,从而产生一个新的RDD。即,这个新RDD中的每一个元素都是原来RDD中每一个元素依次应用f函数而得到的。
在本例中,f为:_*2
备注:rdd.map(_ * 2)是rdd.map((f: Int) => f * 2)的简写。
mapPartitions()以分区单位执行Map
需求:
创建一个RDD,4个元素,2个分区,使每个元素*2组成新的RDD
代码实现:
object TransformationDemo {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setMaster("local[*]")
.setAppName("TransformationDemo_test")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
//3具体业务逻辑
mapPartitionsTest(sc)
//4.关闭连接
sc.stop()
}
/**
* 创建一个RDD,4个元素,2个分区,使每个元素*2组成新的RDD
* */
def mapPartitionsTest(sc: SparkContext): Unit ={
// 3.1 创建第一个RDD
val rdd: RDD[Int] = sc.makeRDD(1 to 4,2)
// 3.2 需求实现
val value: RDD[Int] = rdd.mapPartitions((data: Iterator[Int]) => data.map((x: Int) => x * 2))
// 3.3 打印
value.foreach(println)
}
}mapPartitions()操作如图所示:

mapPartitions()函数结构:
def mapPartitions[U: ClassTag](
f: Iterator[T] => Iterator[U],
preservesPartitioning: Boolean = false): RDD[U] = withScope {
val cleanedF = sc.clean(f)
new MapPartitionsRDD(
this,
(context: TaskContext, index: Int, iter: Iterator[T]) => cleanedF(iter),
preservesPartitioning)
}功能介绍:
- f函数把每一个分区的数据分别放入到迭代器中,批处理。
- preservesPartitioning:是否保留上游RDD的分区信息,默认false
- Map是一次处理一个元素,而mapPartitions一次处理一个分区数据。
备注:map()和mapPartitions()的区别
- map():每次处理一条数据。
- mapPartitions():每次处理一个分区的数据,这个分区的数据处理完后,原 RDD 中该分区的数据才能释放,可能导致 OOM。
- 开发指导:当内存空间较大的时候建议使用mapPartitions(),以提高处理效率。
mapPartitionsWithIndex()带分区号
需求:
创建一个RDD,使每个元素跟所在分区号形成一个元组,组成一个新的RDD。
代码实现:
object TransformationDemo {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setMaster("local[*]")
.setAppName("TransformationDemo_test")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
//3具体业务逻辑
mapPartitionsWithIndexTest(sc)
//4.关闭连接
sc.stop()
}
/**
* 创建一个RDD,使每个元素跟所在分区号形成一个元组,组成一个新的RDD
* */
def mapPartitionsWithIndexTest(sc: SparkContext): Unit ={
// 3.1 创建第一个RDD
val rdd: RDD[Int] = sc.makeRDD(1 to 4,2)
// 3.2 需求实现
val value: RDD[(Int, Int)] = rdd.mapPartitionsWithIndex((index: Int, item: Iterator[Int]) => {
item.map((f: Int) => (index,f))
})
// 3.3 打印
value.foreach(println)
}
}mapPartitionsWithIndex()操作如图所示:
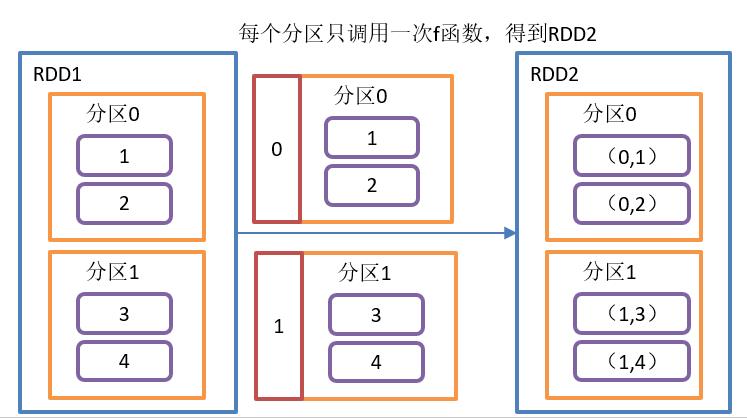
mapPartitionsWithIndex()函数结构:
def mapPartitionsWithIndex[U: ClassTag](
f: (Int, Iterator[T]) => Iterator[U],
preservesPartitioning: Boolean = false): RDD[U] = withScope {
val cleanedF = sc.clean(f)
new MapPartitionsRDD(
this,
(context: TaskContext, index: Int, iter: Iterator[T]) => cleanedF(index, iter),
preservesPartitioning)
}功能介绍:
- f: (Int, Iterator[T]) => Iterator[U]中Int表示分区编号
- 类似于mapPartitions,比mapPartitions多一个整数参数表示分区号
flatMap()压平
需求:
创建一个集合,集合里面存储的还是子集合,把所有子集合中数据取出放入到一个大的集合中。
代码实现:
object TransformationDemo {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setMaster("local[*]")
.setAppName("TransformationDemo_test")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
//3具体业务逻辑
flatMapTest(sc)
//4.关闭连接
sc.stop()
}
/**
* 创建一个集合,集合里面存储的还是子集合,把所有子集合中数据取出放入到一个大的集合中
* */
def flatMapTest(sc: SparkContext): Unit ={
// 3.1 创建第一个RDD
val rdd: RDD[List[Int]] = sc.makeRDD(Array(List(1,2),List(3,4),List(5,6),List(7)),2)
// 3.2 需求实现
val value: RDD[Int] = rdd.flatMap((list: List[Int]) => list)
// 3.3 打印
value.foreach(println)
}
}flatMap操作如图所示:

扩展: 可以通过任务上下文获取分区号。
rdd.foreach((f: List[Int]) => {
// 通过任务上下文获取partitionID
println(TaskContext.getPartitionId() + "---"+ f.mkString(","))
})
flatMap()函数结构:
def flatMap[U: ClassTag](f: T => TraversableOnce[U]): RDD[U] = withScope {
val cleanF = sc.clean(f)
new MapPartitionsRDD[U, T](this, (context, pid, iter) => iter.flatMap(cleanF))
}功能介绍:
- 与map操作类似,将RDD中的每一个元素通过应用f函数依次转换为新的元素,并封装到RDD中。
- 区别:在flatMap操作中,f函数的返回值是一个集合,并且会将每一个该集合中的元素拆分出来放到新的RDD中。并且新的RDD中继承了原RDD中的分区数。
glom()分区转换数组
需求:
创建一个2个分区的RDD,并将每个分区的数据放到一个数组,求出每个分区的最大值。
代码实现:
object TransformationDemo {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setMaster("local[*]")
.setAppName("TransformationDemo_test")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
//3具体业务逻辑
glomTest(sc)
//4.关闭连接
sc.stop()
}
/**
* 创建一个2个分区的RDD,并将每个分区的数据放到一个数组,求出每个分区的最大值
* */
def glomTest(sc: SparkContext): Unit ={
// 3.1 创建第一个RDD
val rdd: RDD[Int] = sc.makeRDD(1 to 4,2)
// 3.2 需求实现
val value: RDD[Int] = rdd.glom().mapPartitions((x: Iterator[Array[Int]]) => x.map((f: Array[Int]) => f.max))
// 3.3 打印
value.foreach((f: Int) => {
println(TaskContext.getPartitionId() + ":" + f)
})
}
}glom()操作如图所示:
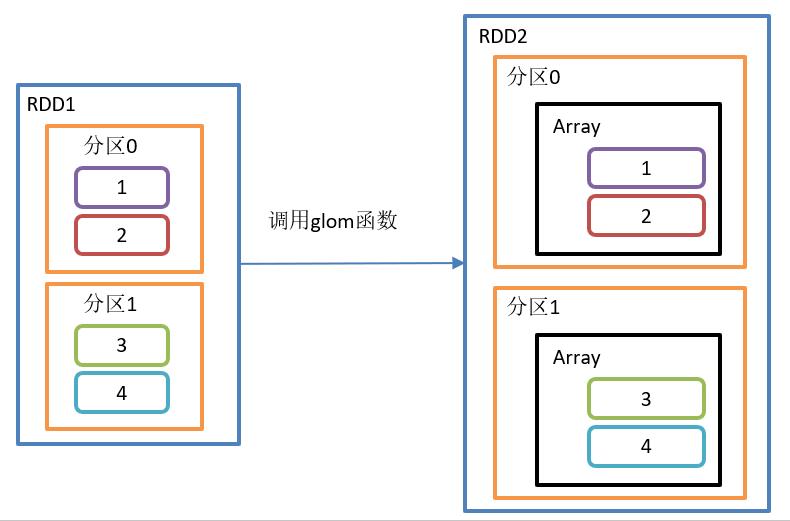
glom()函数结构:
def glom(): RDD[Array[T]] = withScope {
new MapPartitionsRDD[Array[T], T](this, (context, pid, iter) => Iterator(iter.toArray))
}功能介绍:
该操作将RDD中每一个分区变成一个数组,并放置在新的RDD中,数组中元素的类型与原分区中元素类型一致。
groupBy()分组
需求:
创建一个RDD,按照元素模以2的值进行分组。
代码实现:
object TransformationDemo {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setMaster("local[*]")
.setAppName("TransformationDemo_test")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
//3具体业务逻辑
groupByTest(sc)
//4.关闭连接
sc.stop()
}
/**
* 创建一个RDD,按照元素模以2的值进行分组
* */
def groupByTest(sc: SparkContext): Unit ={
// 3.1 创建第一个RDD
val rdd: RDD[Int] = sc.makeRDD(1 to 10,3)
// 3.2 需求实现
val value: RDD[(Int, Iterable[Int])] = rdd.groupBy(_ % 2)
// 3.3 打印
value.foreach(println)
}
}
groupBy()操作如图所示:
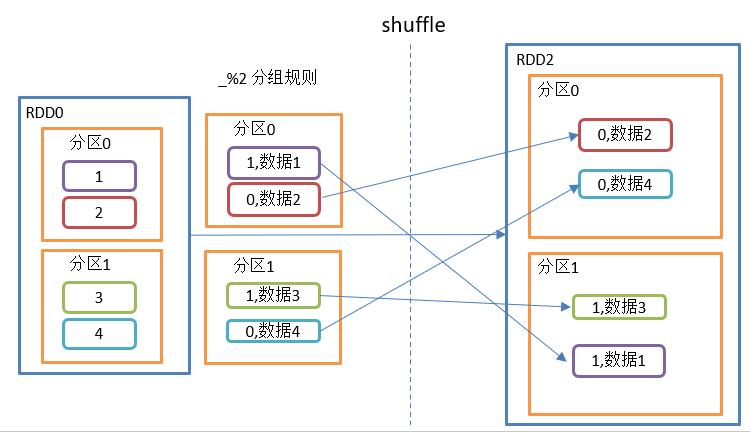
groupBy()函数结构:
def groupBy[K](f: T => K)(implicit kt: ClassTag[K]): RDD[(K, Iterable[T])] = withScope {
groupBy[K](f, defaultPartitioner(this))
}功能介绍:
分组,按照传入函数的返回值进行分组。将相同的key对应的值放入一个迭代器。
备注:
1、groupBy会存在shuffle过程
2、shuffle:将不同的分区数据进行打乱重组的过程
3、shuffle一定会落盘。
扩展:复杂版的wordcount
需求:
有如下的数据,("Hello Scala", 2), ("Hello Spark", 3), ("Hello World", 2),("I Love You",5),("I Miss You",2),("Best wish",9)。其中数字代表出现的个数。求每个单词出现的次数。
代码实现:
def worldCountTest(sc: SparkContext): Unit ={
val rdd: RDD[(String, Int)] = sc.makeRDD(Array(("Hello Scala", 2), ("Hello Spark", 3), ("Hello World", 2), ("I Love You", 5), ("I Miss You", 2), ("Best wish", 9)))
// 方式一:适合scala
/*val value: String = rdd.map {
// 模式匹配
case (str, count) => {
// scala对字符串操作,("Hello Scala" + " ") * 2 = Hello Scala Hello Scala
(str + " ") * count
}
}
.flatMap(_.split(" "))
.map((_, 1))
.reduceByKey(_+_)
.collect()
.mkString(",")
*/
// 方式二:比较通用
val value: String = rdd.flatMap {
case (str, i) => {
str.split(" ").map((word: String) => (word, i))
}
}.reduceByKey(_ + _)
.collect()
.mkString(",")
println(value)
}filter()过滤
需求:
创建一个1到10的RDD,过滤出偶数。
代码实现:
object TransformationDemo {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setMaster("local[*]")
.setAppName("TransformationDemo_test")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
//3具体业务逻辑
filterTest(sc)
//4.关闭连接
sc.stop()
}
/**
* 过滤偶数
* */
def filterTest(sc: SparkContext): Unit = {
// 3.1 创建第一个RDD
val rdd: RDD[Int] = sc.makeRDD(1 to 10, 3)
// 3.2 需求实现
val value: RDD[Int] = rdd.filter(_ % 2 == 0)
// 3.3 打印
value.foreach(println)
}
}filter()操作过程如下:

filter()函数结构:
def filter(f: T => Boolean): RDD[T] = withScope {
val cleanF = sc.clean(f)
new MapPartitionsRDD[T, T](
this,
(context, pid, iter) => iter.filter(cleanF),
preservesPartitioning = true)
}功能介绍:
- 接收一个返回值为布尔类型的函数作为参数。
- 当某个RDD调用filter方法时,会对该RDD中每一个元素应用f函数,如果返回值类型为true,则该元素会被添加到新的RDD中。
sample()采样
需求:
创建一个RDD(1-10),从中选择放回和不放回抽样。
代码实现:
object TransformationDemo {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setMaster("local[*]")
.setAppName("TransformationDemo_test")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
//3具体业务逻辑
sampleTest(sc)
//4.关闭连接
sc.stop()
}
/**
* 随机采样
* */
def sampleTest(sc: SparkContext): Unit ={
// 3.1 创建第一个RDD
val rdd: RDD[Int] = sc.makeRDD(1 to 20, 3)
// 3.2 需求实现
val value: String = rdd.sample(true,0.3,3).collect().mkString(",")
val value2: String = rdd.sample(false,0.3,3).collect().mkString(",")
// 3.3 打印
println("不放回采样结果:" + value2)
println("放回采样结果:" + value)
}
}sample()操作如图所示:

sample()函数结构:
def sample(
withReplacement: Boolean,
fraction: Double,
seed: Long = Utils.random.nextLong): RDD[T] = {
......
}功能介绍:
- 从大量的数据中采样
- withReplacement: Boolean: 抽出的数据是否放回
- fraction: Double:
- 当withReplacement=false时:选择每个元素的概率;取值一定是[0,1] ;底层使用泊松分布。
- 当withReplacement=true时:选择每个元素的期望次数; 取值必须大于等于0,底层使用伯努利采样。
- seed: Long: 指定随机数生成器种子
备注:
1、 该函数随机采样是伪随机,因为传入的随机种子是一样的,计算结果当然一样。
distinct()去重
需求:
对如下的数据去重:3,2,9,1,2,1,5,2,9,6,1
代码实现:
object TransformationDemo {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setMaster("local[*]")
.setAppName("TransformationDemo_test")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
//3具体业务逻辑
distinctTest(sc)
//4.关闭连接
sc.stop()
}
/**
* 数据去重
* */
def distinctTest(sc: SparkContext): Unit = {
// 3.1 创建第一个RDD
val rdd: RDD[Int] = sc.makeRDD(List(3,2,9,1,2,1,5,2,9,6,1))
// 3.2 需求实现
val value: RDD[Int] = rdd.distinct()
// 3.3 打印
value.foreach(println)
}
}distinct()操作如图所示:
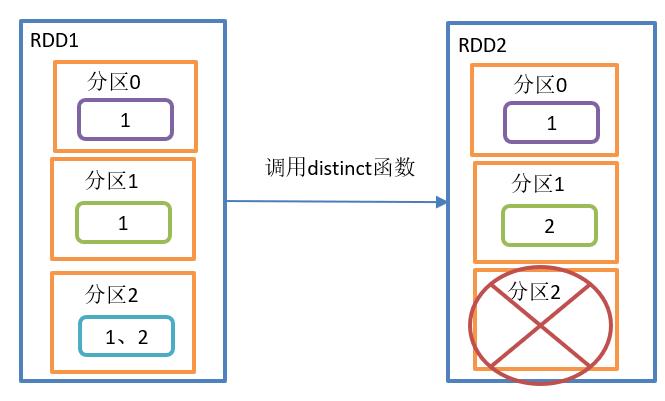
distinct()函数结构:
def distinct(): RDD[T] = withScope {
distinct(partitions.length)
}def distinct(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T] = withScope {
map(x => (x, null)).reduceByKey((x, y) => x, numPartitions).map(_._1)
}功能介绍:
对内部的元素去重,并将去重后的元素放到新的RDD中。
备注:
1、distinct()用分布式的方式去重比HashSet集合方式不容易OOM.
2、默认情况下,distinct会生成与原RDD分区个数一致的分区数,当然也可以指定分区数。
coalesce()重新分区
需求:
1、将4个分区的RDD合并成两个分区的RDD
2、将三个分区的RDD合并成两个分区的RDD
代码实现:
object TransformationDemo {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setMaster("local[*]")
.setAppName("TransformationDemo_test")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
//3具体业务逻辑
coalesceTest(sc)
//4.关闭连接
sc.stop()
}
/**
* coalesce重分区
* */
def coalesceTest(sc: SparkContext): Unit = {
// 3.1 创建第一个RDD
val rdd: RDD[Int] = sc.makeRDD(1 to 4,4)
val rdd2: RDD[Int] = sc.makeRDD(1 to 4,3)
// 3.2 需求实现
val value1: Array[(Int, Int)] = rdd.coalesce(2).map((TaskContext.getPartitionId(),_)).collect()
val value2: Array[(Int, Int)] = rdd2.coalesce(2).map((TaskContext.getPartitionId(),_)).collect()
// 3.3 打印
println("value1:" + value1.mkString(","))
println("value2:" + value2.mkString(","))
}
}coalesce()操作如图所示:

coalesce()函数结构:
def coalesce(numPartitions: Int, shuffle: Boolean = false,
partitionCoalescer: Option[PartitionCoalescer] = Option.empty)
(implicit ord: Ordering[T] = null)
: RDD[T] = withScope {......
}
功能介绍:
- 缩减分区数,用于大数据集过滤后,提高小数据集的执行效率。
- shuffle默认为false,则该操作会将分区数较多的原始RDD向分区数比较少的目标RDD,进行转换。
- shuffle:
- true: 进行shuffle,此时目标分区数可以大于可以小于原分区数。即:可以缩小和扩大原分区。
- false:不进行shuffle,此时目标分区数只能小于原分区数;当大于时,分区数不生效。即:只能缩小或等于原分区。
备注:
1、shuffle原理: 将数据打散,然后重新组合。
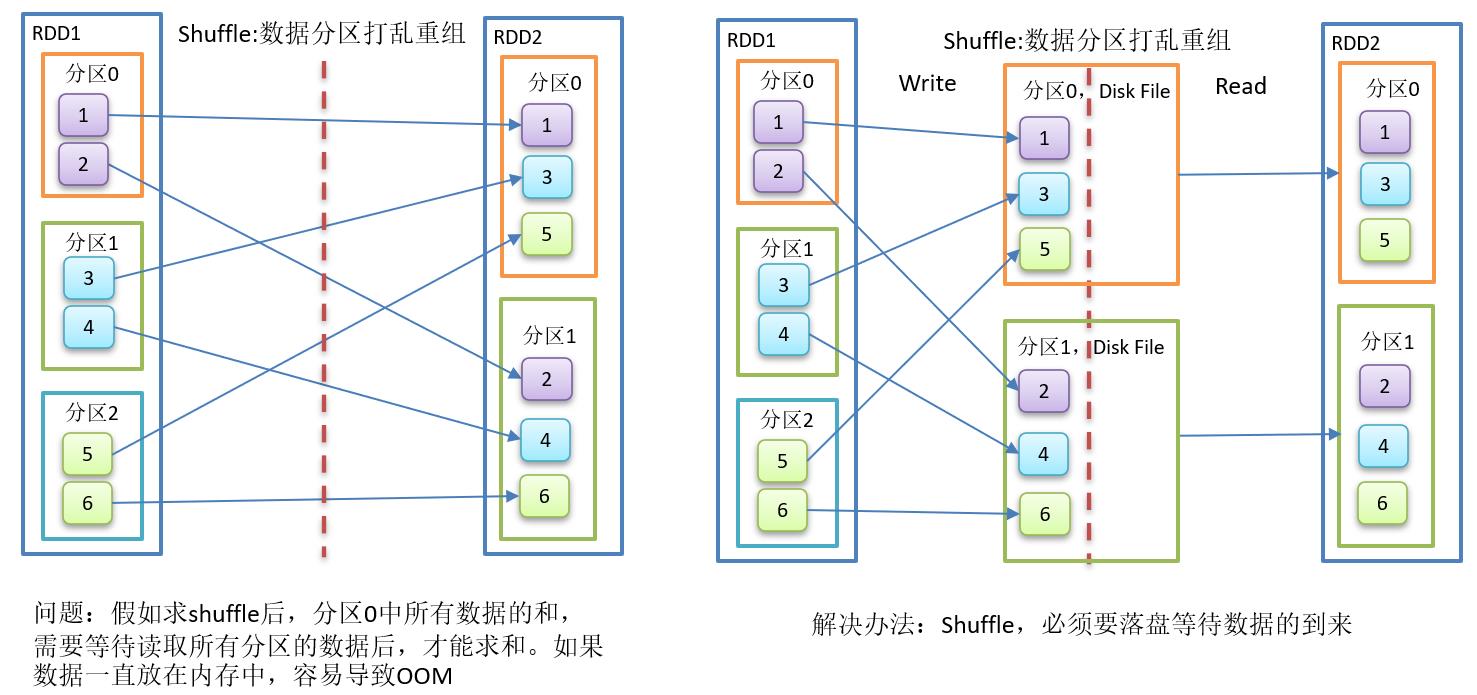
2、具体shuffle过程,读者可以参考“彻底搞懂spark的shuffle过程”。
reparation()重新分区(执行Shuffle)
需求:
创建一个4个分区的RDD,对其重新分区
代码实现:
object TransformationDemo {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setMaster("local[*]")
.setAppName("TransformationDemo_test")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
//3具体业务逻辑
repartitionTest(sc)
//4.关闭连接
sc.stop()
}
/**
* repartition重分区
* */
def repartitionTest(sc: SparkContext): Unit = {
// 3.1 创建第一个RDD
val rdd: RDD[Int] = sc.makeRDD(1 to 10,4)
// 3.2 需求实现
val value1: Array[(Int, Int)] = rdd.repartition(2).map((TaskContext.getPartitionId(),_)).collect()
val value2: Array[(Int, Int)] = rdd.repartition(5).map((TaskContext.getPartitionId(),_)).collect()
// 3.3 打印
println("value1:" + value1.mkString(","))
println("value2:" + value2.mkString(","))
}
}reparation()操作如图所示:

reparation()函数结构:
def repartition(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T] = withScope {
coalesce(numPartitions, shuffle = true)
}功能介绍:
- 该操作内部其实执行的是coalesce操作,参数shuffle的默认值为true。
- 无论是将分区数多的RDD转换为分区数少的RDD,还是将分区数少的RDD转换为分区数多的RDD,repartition操作都可以完成,因为无论如何都会经shuffle过程。
备注: coalesce与reparation的区别
- coalesce重新分区,可以选择是否进行shuffle过程。由参数shuffle: Boolean = false/true决定。
- repartition实际上是调用的coalesce,进行shuffle。
- 如果是减少分区, 尽量避免 shuffle,使用coalesce完成。
- 绝大多数情况下,减少分区使用coalesce,增加分区使用reparation。
sortBy()排序
需求:
创建一个RDD,按照不同的规则进行排序。
- 按照数字大小升序排序
- 按照数字大小降序排序
- 按照模以5的余数降序排序
- 二元组,则先按照第一个元素升序,如果第一个元素相同,在按照第二个元素降序
代码实现:
object TransformationDemo {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setMaster("local[*]")
.setAppName("TransformationDemo_test")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
//3具体业务逻辑
sortByTest(sc)
//4.关闭连接
sc.stop()
}
/**
* sortBy排序
* */
def sortByTest(sc: SparkContext): Unit = {
// 3.1 创建第一个RDD
val rdd: RDD[Int] = sc.makeRDD(List(3,16,5,8,2,10,9,1,7,6))
// 3.2 需求实现
// 升序
val value1: String = rdd.sortBy((num: Int) => num).collect().mkString(",")
// 降序
val value2: String = rdd.sortBy((num: Int) => num,false).collect().mkString(",")
// 按照%5排序
val value3: String = rdd.sortBy((num: Int) => num % 5,false).collect().mkString(",")
// 先按照第一个元素升序,如果第一个元素相同,在按照第二个元素降序
val value4: String = rdd2.sortBy((x: (Int, Int)) => (x._1,-x._2)).collect().mkString(",")
// 3.3 打印
println("value1:" + value1)
println("value2:" + value2)
println("value3:" + value3)
println("value4:" + value4)
}
}sortBy()操作如图所示:
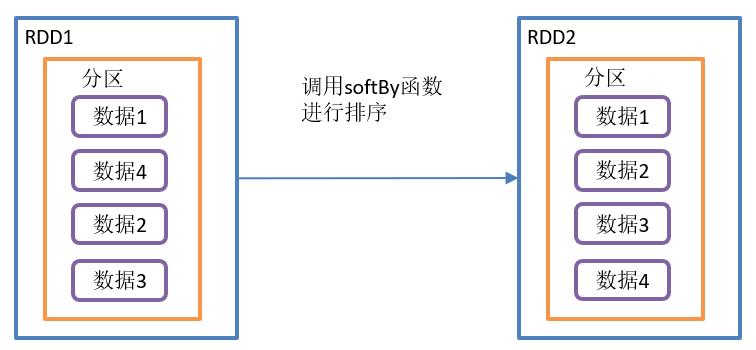
sortBy()函数结构:
def sortBy[K](
f: (T) => K,
ascending: Boolean = true,
numPartitions: Int = this.partitions.length)
(implicit ord: Ordering[K], ctag: ClassTag[K]): RDD[T] = withScope {
this.keyBy[K](f)
.sortByKey(ascending, numPartitions)
.values
}功能介绍:
- 该操作用于排序数据。
- 在排序之前,可以将数据通过f函数进行处理,之后按照f函数处理的结果进行排序,默认为正序排列。
- 默认情况下,排序后新产生的RDD的分区数与原RDD的分区数一致。
- 可以通过numPartitions参数调整目标分区数。
pipe()调用脚本
需求:
编写一个脚本,使用管道将脚本作用于RDD上。
代码实现:
# 编写一个脚本,并增加执行权限
[root@node001 spark]$ vim pipe.sh
#!/bin/sh
echo "Start"
while read LINE; do
echo ">>>"${LINE}
done
[root@node001 spark]$ chmod 777 pipe.sh
# 创建一个只有一个分区的RDD
scala> val rdd = sc.makeRDD (List("hi","Hello","how","are","you"),1)
# 将脚本作用该RDD并打印
scala> rdd.pipe("/opt/module/spark/pipe.sh").collect()
res18: Array[String] = Array(Start, >>>hi, >>>Hello, >>>how, >>>are, >>>you)
#创建一个有两个分区的RDD
scala> val rdd = sc.makeRDD(List("hi","Hello","how","are","you"),2)
# 将脚本作用该RDD并打印
scala> rdd.pipe("/opt/module/spark/pipe.sh").collect()
res19: Array[String] = Array(Start, >>>hi, >>>Hello, Start, >>>how, >>>are, >>>you)pipe()操作如图所示:

pipe()函数结构:
def pipe(command: String): RDD[String] = withScope {
// Similar to Runtime.exec(), if we are given a single string, split it into words
// using a standard StringTokenizer (i.e. by spaces)
pipe(PipedRDD.tokenize(command))
}功能介绍:
- 管道,针对每个分区,都调用一次shell脚本,返回输出的RDD
脚本要放在 worker 节点可以访问到的位置
每个分区执行一次脚本, 但是每个元素算是标准输入中的一行
双Value类型交互
双Value类型的交互常用的算子是数学中的并集、交集合差集。
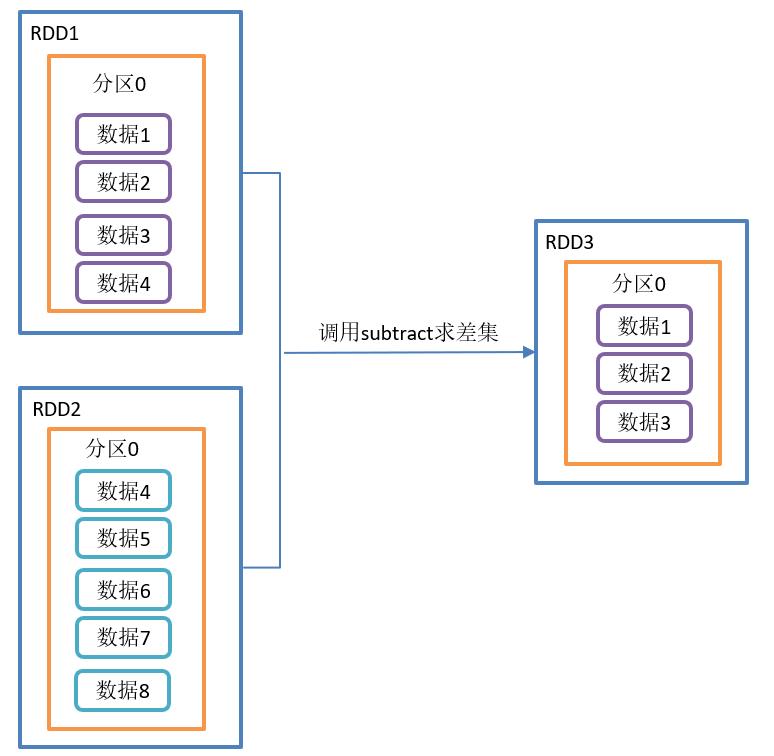
union()并集、subtract()差集、intersection()交集
需求:
创建两个RDD,求并集、交集、差集
代码实现:
object TransformationDemo {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setMaster("local[*]")
.setAppName("TransformationDemo_test")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
//3具体业务逻辑
aggTest(sc)
//4.关闭连接
sc.stop()
}
/**
* 求并集、交集、差集
* */
def aggTest(sc: SparkContext): Unit ={
// 3.1 创建第一个RDD
val rdd1: RDD[Int] = sc.makeRDD (1 to 6)
val rdd2: RDD[Int] = sc.makeRDD (4 to 10)
// 3.2 需求实现
// 并集
val value1: Array[Int] = rdd1.union(rdd2).collect()
// 差集
val value2: Array[Int] = rdd1.subtract(rdd2).collect()
// 交集
val value3: Array[Int] = rdd1.intersection(rdd2).collect()
// 3.3 打印
println("并集:" + value1.mkString(","))
println("差集:" + value2.mkString(","))
println("交集:" + value3.mkString(","))
}
}union()并集操作如图所示:

subtract()差集操作如图所示:
intersection()交集操作如图所示:

union()函数结构:
def union(other: RDD[T]): RDD[T] = withScope {
sc.union(this, other)
}subtract()函数结构:
def subtract(other: RDD[T]): RDD[T] = withScope {
subtract(other, partitioner.getOrElse(new HashPartitioner(partitions.length)))
}intersection()函数结构:
def intersection(other: RDD[T]): RDD[T] = withScope {
this.map(v => (v, null)).cogroup(other.map(v => (v, null)))
.filter { case (_, (leftGroup, rightGroup)) => leftGroup.nonEmpty && rightGroup.nonEmpty }
.keys
}功能介绍:
- 并集:对源RDD和参数RDD求并集后返回一个新的RDD
- 差集:计算差的一种函数,去除两个RDD中相同元素,不同的RDD将保留下来
交集:对源RDD和参数RDD求交集后返回一个新的RDD
zip()拉链
需求:
创建两个RDD,并将两个RDD组合到一起形成一个(k,v)RDD
代码实现:
object TransformationDemo {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setMaster("local[*]")
.setAppName("TransformationDemo_test")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
//3具体业务逻辑
zipTest(sc)
//4.关闭连接
sc.stop()
}
/**
* zip拉链
* */
def zipTest(sc: SparkContext): Unit ={
// 3.1 创建第一个RDD
val rdd1: RDD[Int] = sc.makeRDD (1 to 3,2)
val rdd2: RDD[String] = sc.makeRDD (List("a","b","c"),2)
// 3.2 需求实现
val value: Array[(String, Int)] = rdd2.zip(rdd1).collect()
// 3.3 打印
println(value.mkString(","))
}
}zip()操作如图所示:
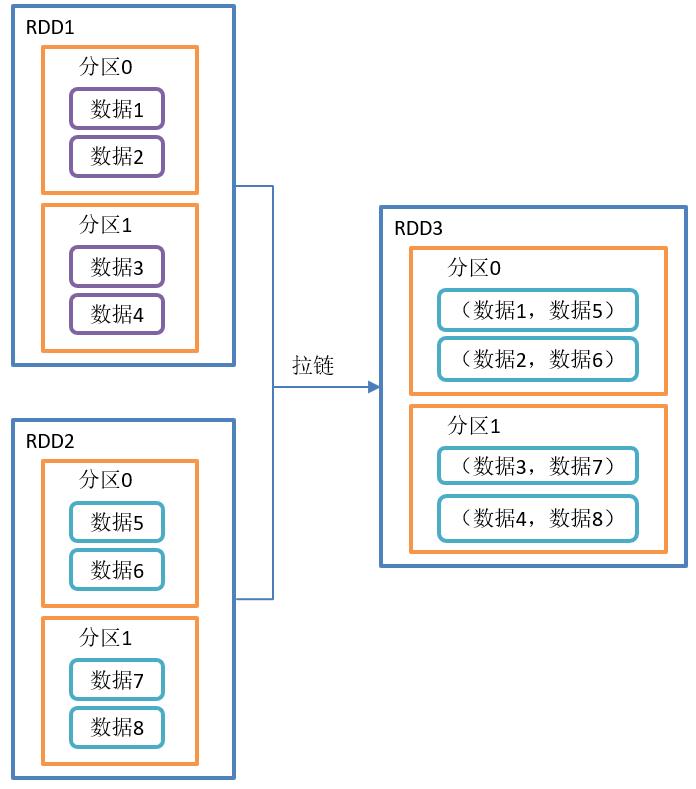
zip()函数结构:
def zip[U: ClassTag](other: RDD[U]): RDD[(T, U)] = withScope {
......
}
功能介绍:
- 该操作可以将两个RDD中的元素,以键值对的形式进行合并。其中,键值对中的Key为第1个RDD中的元素,Value为第2个RDD中的元素。
- 将两个RDD组合成Key/Value形式的RDD,这里默认两个RDD的partition数量以及元素数量都相同,否则会抛出异常。
Key-Value类型
partitionBy()按照k重新分区
需求:
创建一个5个分区的RDD,对其重新分区。
代码实现:
object TransformationDemo {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setMaster("local[*]")
.setAppName("TransformationDemo_test")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
//3具体业务逻辑
partitionByKeyTest(sc)
//4.关闭连接
sc.stop()
}
/**
* partitionByKey:根据key重新分区
* */
def partitionByKeyTest(sc: SparkContext): Unit ={
val tuples: List[(Int, String)] = List((1, "a"), (2, "b"), (3, "c"), (4, "d"), (1, "aa"), (1, "bb"), (3, "cc"), (4, "dd")
,(1,"aaa"),(2,"bbb"),(3,"ccc"),(4,"ddd"))
// 3.1 创建第一个RDD
val rdd: RDD[(Int, String)] = sc.makeRDD (tuples,5)
rdd.cache()
println("-------分区前-------")
val value1: String = rdd.mapPartitionsWithIndex((index: Int, data: Iterator[(Int, String)]) => {
data.map((index,_))
}).collect().mkString("\\t")
println(value1)
// 3.2 需求实现
val value: RDD[(Int, String)] = rdd.partitionBy(new HashPartitioner(3))
// 3.3 打印
println("-------分区后-------")
val value2: String = value.mapPartitionsWithIndex((index: Int, data: Iterator[(Int, String)]) => {
data.map((index,_))
}).collect().mkString("\\t")
println(value2)
}
}partitionBy()操作如图所示:

partitionBy()函数结构:
def partitionBy(partitioner: Partitioner): RDD[(K, V)] = self.withScope {
if (keyClass.isArray && partitioner.isInstanceOf[HashPartitioner]) {
throw new SparkException("HashPartitioner cannot partition array keys.")
}
if (self.partitioner == Some(partitioner)) {
self
} else {
new ShuffledRDD[K, V, V](self, partitioner)
}
}功能介绍:
- 将RDD[K,V]中的K按照指定Partitioner重新进行分区;会产生Shuffle过程。
- 如果原有的partionRDD和现有的partionRDD是一致的话就不进行分区,否则进行分区。
- 默认的分区器是HashPartitioner。
备注:
1、HashPartitioner的原理是:
- 依据RDD中key值的hashCode的值将数据取模后得到该key值对应的下一个RDD的分区id值,
- 支持key值为null的情况,当key为null的时候,返回0;
- 该分区器基本上适合所有RDD数据类型的数据进行分区操作。
2、详细的分区器原理,请参考:[Spark] - HashPartitioner & RangePartitioner 区别
注意:
1、由于JAVA中数组的hashCode是基于数组对象本身的,不是基于数组内容的,所以如果RDD的key是数组类型,那么可能导致数据内容一致的数据key没法分配到同一个RDD分区中。(未测)
2、在scala中,如果RDD的key是Array数组类型,编译不通过。Exception in thread "main" org.apache.spark.SparkException: HashPartitioner cannot partition array keys.
这个时候最好自定义数据分区器,采用数组内容进行分区或者将数组的内容转换为集合。
自定义分区
class MyPartitioner(num: Int) extends Partitioner {
// 设置的分区数
override def numPartitions: Int = num// 具体分区逻辑
override def getPartition(key: Any): Int = {if (key.isInstanceOf[Int]) {
val keyInt: Int = key.asInstanceOf[Int]
if (keyInt % 2 == 0)
0
else
1
}else{
0
}
}
}
reduceByKey()按照k进行聚合v
需求:
统计单词出现次数(wordCount)。
代码实现:
为了增加难度,本次实验给字符串加了一些中英文的字符。
object TransformationDemo {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setMaster("local[*]")
.setAppName("TransformationDemo_test")
以上是关于Spark Core学习之常用算子(含经典面试题)的主要内容,如果未能解决你的问题,请参考以下文章