MNIST实例-Tensorflow 初体验
Posted chenjieyouge
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MNIST实例-Tensorflow 初体验相关的知识,希望对你有一定的参考价值。
目的还是熟悉这种 tensorflow 框架的基本流程, 即如何导包, 反正我神经网络相关的一些经典理论, BP推导呀, 卷积神经网络呀, 递归神经网络这些的数学原理, 我已经基本推导一遍了, 已基本算是从根源上来认识问题, 现在就练练导包而已, 调参才是最要的, 会使用工具就行嘛.
最近的又是一些小工具的活, Python 处理 Excel, 通过 .com 的方式哦, 不是什么 pandas 之类的, 当然计算逻辑用它, 但连接, 格式啥的还是 .com , 文档就是 VBA 文档, 用 xlwings 这个封装库, 是我在2018年末, 发现的, 感觉贼好用 了, 相对于其他. 主要是不想弄 RPA, 太痛苦了, 宁愿失业, 也不会学习的这玩意. 然后, 看到 4月, 用 帆软report 搞报表, 共查看修改了 4500多次....遥遥领先其他同事, 明星开发狮, 就是我. 然而还是搞不定他们的需求... 当然也可以看出, 这些国产软件, 未来发展空间, 还有很大很大 ...
手写数字识别
这就是深度学习的 "hello, world!" .
现在是越来越喜欢这类, "hello, world" 的腔调. 比如, 编程语言的第一个程序是, 打印, hello, world; ML 算法的 hello, world 是 K 近邻算法; BI 报表开发的 hello, world 是 sql; 数据分析的hello, world 是, code + sql + math 这一个就不能少, 尤其是编程, 不会一门编程语言, 连基本的数据都处理不了, 何谈分析.. 不扯了.
hello, world! 人生若只如初见!
图片类别呢, 数字嘛, 就可以用 0, 1, 2 ... 9 来代替, 作为图片真实值 y.
给每张图片放缩固定大小, 比如 (244 x 244) 这样的像素点. 这里是灰度图像, 即存储上是一个 二维矩阵 (244 x 244).
MNIST: 该手写数据集包含了 0~9 共 10种数字的手写图片, 每种数子有 7000张图, 共 70000张, 其中 60000张作为训练数据, 1万张作为测试数据.
简化一点, 将每张图放缩到 28x28, 就保留灰度信息. 看一波, 图片该如何表示. 一张图片, 包含了 h 行, w 列, 每个位置保存了像素(Pixel) 值 (0~255) . 如是彩色照片,每个像素点包含 R, G, B 的值, 需要一个 [h, w, 3] 形状的 3维数组表示. . 灰度图, 就只需要 一个数字, 形状为 [h, w] 的二维矩阵, 或者 [h, w, 1] 的张梁也行.
获取MNIST 数据集
import os
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers, optimizers, datasets
# 加载数据集, 不运行了, 重在理解过程, 运行太慢了也.
(x_train, y_train), (x_test, y_test) = datasets.mnist.load_data()
# 转换浮点为张量, 并缩放到 [-1, 1]
x_trian = 2 * tf.convert_to_tensor(x_trian, dtype=tf.float32) / 255 -1
# 将 y_train 标签值, 转为整形张量
y_train = tf.convert_to_tensor(y_train, dtype=tf.int32)
# 再对其进行 one-hot 编码
y_trian = tf.one_hot(y_train)
# print(x_train.shape, y_train.shape)
# 构建数据集对象, 并设置为批量 batch 训练
train_dat = tf.data.from_tensor_slices((x_trian, y_train))
train_dat = train_dat.batch(512) # 每次训练多少张 [b,h,w]
每个 tuple 第一个元素是训练数据 X, 第二值是其标签值 y. X 的大小 shape 为 (60000, 28, 28) 表示 6万个样本, 每个样本由 28行, 28列 的 矩阵组成, 灰度图像没有 RGB 通道.
每个值是在 0 - 255 之间, 表示强度. 而 y_train 的大小为 (60000), 每个值在 0-9 的 int.
在预处理阶段, 把值进行了 归一化到 [0, 1] 区间, 再缩放到 [-1, 1] , 目的是为了, 训练更好.
在训练阶段, 套路是通用的, 一次可进行多张图片的训练 即 batch. 一张图片用 [row, col] 来表示一张灰度图片, 则多张, 在前面添加一个维度, 使用形状为 [batch, row, col] ; 彩色则再加一个通道数据, 彩色为 3 通道 channel 即表示为 [batch, row, col, channel] 这样的张量表示.
# 批量训练 api
train_dat.batch(512) # 每次训练多少张 [b,h,w]
模型搭建
用神经网络呀. 神经网络的前向, 和误差后向传播 BP 算法原理的数学推导, 我已经推导了 2遍了, 关于核心四大公式推导啥的, 这就不拓展了, 推导即, 多元函数求偏导, 注意链式法则的应用, 用梯度, 作为 "误差" 进行收敛判断, 懂了就蛮简单的, 从数学上来看.
BP算法推导 (上) : https://www.cnblogs.com/chenjieyouge/p/12233535.html
BP算法推导 (下): https://www.cnblogs.com/chenjieyouge/p/12234705.html
代码这块, 首先要解决是 输入维度问题. 神经网络的输入层, 要求是一个向量嘛****, 而咱这里的, 图片存储则是多维的矩阵, 比如一张灰度图片的 shape 是 [row, col] , 多张是 [batch, row, col] 等多维矩阵, 肯定是不行的, 方案是将每张图片特征 [row, col] 铺平 flatten 为 [row * col] 长度的向量 **. 这样一个拉伸的操作.
# 拉伸的示意图哈
[
[1, 2, 3],
[4, 5, 6], ==> flatten ==> [1, 2, 3, 4, 5, 6, 7, 8, 9]
[7, 8, 9]
]
对于 y 即类别 0-9 的数字, 当然是采用 one_hot 编码的方式了. 为了避免稀疏 Sparse, 浪费内存空间嘛, 很多没用的 0, 存的时候, 其实是采用 数字编码 的.
这里还是要演示下 one_hot 编码 api, 即: tf.one_hot( )
# one_hot 编码
# 数字编码采样 5 个样本标签
y = tf.constant([0, 1, 2, 3, 4])
# depth 指定类别总数为 10
tf.one_hot(y, depth=10)
<tf.Tensor: id=5, shape=(5, 10), dtype=float32, numpy=
array([[1., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 1., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 1., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 1., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 1., 0., 0., 0., 0., 0.]], dtype=float32)>
对于将要构建的神经网络的 输入, 输出层:
-
输入: 对于咱的 MNIST, 输入的每张图片是 [28, 28] , 拉伸为 向量 (x in R^{784})
-
输入: y 进行 One_hot 后, 长度为 10 的 0-1 构成的 稀疏向量 (x in {0, 1} ^{10})
-
模型: 多输入, 多输出 (batch) 的线性模型 (o = W^Tx + b)
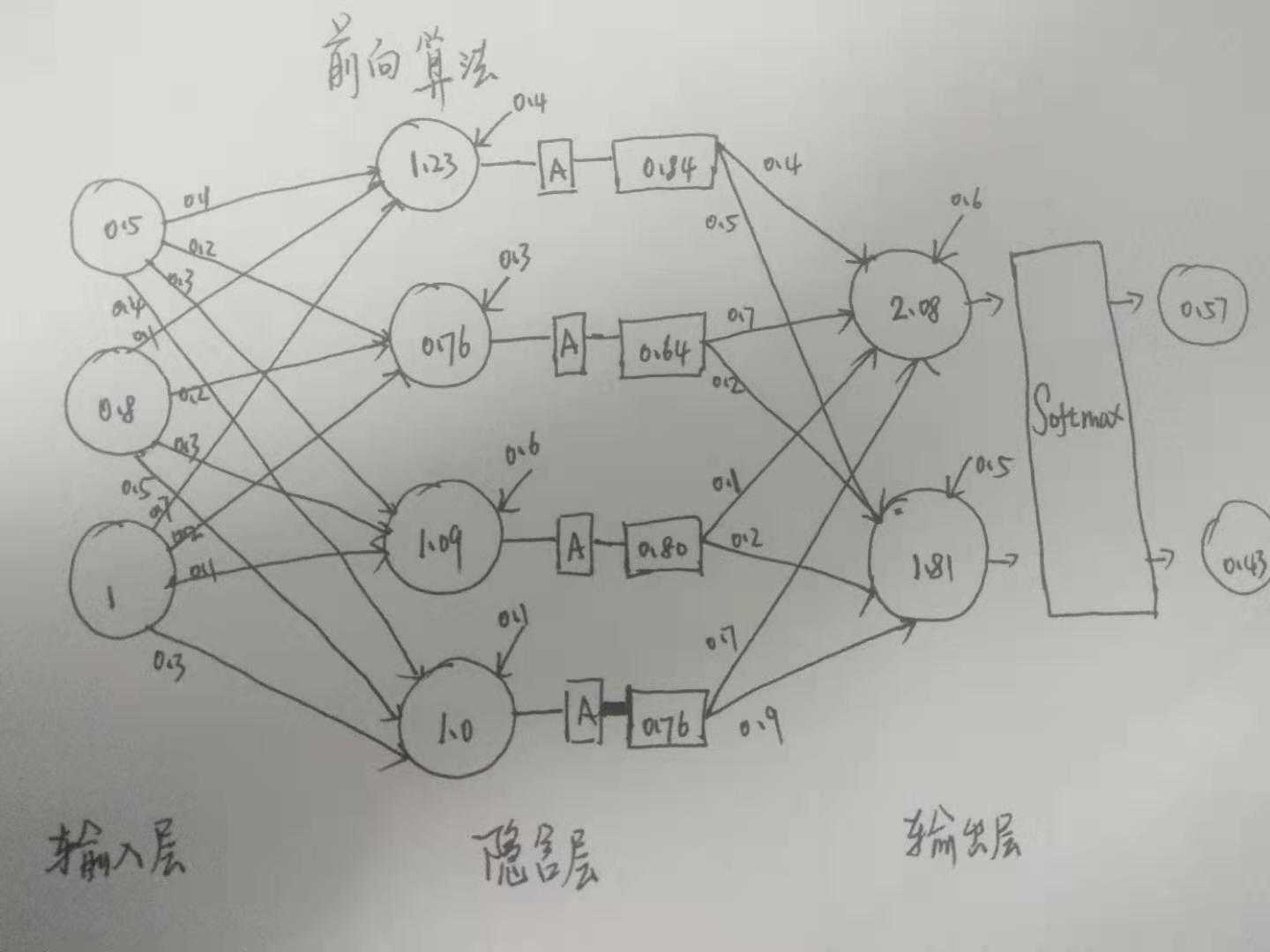
模型的输出, 即预测值 (o) , 希望 预测值 越接近真实标签 y 越好, 采用 BP 误差向后传递 的方式来训练网络, 其实就是不断求偏导数, 求梯度进行动态调整而已. 把每一次输入的线性变化 (加法和数乘) 成为一层 网络.
线性: 其实就是 加法 和 数乘. 神经网络, 线性代数啥的, 都基于此.
假设有一天, 我们发现, 世界是非线性的, 那, 世界大概率就会崩塌了. 至少, ML 就先崩塌, 基本假设不成立了, 还玩个锤子呦.
说得有点偏哲学和偷换概念了. 从数学公式来看, 非线性其实再 ML 中也是占据很大比例的. 咱都知道, 网络中有一个激活层, 非线性的, 即把 线性变换的值, 给变换的 [-1, 1]. 比较常用的 非线性激活函数.
-
sigmoid 函数: (frac{1}{1+e^{-x}})
-
RELU 函数: x if x >= 0 else 0
sigmoid 函数在 逻辑回归中, 作为一个概率值来测算, 还是很常用的, 通常推导的核心也是 sigmoid + bayes 公式来整的. 而 RELU 呢, 清零负输入, 简单且计算梯度方便, 训练稳定, 非常实用哦.
优化方法
神经网络的参数训练, 大多是BP 算法嘛, 数学上即, 多元复合函数求偏导 (梯度), 注意链式法则的应用.
梯度下降, 梯度更新这块, 核心就是一直在求梯度, 求梯度, 如果网络变了, 数学上, 就不好推导公式了, 对应到代码层面, 就只能通过, 导数的定义来进行逼近了.
(f‘(x) = lim_{Delta x - 0} frac {f(x + Delta x) - f(x)}{Delta x})
这尼玛, 就不好写代码了, 当数学上不推导公式的时候, 简直让我崩溃, 之前我搞过一把. 因此, 现在才就乖乖地来学习框架导包了. 框架集成了 自动求导 (Autograd) 技术 , 这简直太厉害了趴~, 它大致原理是, 在计算每层输出和损失函数的过程中, 会构建一个图模型, 并自动完成任意参数的 求偏导数 (frac {partial L} {partial heta}) 的计算. 而我导包, 唯一要做的事, 搭建出网络结构, 等它自己进行梯度更新.
话说, 学会导包, 静静等待它自动求导, 这难道不香嘛?
...
当然前提是能推导所有的数学公式, 不然你根本, 体验不到快乐, 闻不到香哦.
流程初体验
大致就这样的一个套路, 导包而已, 不要太期待, 学会查文档去官网, 依葫芦画瓢就行啦.
# step_01: 网络搭建
# 第一层网络, 设置输出节点数为 256, 激活函数类型为 RELU
layers.Dense(256, activation=‘relu‘)
# 用 Sequential 容器封装3个网络层, 前层输出作为后层输入 (前向)
model = keras.Sequential([
# 最简易的 3层模型
layers.Dense(256, activation=‘relu‘), # 隐含层 01
layers.Dense(128, activation=‘relu‘), # 隐含层 02
layers.Dense(10) # 输出层, 节点数为 10
])
# step_02: 模型训练
# 构建梯度记录的环境
with tf.GradientTape() as tape:
# 拉伸: flatten: [b, 28, 28] => [b, 784]
x = tf.reshape(x_train, (-1, 28*28))
# 得到输出: [b, 784] => [b, 10]
out_vec = model(x)
y_onehot = tf.one_hot(y, depth=10)
# 计算误差平方和, 和平均误差 MSE
loss = tf.square(out_vec - y_onehot)
loss = tf.reduce_sum(loss) / x.shape[0]
# 计算当前参数梯度 W_i, bj 即 w1, w2, w3, b1, b2, b3
grads = tape.gradient(loss, model.trainable_variables)
# 梯度更新 w‘ = w = lr * grad
optimizers.apply_gradients(zip(grads, model.trainable_variables))
...
等循环迭代多次后呢, 当各节点梯度逐渐为 0 的时候, 也就收敛了嘛, 停止训练, 得出模型参数. 每次迭代称为一个 Epoch. 三层模型还是很强的哦.
小结
- 回顾了一波 ML 的基本概念和 DL 的基本套路流程, 还是要结合数学原理来看, 就非常清晰.
- 神经网络 BP 算法推导并理解, 才能更好去理解 这些框架如 TF , PyTorch 等, 代码的意义
- 体验一下导包套路, 获取数据 - 特征工程, 构建网络, 模型训练, 计算梯度, 梯度更新 .. Epoch ..这些流程操作.
以上是关于MNIST实例-Tensorflow 初体验的主要内容,如果未能解决你的问题,请参考以下文章
URL fetch failure on https://storage.googleapis.com/tensorflow/tf-keras-datasets/mnist.npz: None(代码片